Boosting,SVM,Random Forest

统计学习方法——CART, Bagging, Random Forest, Boosting
本文从统计学角度讲解了CART(Classification And Regression Tree), Bagging(bootstrap aggregation), Random Forest Boosting四种分类器的特点与分类方法,参考材料为密歇根大学Ji Zhu的pdf与组会上王博的讲解。
CART(Classification And Regression Tree)
Breiman, Friedman, Olshen & Stone (1984), Quinlan (1993)
思想:递归地将输入空间分割成矩形
优点:可以进行变量选择,可以克服missing data,可以处理混合预测
缺点:不稳定
example:
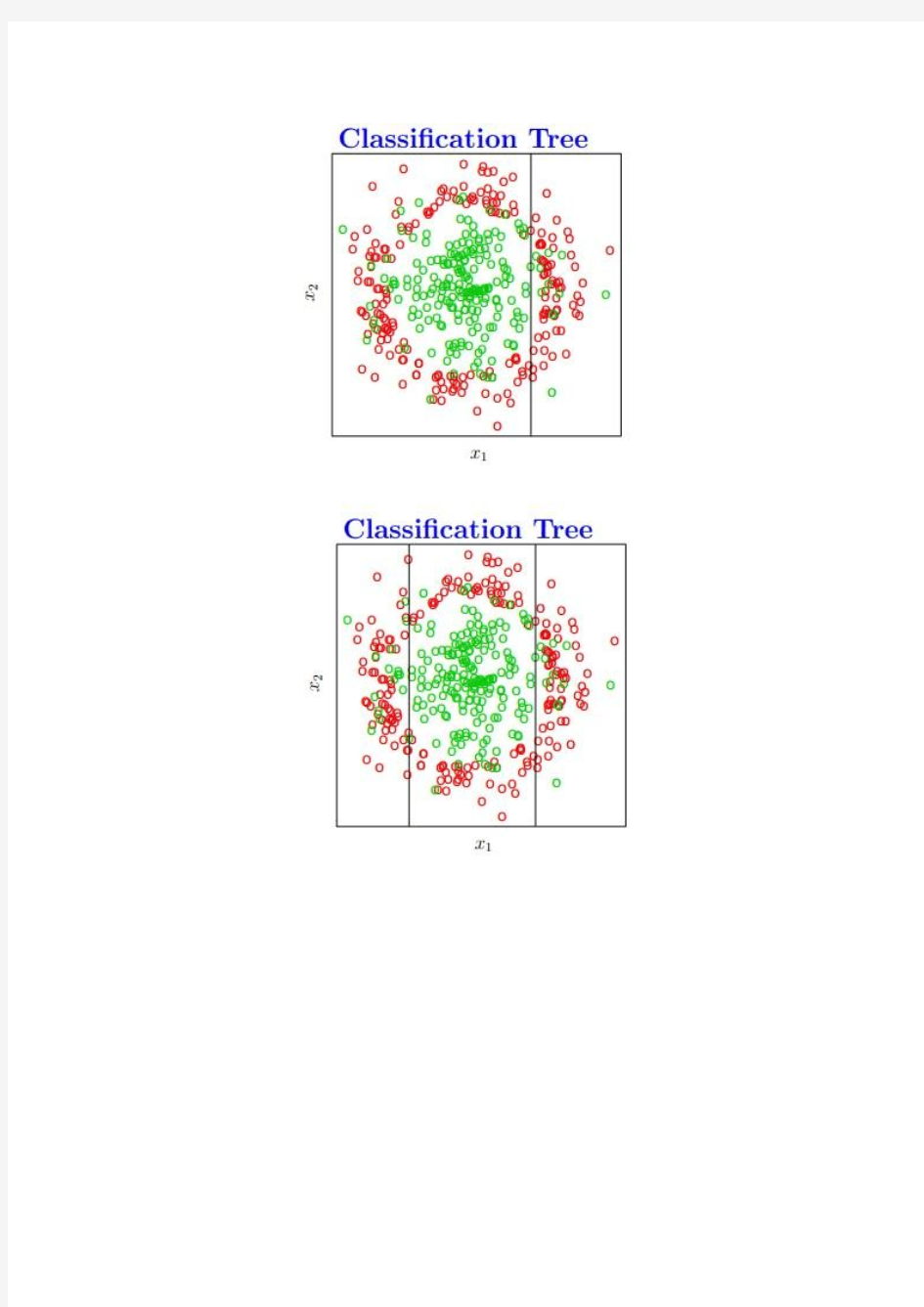
对于下面的数据,希望分割成红色和绿色两个类,原本数据生成是这样的:
Red class: x1^2+x2^2>=4.6
Green class: otherwise
经过不断分割可以得到最后的分类树:
?那么怎么分割才是最好的呢?即怎样将输入空间分割成矩形是最佳策略呢?这里一般采用三中评价标准策略:
分裂时,找到使不纯度下降最快的分裂变量和分裂点。
?从结果可以看出CART可以通过变量选择迭代地建立一棵分类树,使得每次分类平面能最好地将剩余数据分为两类。
?classification tree非常简单,但是经常会有noisy classifiers. 于是引入ensemble classifiers: bagging, random forest, 和boosting。
一般的, Boosting > Bagging > Classification tree(single tree)
?Bagging (Breiman1996): 也称bootstrap aggregation
Bagging的策略:
- 从样本集中用Bootstrap采样选出n个样本
- 在所有属性上,对这n个样本建立分类器(CART or SVM or ...)
- 重复以上两步m次,i.e.build m个分类器(CART or SVM or ...)
- 将数据放在这m个分类器上跑,最后vote看到底分到哪一类
Fit many large trees to bootstrap resampled versions of the training data, and classify by majority vote.
下图是Bagging的选择策略,每次从N个数据中采样n次得到n个数据的一个bag,总共选
择B次得到B个bags,也就是B个bootstrap samples.
?Random forest(Breiman1999):
随机森林在bagging基础上做了修改。
- 从样本集中用Bootstrap采样选出n个样本,预建立CART
- 在树的每个节点上,从所有属性中随机选择k个属性,选择出一个最佳分割属性作为节点
- 重复以上两步m次,i.e.build m棵CART
- 这m个CART形成Random Forest
这里的random就是指
1. Bootstrap中的随机选择子样本
2. Random subspace的算法从属性集中随机选择k个属性,每个树节点分裂时,从这随机的k个属性,选择最优的
结果证明有时候Random Forest比Bagging还要好。今天微软的Kinect里面就采用了Random Forest,相关论文Real-time Human Pose Recognition in Parts from Single Depth Images 是CVPR2011的best paper。
?Boosting(Freund & Schapire 1996):
Fit many large or small trees to reweighted versions of the training data. Classify by weighted majority vote.
首先给个大致的概念,boosting在选择hyperspace的时候给样本加了一个权值,使得loss
function尽量考虑那些分错类的样本(i.e.分错类的样本weight大)。
怎么做的呢?
- boosting重采样的不是样本,而是样本的分布,对于分类正确的样本权值低,分类错误的样本权值高(通常是边界附近的样本),最后的分类器是很多弱分类器的线性叠加(加权组合),分类器相当简单。
AdaBoost和RealBoost是Boosting的两种实现方法。general的说,Adaboost较好用,RealBoost较准确。
下面是AdaBoost进行权值设置与更新的过程:
以下是几个算法的性能比较:
对于多类分类(Multi-class),generalization~是类似的过程:
比如对数据进行K类分类,而不通过每次二类分类总共分K-1次的方法,我们只需要每个弱分类器比random guessing好(i.e. 准确率>1/K)
多类分类算法流程:
多类分类器loss function的设计:
===============补充===============数据挖掘的十大算法,以后可以慢慢研究:
C4.5
K-Means
SVM
Apriori
EM
PageRank
AdaBoost
kNN
NaiveBayes
CART
===============总结===============
Boosting可以进行变量选择,所以最开始的component可以是简单变量。
Boosting可能会overfit,因此在比较早的时候就停下来是正则化boosting的一个方法。期待更多朋友一起补充……
Reference:
1. https://www.sodocs.net/doc/f11616559.html,/2011/12/stories-about-statistical-learning/
2. WIKI_Boosting
3. WIKI_Bagging (Bootstrap_aggregating)
4. WIKI_CART
(完整word版)支持向量机(SVM)原理及应用概述分析
支持向量机(SVM )原理及应用 一、SVM 的产生与发展 自1995年Vapnik (瓦普尼克)在统计学习理论的基础上提出SVM 作为模式识别的新方法之后,SVM 一直倍受关注。同年,Vapnik 和Cortes 提出软间隔(soft margin)SVM ,通过引进松弛变量i ξ度量数据i x 的误分类(分类出现错误时i ξ大于0),同时在目标函数中增加一个分量用来惩罚非零松弛变量(即代价函数),SVM 的寻优过程即是大的分隔间距和小的误差补偿之间的平衡过程;1996年,Vapnik 等人又提出支持向量回归 (Support Vector Regression ,SVR)的方法用于解决拟合问题。SVR 同SVM 的出发点都是寻找最优超平面(注:一维空间为点;二维空间为线;三维空间为面;高维空间为超平面。),但SVR 的目的不是找到两种数据的分割平面,而是找到能准确预测数据分布的平面,两者最终都转换为最优化问题的求解;1998年,Weston 等人根据SVM 原理提出了用于解决多类分类的SVM 方法(Multi-Class Support Vector Machines ,Multi-SVM),通过将多类分类转化成二类分类,将SVM 应用于多分类问题的判断:此外,在SVM 算法的基本框架下,研究者针对不同的方面提出了很多相关的改进算法。例如,Suykens 提出的最小二乘支持向量机 (Least Square Support Vector Machine ,LS —SVM)算法,Joachims 等人提出的SVM-1ight ,张学工提出的中心支持向量机 (Central Support Vector Machine ,CSVM),Scholkoph 和Smola 基于二次规划提出的v-SVM 等。此后,台湾大学林智仁(Lin Chih-Jen)教授等对SVM 的典型应用进行总结,并设计开发出较为完善的SVM 工具包,也就是LIBSVM(A Library for Support Vector Machines)。LIBSVM 是一个通用的SVM 软件包,可以解决分类、回归以及分布估计等问题。 二、支持向量机原理 SVM 方法是20世纪90年代初Vapnik 等人根据统计学习理论提出的一种新的机器学习方法,它以结构风险最小化原则为理论基础,通过适当地选择函数子集及该子集中的判别函数,使学习机器的实际风险达到最小,保证了通过有限训练样本得到的小误差分类器,对独立测试集的测试误差仍然较小。 支持向量机的基本思想:首先,在线性可分情况下,在原空间寻找两类样本的最优分类超平面。在线性不可分的情况下,加入了松弛变量进行分析,通过使用非线性映射将低维输
液压传动基本知识.(DOC)
第一讲 液压传动基础知识 一、 什么是液压传动? 定义:利用密闭系统中的压力液体实现能量传递和转换的传动叫液压传动。液压传动以液体为工作介质,在液压泵中将机械能转换为液压能,在液压缸(立柱、千斤顶)或液压马达中将液压能又转换为机械能。 二、液压传动系统由哪几部分组成? 液压传动系统由液压动力源、液压执行元件、液压控制元件、液压辅助元件和工作液体组成。 三、液压传动最基本的技术参数: 1、压力:也叫压强,沿用物理学静压力的定义。静压力:静止液体中单位承压面积上所受作用力的大小。 单位:工程单位 kgf/cm 2 法定单位:1 MPa (兆帕)= 106 Pa (帕) 1 MPa (兆帕)≈10 kgf/cm 2 2、流量:单位时间内流过管道某一截面的液体的体积。 单位:工程单位:L / min ( 升/ 分钟 ) 法定单位:m 3 / s 四、职能符号: 定义:在液压系统中,采用一定的图形符号来简便、清楚地表达各种元件和管道,这种图形符号称为职能符号。 作用:表达元件的作用、原理,用职能符号绘制的液压系统图简便直观;但不能反映元件的结构。如图: 操纵阀双向锁 YDF-42/200(G) 截止阀 过滤器 安全阀 千斤顶液控单向阀 五、常用密封件: 1.O 形圈: 常用标记方法: 公称外径(mm ) 截面直径 (mm ) 2.挡圈(O 形圈用): 3.常用标记方法: 挡圈 A D × d × a
A型(切口式); D外径(mm);d内径(mm);a厚度(mm) 第二讲控制阀;液控单向阀;单向锁 一、控制阀: 1.定义:在液压传动系统中,对传动液体的压力、流量或方向进行调节和控制的液压元件统称为控制阀。 2.分类:根据阀在液压系统中的作用不同分为三类: 压力控制阀:如安全阀、溢流阀 流量控制阀:如节流阀 方向控制阀:如操纵阀液控单向阀双向锁 3.对阀的基本要求: (1)工作压力和流量应与系统相适应; (2)动作准确,灵敏可靠,工作平稳,无冲击和振动现象; (3)密封性能好,泄漏量小; (4)结构简单,制作方便,通用性大。 二、液控单向阀结构与原理: 1.定义:在支架液压系统中用以闭锁液压缸中的液体,使之承载的控制元件为液控单向阀。一般单向阀只能使工作液一个方向流动,不能逆流,而液控单向阀可以由液压控制打开单向阀,使工作液逆流。 2. 3. 作用(以立柱液控单向阀为例): ①升柱:把操纵阀打到升柱位置,高压液打开液控单向阀阀芯向立柱下腔供液,立柱活塞杆伸出。 ②承载:升到要求高度时继续供液3~5s后停止供液,此时液控单向阀在立柱下腔高压液体的压力作用下,阀芯关闭,闭锁立柱下腔中的液体,阻止立柱下腔的液体回流,使立柱承载。 ③降柱:把操纵阀打向降柱位置,从操作阀过来的高压液一路通向立柱上腔,一路打开液控阀阀芯,沟通立柱下腔回路,立柱下降。 4. 规格型号:
svm使用详解
1.文件中数据格式 label index1:value1 index2:value2 ... Label在分类中表示类别标识,在预测中表示对应的目标值 Index表示特征的序号,一般从1开始,依次增大 Value表示每个特征的值 例如: 3 1:0.122000 2:0.792000 3 1:0.144000 2:0.750000 3 1:0.194000 2:0.658000 3 1:0.244000 2:0.540000 3 1:0.328000 2:0.404000 3 1:0.402000 2:0.356000 3 1:0.490000 2:0.384000 3 1:0.548000 2:0.436000 数据文件准备好后,可以用一个python程序检查格式是否正确,这个程序在下载的libsvm文件夹的子文件夹tools下,叫checkdata.py,用法:在windows命令行中先移动到checkdata.py所在文件夹下,输入:checkdata.py 你要检查的文件完整路径(包含文件名) 回车后会提示是否正确。
2.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值: lower = -1,upper = 1,没有对y进行缩放) 其中, -l:数据下限标记;lower:缩放后数据下限; -u:数据上限标记;upper:缩放后数据上限; -y:是否对目标值同时进行缩放;y_lower为下限值,y_upper 为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 ) -s save_filename:表示将缩放的规则保存为文件save_filename; -r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放; filename:待缩放的数据文件(要求满足前面所述的格式)。 数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为:
基于支持向量机的图像分类研究
目录 摘要 (2) Abstract (3) 1 引言 (3) 1.1 概述 (4) 1.2 统计学习理论 (4) 1.3 支持向量机及其发展简史 (5) 1.4 研究内容及其现实意义 (6) 2 持向量机模型的建立 (7) 2.1 SVM核函数 (7) 2.2 核函数的选择 (8) 2.3 SVM算法简介 (8) 2.4 SVM学习算法的步骤 (9) 3 图像内容的描述及特征提取 (10) 3.1 图像内容的描述模型 (10) 3.2 颜色特征的描述 (10) 3.2.1 颜色的表示和颜色模型 (10) 3.2.2 颜色直方图 (11) 3.2.3 累积颜色直方图 (12) 3.2.4 主色 (12) 3.3 纹理特征的描述 (12) 4 基于SVM的图像分类方法研究 (13) 4.1 分类系统的结构 (13) 4.1.1 特征提取模块 (13) 4.1.2 SVM分类模块 (13) 4.2 特征提取策略 (14) 4.3 实验 (14) 4.3.1 三种核函数的选择比较实验 (14) 4.3.2 基于颜色特征的图像分类 (17) 4.3.3 基于纹理特征的图像分类 (17) 4.3.4 基于综合特征的图像分类 (17) 5 结论 (18) 参考文献 (19)
摘要 支持向量机(SVM)方法是建立在统计学习理论基础之上的,克服了神经网络分类和传统统计分类方法的许多缺点,具有较高的泛化性能。但是,由于支持向量机尚处在发展阶段,很多方面尚不完善,现有成果多局限于理论分析,而应用显得较薄弱,因此研究和完善利用支持向量机进行图像分类对进一步推进支持向量机在图像分析领域的应用具有积极的推动作用。本文研究了图像的颜色、纹理等特征对利用支持向量机进行图像分类的影响。对支持向量机在图像分类中的应用作了较全面的研究。对三种核函数进行了对比实验,实验表明二项式核函数较高斯核函数和sigmoid核函数具有更强的泛化能力;同时,通过实验分析了特征选取对向量机性能的影响,发现综合特征有利于分类效果的提高。在以上研究的基础上,我们建立了一个基于svM的图像分类实验平台,讨论了系统的组成模块和功能,给出了一些图像分类实例,并验证了前述理论研究的结果。 关键词:统计学习理论支持向量机图像分类特征提取
液压系统基础知识大全液压系统的组成及其作用一个完整的液压系统
液压系统基础知识大全 液压系统的组成及其作用 一个完整的液压系统由五个部分组成,即动力元件、执行元件、控制元件、辅助元件(附件)和液压油。 动力元件的作用是将原动机的机械能转换成液体的压力能,指液压系统中的油泵,它向整个液压系统提供动力。液压泵的结构形式一般有齿轮泵、叶片泵和柱塞泵。 执行元件(如液压缸和液压马达)的作用是将液体的压力能转换为机械能,驱动负载作直线往复运动或回转运动。 控制元件(即各种液压阀)在液压系统中控制和调节液体的压力、流量和方向。根据控制功能的不同,液压阀可分为村力控制阀、流量控制阀和方向控制阀。压力控制阀又分为益流阀(安全阀)、减压阀、顺序阀、压力继电器等;流量控制阀包括节流阀、调整阀、分流集流阀等;方向控制阀包括单向阀、液控单向阀、梭阀、换向阀等。根据控制方式不同,液压阀可分为开关式控制阀、定值控制阀和比例控制阀。 辅助元件包括油箱、滤油器、油管及管接头、密封圈、快换接头、高压球阀、胶管总成、测压接头、压力表、油位油温计等。 液压油是液压系统中传递能量的工作介质,有各种矿物油、乳化液和合成型液压油等几大类。 液压系统结构
液压系统由信号控制和液压动力两部分组成,信号控制部分用于驱动液压动力部分中的控制阀动作。 液压动力部分采用回路图方式表示,以表明不同功能元件之间的相互关系。液压源含有液压泵、电动机和液压辅助元件;液压控制部分含有各种控制阀,其用于控制工作油液的流量、压力和方向;执行部分含有液压缸或液压马达,其可按实际要求来选择。 在分析和设计实际任务时,一般采用方框图显示设备中实际运行状况。空心箭头表示信号流,而实心箭头则表示能量流。 基本液压回路中的动作顺序—控制元件(二位四通换向阀)的换向和弹簧复位、执行元件(双作用液压缸)的伸出和回缩以及溢流阀的开启和关闭。对于执行元件和控制元件,演示文稿都是基于相应回路图符号,这也为介绍回路图符号作了准备。 根据系统工作原理,您可对所有回路依次进行编号。如果第一个执行元件编号为0,则与其相关的控制元件标识符则为1。如果与执行元件伸出相对应的元件标识符为偶数,则与执行元件回缩相对应的元件标识符则为奇数。不仅应对液压回路进行编号,也应对实际设备进行编号,以便发现系统故障。 DIN ISO1219-2标准定义了元件的编号组成,其包括下面四个部分:设备编号、回路编号、元件标识符和元件编号。如果整个系统仅有一种设备,则可省略设备编号。 实际中,另一种编号方式就是对液压系统中所有元件进行连续编号,此时,元件编号应该与元件列表中编号相一致。这种方法特别适用于复杂液压控制系统,每个控制回路都与其系统编号相对应 国产液压系统的发展 目前我国液压技术缺少技术交流,液压产品大部分都是用国外的液压技术加工回来的,液压英才网提醒大家发展国产液压技术振兴国产液压系统技术。 其实不然,近几年国内液压技术有很大的提高,如派瑞克等公司都有很强的实力。 液压附件: 目前在世界上,做附件较好的有: 派克(美国)、伊顿(美国)颇尔(美国) 西德福(德国)、贺德克(德国)、EMB(德国)等 国内较好的有: 旭展液压、欧际、意图奇、恒通液压、依格等 液压传动和气压传动称为流体传动,是根据17世纪帕斯卡提出的液体静压力传动原理而发展起来的一门新兴技术,是工农业生产中广为应用的一门技术。如今,流体传动技术水平的高低已成为一个国家工业发展水平的重要标志。 1795年英国约瑟夫·布拉曼(Joseph Braman,1749-1814),在伦敦用水作为工作介质,以水压机的形式将其应用于工业上,诞生了世界上第一台水压机。1905年将工作介质水改为油,又进一步得到改善。
svm核函数matlab
clear all; clc; N=35; %样本个数 NN1=4; %预测样本数 %********************随机选择初始训练样本及确定预测样本******************************* x=[]; y=[]; index=randperm(N); %随机排序N个序列 index=sort(index); gama=23.411; %正则化参数 deita=0.0698; %核参数值 %thita=; %核参数值 %*********构造感知机核函数************************************* %for i=1:N % x1=x(:,index(i)); % for j=1:N % x2=x(:,index(j)); % K(i,j)=tanh(deita*(x1'*x2)+thita); % end %end %*********构造径向基核函数************************************** for i=1:N x1=x(:,index(i)); for j=1:N x2=x(:,index(j)); x12=x1-x2; K(i,j)=exp(-(x12'*x12)/2/(deita*deita)); End End %*********构造多项式核函数**************************************** %for i=1:N % x1=x(:,index(i)); % for j=1:N % x2=x(:,index(j)); % K(i,j)=(1+x1'*x2)^(deita); % end %end %*********构造核矩阵************************************ for i=1:N-NN1 for j=1:N-NN1 omeiga1(i,j)=K(i,j); end end
svmtrain和svmpredict简介回归、分类
svmtrain和svmpredict简介 分类:SVM 本文主要介绍了SVM工具箱中svmtrain和svmpredict两个主要函数: (1)model= svmtrain(train_label, train_matrix, ['libsvm_options']); 其中: train_label表示训练集的标签。 train_matrix表示训练集的属性矩阵。 libsvm_options是需要设置的一系列参数,各个参数可参见《libsvm 参数说明.txt》,里面介绍的很详细,中英文都有的。如果用 回归的话,其中的-s参数值应为3。 model:是训练得到的模型,是一个结构体(如果参数中用到-v,得到的就不是结构体,对于分类问题,得到的是交叉检验下的平均分类准确 率;对于回归问题,得到的是均方误差)。 (2)[predicted_label, accuracy/mse,decision_values/prob_estimates] =svmpredict(test_label, test_matrix, model, ['libsvm_options']); 其中: test _label表示测试集的标签(这个值可以不知道,因为作预测的时候,本来就是想知道这个值的,这个时候,随便制定一个值就可以 了,只是这个时候得到的mse就没有意义了)。 test _matrix表示测试集的属性矩阵。 model 是上面训练得到的模型。 libsvm_options是需要设置的一系列参数。 predicted_label表示预测得到的标签。 accuracy/mse是一个3*1的列向量,其中第1个数字用于分类问题,表示分类准确率;后两个数字用于回归问题,第2个数字 表示mse;第三个数字表示平方相关系数(也就是说,如 果分类的话,看第一个数字就可以了;回归的话,看后两 个数字)。 decision_values/prob_estimates:第三个返回值,一个矩阵包含决策
选取SVM中参数c和g的最佳值
写了个程序来选取SVM中参数c和g的最佳值. [写这个的目的是方便大家用这个小程序直接来寻找c和g的最佳值,不用再另外编写东西了.] 其实原本libsvm C语言版本中有相应的子程序可以找到最佳的c和g,需装载python语言然后用py 那个画图就可以找到最佳的c和g,我写了个matlab版本的.算是弥补了libsvm在matlab版本下的空缺. 测试数据还是我视频里的wine data. 寻找最佳c和g的思想仍然是让c和g在一定的范围里跑(比如 c = 2^(-5),2^(-4),...,2^(5),g = 2^(-5),2^(-4),...,2^(5)),然后用cross validation的想法找到是的准确率最高的c和g,在这里我做了一点修改(纯粹是个人的一点小经验和想法),我改进的是: 因为会有不同的c和g都对应最高的的准确率,我把具有最小c的那组c和g认为是最佳的c和g,因为惩罚参数不能设置太高,很高的惩罚参数能使得validation数据的准确率提高,但过高的惩罚参数c会造成过学习状态,反正从我用SVM到现在,往往都是惩罚参数c过高会导致最终测试集合的准确率并不是很理想.. 在使用这个程序时也有小技巧,可以先大范围粗糙的找比较理想的c和g,然后再细范围找更加理想的c和g. 比如首先让c = 2^(-5),2^(-4),...,2^(5),g = 2^(-5),2^(-4),...,2^(5)在这个范围找比较理想的c和g,如图:
====== 此时bestc = 0.5,bestg=1,bestacc = 98.8764[cross validation 的准确率] 最终测试集合的准确率Accuracy = 96.6292% (86/89) (classification) ====== 此时看到可以把c和g的范围缩小.还有步进的大小也可以缩小(程序里都有参数可以自己调节,也有默认值可不调节). 让c = 2^(-2),2^(-1.5),...,2^(4),g = 2^(-4),2^(-3.5),...,2^(4)在这个范围找比较理想的c 和g,如图: ============= 此时bestc = 0.3536,bestg=0.7017,bestacc = 98.8764[cross validation 的准确率] 最终测试集合的准确率Accuracy = 96.6292% (86/89) (classification) ===================上面第二个的测试的代码: 1.load wine_SVM;
基于libsvm的gist和phog特征的图像分类研究
研究生技术报告题目:基于libsvm的图像分类研究 编号:20132098 执笔人:刘金环 完成时间:2013-11-23
摘要 随着科学技术的飞速发展,机器学习与人工智能技术的不断创新,人们对特定信息检索的需求逐渐增加,使得如何对资源进行合理有效的分类成为一个关键问题。支持向量机(SVM)是一种建立在统计学习理论基础之上的机器学习方法,由于其基于小样本训练的优越性,被广泛应用于模式识别的各个领域,在图像检索、人脸识别等中充分了体现了其优越性,越来越受到广泛的关注和重视。 本文主要介绍了基于libsvm分类器的分类问题。本文以gist和phog特征为例简单实现了图像的分类问题,并通过查询准确性对这两种分类方法进行对比和分析。由仿真结果可知,gist特征分类要好于phog的特征分类,仿真效果较为理想。
目录 1 课题意义..................................................................................................... 错误!未定义书签。 2 技术要求及性能指标................................................................................. 错误!未定义书签。3方案设计及算法原理.................................................................................. 错误!未定义书签。 3.1基于libsvm的gist特征提取分类.............................................. 错误!未定义书签。 3.1.1算法原理 (1) 3.1.2设计框图 (2) 3.2基于libsvm的phog特征提取分类.............................................. 错误!未定义书签。 3.2.1算法原理.............................................................................. 错误!未定义书签。 3.2.2设计框图.............................................................................. 错误!未定义书签。4代码及相关注释. (4) 4.1基于libsvm的gist特征提取分类仿真结果 (6) 4.1.1代码及注释 (9) 4.1.2测试结果 (9) 4.2基于libsvm的phog特征提取分类仿真结果 (9) 4.2.1代码及注释 (9) 4.2.2测试结果 (12) 4.3基于libsvm的gist特征分类不同训练集测试结果.................. 错误!未定义书签。 4.3.1代码及注释.......................................................................... 错误!未定义书签。 4.3.2测试结果 (14) 5实验结果分析.............................................................................................. 错误!未定义书签。6总结 ............................................................................................................. 错误!未定义书签。
支持向量机(SVM)算法推导及其分类的算法实现
支持向量机算法推导及其分类的算法实现 摘要:本文从线性分类问题开始逐步的叙述支持向量机思想的形成,并提供相应的推导过程。简述核函数的概念,以及kernel在SVM算法中的核心地位。介绍松弛变量引入的SVM算法原因,提出软间隔线性分类法。概括SVM分别在一对一和一对多分类问题中应用。基于SVM在一对多问题中的不足,提出SVM 的改进版本DAG SVM。 Abstract:This article begins with a linear classification problem, Gradually discuss formation of SVM, and their derivation. Description the concept of kernel function, and the core position in SVM algorithm. Describes the reasons for the introduction of slack variables, and propose soft-margin linear classification. Summary the application of SVM in one-to-one and one-to-many linear classification. Based on SVM shortage in one-to-many problems, an improved version which called DAG SVM was put forward. 关键字:SVM、线性分类、核函数、松弛变量、DAG SVM 1. SVM的简介 支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力。 对于SVM的基本特点,小样本,并不是样本的绝对数量少,而是与问题的复杂度比起来,SVM算法要求的样本数是相对比较少的。非线性,是指SVM擅长处理样本数据线性不可分的情况,主要通过松弛变量和核函数实现,是SVM 的精髓。高维模式识别是指样本维数很高,通过SVM建立的分类器却很简洁,只包含落在边界上的支持向量。
LIBSVM使用介绍
附录1:LIBSVM的简单介绍 1. LIBSVM软件包简介 LIBSVM是台湾大学林智仁(Chih-Jen Lin)博士等开发设计的一个操作简单、易于使用、快速有效的通用SVM软件包,可以解决分类问题(包括C SVC ?、SVC ν?)、回归问题(包括SVR ε?、SVR ν?)以及分布估计(on e class SVM ??)等问题,提供了线性、多项式、径向基和S形函数四种常用的核函数供选择,可以有效地解决多类问题、交叉验证选择参数、对不平衡样本加权、多类问题的概率估计等。LIBSVM是一个开源的软件包,需要者都可以免费的从作者的个人主页https://www.sodocs.net/doc/f11616559.html,.tw/~cjlin/处获得。他不仅提供了LIBSVM的C++语言的算法源代码,还提供了Python、Java、R、MA TLAB、Perl、Ruby、LabVIEW 以及C#.net等各种语言的接口,可以方便的在Windows或UNIX平台下使用,也便于科研工作者根据自己的需要进行改进(譬如设计使用符合自己特定问题需要的核函数等)。另外还提供了WINDOWS平台下的可视化操作工具SVM-toy,并且在进行模型参数选择时可以绘制出交叉验证精度的等高线图。 2. LIBSVM使用方法简介 LIBSVM在给出源代码的同时还提供了Windows操作系统下的可执行文件,包括:进行支持向量机训练的svmtrain.exe;根据已获得的支持向量机模型对数据集进行预测的svmpredict.exe;以及对训练数据与测试数据进行简单缩放操作的svmscale.exe。它们都可以直接在DOS环境中使用。如果下载的包中只有C++的源代码,则也可以自己在VC等软件上编译生成可执行文件。 LIBSVM使用的一般步骤是: 1)按照LIBSVM软件包所要求的格式准备数据集; 2)对数据进行简单的缩放操作; 3)考虑选用RBF核函数 2 (,)x y K x y eγ?? =; 4)采用交叉验证选择最佳参数C与γ;
SVM分类方法在人脸图像分类中的应用
SVM分类方法在人脸图像分类中的应用 摘要:本文首先简要综述了人脸识别技术中不同的特征提取方法和分类方法;然后介绍了支持向量机(SVM)的原理、核函数类型选择以及核参数选择原则以及其在人脸分类识别中了应用,最后通过在构建的人脸库上的仿真实验观测观测不同的特征提取方法对人脸识别率的影响、不同的学习样本数对人脸识别率的影响、支持向量机选用不同的核函数后对人脸识别率的影响、支持向量机选用不同的核参数后对人脸识别率的影响。 一、人脸识别简介 人脸识别也就是利用计算机分析人脸图象,进而从中提取出有效的识别信息,用来“辨认”身份的一门技术。人脸识别技术应用背景广泛,可用于公安系统的罪犯身份识别、驾驶执照及护照等与实际持证人的核对、银行及海关的监控系统及自动门卫系统等。 常见的人脸识别方法包括基于KL变换的特征脸识别、基于形状和灰度分离的可变形模型识别、基于小波特征的弹性匹配、基于传统的部件建模识别、基于神经网络的识别、基于支持向量机的识别等。其中特征脸方法、神经网络方法、基于支持向量机的方法等是基于整体人脸的识别,而基于提取眼睛等部件特征而形成特征向量的方法就是基于人脸特征的识别。 虽然人类的人脸识别能力很强,能够记住并辨别上千个不同人脸,可是计算机则困难多了。其表现在:人脸表情丰富;人脸随年龄增长而变化;人脸所成图象受光照、成象角度及成象距离等影响;而且从二维图象重建三维人脸是病态过程,目前尚没有很好的描述人脸的三维模型。另外,人脸识别还涉及到图象处理、计算机视觉、模式识别以及神经网络等学科,也和人脑的认识程度紧密相关。这诸多因素使得人脸识别成为一项极富挑战性的课题。 通常人类进行人脸识别依靠的感觉器官包括视觉、听觉、嗅觉与触觉等。一般人脸的识别可以用单个感官完成,也可以是多感官相配合来存储和检索人脸。而计算机的人脸识别所利用的则主要是视觉数据。另外计算机人脸识别的进展还受限于对人类本身识别系统的认识程度。研究表明,人类视觉数据的处理是一个
液压技术基础知识
液压技术基础知识 一.液压传动的介绍 液压传动是用液体作为工作介质来传递能量和进行控制的传动方式。液压传动和气压传动并称为流体传动,是根据17世纪帕斯卡提出的液体静压力传动原理而发展起来的一门新兴技术,是工业生产中应用广泛的技术。在我们的生活中,随处可以见到液压技术的使用,液压传动有许多突出的优点,因此它的应用非常广泛,如一般工业用的压力机械、机床等;行走机械中的工程机械、建筑机械、农业机械、汽车等;钢铁工业用的冶金机械、提升装置、轧辊调整装置等;土木水利工程用的防洪闸门及堤坝装置、河床升降装置、桥梁操纵机构等;发电厂涡轮机调速装置等等;特殊技术用的控制装置、测量浮标、升降旋转舞台等;军事工业用的火炮操纵装置、飞行器仿真、飞机起落架的收放装置和方向舵控制装置等。在船舶上,更是大量使用了液压传动,如船甲板起重机械、船头门、舱壁阀、船尾推进器、船舶减摇装置、舵机、锚缆机操控系统、舱盖控制系统等; 二.液压传动的特点 1.液压传动的优点。 (1)体积小、重量轻,因此惯性力较小,当突然过载或停车时,不会发生大的冲击; (2)能在给定范围内平稳的自动调节牵引速度,并可实现无极调速; (3)换向容易,在不改变电机旋转方向的情况下,可以较方便地实现工作机构旋转和直线往复运动的转换; (4)液压泵和液压马达之间用油管连接,在空间布置上彼此不受严格限制;(5)由于采用油液为工作介质,元件相对运动表面间能自行润滑,磨损小,使用寿命长; (6)操纵控制简便,自动化程度高; (7)容易实现过载保护。 2.液压传动的缺点 (1)使用液压传动对维护的要求高,工作油要始终保持清洁; (2)对液压元件制造精度要求高,工艺复杂,成本较高; (3)液压元件维修较复杂,且需有较高的技术水平; (4)用油做工作介质,在工作面存在火灾隐患; (5)传动效率低。 三.液压传动的基本原理 液压传动的基本原理是在密闭的容器内,利用有压力的油液作为工作介质来实现能量转换和传递动力的,也就是利用密封工作腔变化进行工作,通过液体介质的压力进行能量的转换和传递。其中的液体称为工作介质,一般为矿物油,它的作用和机械传动中的皮带、链条和齿轮等传动元件相类似。液压传动是利用帕斯卡原理,在密闭环境中,向液体施加一个力,这个液体会向各个方向传递这个力,且力的大小不变。液压传动就是利用这个物理性质,向一个物体施加一个力,利用帕斯卡原理使这个力变大,从而起到举起重物的效果。 传递动力时,基于技师守恒定律,传递力时,基于帕斯卡原理。 四.液压传动的工作特性 1.压力取决于负载。P=F/A,也就是说,没有负载就没有压力。
SVM方法步骤
SVM 方法步骤 彭海娟 2010-1-29 看了一些文档和程序,大体总结出SVM 的步骤,了解了计算过程,再看相关文档就比较容易懂了。 1. 准备工作 1) 确立分类器个数 一般都事先确定分类器的个数,当然,如有必要,可在训练过程中增加分类器的个数。分类器指的是将样本中分几个类型,比如我们从样本中需要识别出:车辆、行人、非车并非人,则分类器的个数是3。 分类器的个数用k 2) 图像库建立 SVM 方法需要建立一个比较大的样本集,也就是图像库,这个样本集不仅仅包括正样本,还需要有一定数量的负样本。通常样本越多越好,但不是绝对的。 设样本数为S 3) ROI 提取 对所有样本中的可能包含目标的区域(比如车辆区域)手动或自动提取出来,此时包括正样本中的目标区域,也包括负样本中类似车辆特征的区域或者说干扰区域。 4) ROI 预处理 包括背景去除,图像滤波,或者是边缘增强,二值化等预处理。预处理的方法视特征的选取而定。 5) 特征向量确定 描述一个目标,打算用什么特征,用几个特征,给出每个特征的标示方法以及总的特征数,也就是常说的特征向量的维数。 对于车辆识别,可用的特征如:车辆区域的灰度均值、灰度方差、对称性、信息熵、傅里叶描述子等等。 设特征向量的维数是L 。 6) 特征提取 确定采取的特征向量之后,对样本集中所有经过预处理之后的ROI 区域进行特征提取,也就是说计算每个ROI 区域的所有特征值,并将其保存。 7) 特征向量的归一化 常用的归一化方法是:先对相同的特征(每个特征向量分别归一化)进行排序,然后根据特征的最大值和最小值重新计算特征值。 8) 核的选定 SVM 的构造主要依赖于核函数的选择,由于不适当的核函数可能会导致很差的分类结果,并且目前尚没有有效的学习使用何种核函数比较好,只能通过实验结果确定采用哪种核函数比较好。训练的目标不同,核函数也会不同。 核函数其实就是采用什么样的模型描述样本中目标特征向量之间的关系。如常用的核函数:Gauss 函数 2 1),(21x x x p e x x k --= 对样本的训练就是计算p 矩阵,然后得出描述目标的模板和代表元。 2. 训练 训练就是根据选定的核函数对样本集的所有特征向量进行计算,构造一个使样本可分的
libsvm简单介绍
在用林智仁老师的LIBSVM-2.82做SVM回归的过程中,深深得益于网上共享的学习笔记以及一些热心网友的帮助(哪怕只是一句提醒),前面想着一定要写个学习笔记。自己会用了之后,突然发现原来值得讲出来的实在很少,甚至不想再写什么。想到自己花大概两个月才把一个程序跑明白,觉得还是因为其中有些让自己头疼的问题的,想必其他学习者未尝不需要多花功夫琢磨这些,未免浪费时间(技术问题嘛),还是写一个简单的学习笔记,把自己觉得最要弄明白的难点记下来吧。 装microsoft Visualstudio 6.0(是装python需要的,可能是需要c语言的环境吧) 装gnuplot :gp400win32 装python 试运行程序中遇到的问题 读PYTHON写的GRID.PY程序 问题1:程序的路径指定问题在程序的相关语句中指出调用的程序的路径 注意类似: D:\programm files\gnuplot.exe 这样的路径会报错,因为程序在读语句时在programm后面断句,而不是把programm files整体当作一个路径 问题2:命令行运行PYTHON 以及输入参数 E:\libsvm-2.82\tools>python gridregcopy.py,首先进入到PYTHON程序的上一级路径然后用python接程序名称以及参数 当时的问题是怎么也弄不明白PYTHON程序自带的几个操作窗口都不能进行程序的运行。呵呵,好像都只是脚本编辑器(反正我能用命令行运行就可以了——何况加一个"!"就可以在MA TLAB中执行)。 另外关于参数,读原程序怎么也不懂,看了魏忠的学习笔记才明白的: OS.ARGV 可以在命令行输入,作为OS.ARGV列表的值。但是注意OS.ARGV[0]默认的就是所执行的程序本身,也就是除了输入的N个参数,OS.ARGV列表实际上有N+1个值,其中输入的第一个参数就是OS.ARGV[1],也就是它的第二个参数。 问题3:参数选择程序跑不动 提示: worker local quit 晕了几天后面终于明白不是程序有问题,是因为数据量太大,程序直接溢出的缘故:注意有一个参数-M 用来选择缓存的大小。 subset这个程序仍然运行不了——不知道自己的数据和程序包里给出的例子有什么区别。不过我的s数据量小,这个不能用不碍事。 注意: testing data/training data(不同文件) 需要一起scale。 也就是要把测试集和训练集在一个框架下进行归一化处理,很容易想见的道理(可是容易忽
毕业设计(论文)-基于SVM的图像分类系统设计文档
LANZHOU UNIVERSITY OF TECHNOLOGY 毕业设计 题目基于SVM的图象分类系统 学生姓名 学号 专业班级计算机科学与技术3班 指导教师 学院计算机与通信学院 答辩日期
摘要 支持向量机(SVM)方法是建立在统计学习理论基础之上的,克服了神经网络分类和传统统计分类方法的许多缺点,具有较高的泛化性能。但是,由于支持向量机尚处在发展阶段,很多方面尚不完善,现有成果多局限于理论分析,而应用显得较薄弱,因此研究和完善利用支持向量机进行图像分类对进一步推进支持向量机在图像分析领域的应用具有积极的推动作用。 本文通过支持向量机技术和图像特征提取技术实现了一个图像分类实验系统。文中首先引入了支持向量机概念,对支持向量机做了较全面的介绍;然后,讨论了图像特征的描述和提取方法,对图像的颜色矩特征做了详细的描述,对svm分类也做了详细的说明;最后讨论了由分类结果所表现的一些问题。测试结果表明,利用图像颜色矩特征的分类方法是可行的,并且推断出采用综合特征方法比采用单一特征方法进行分类得到的结果要更令人满意。 关键词:支持向量机图像分类特征提取颜色矩
Abstract The support vector machine (SVM) method is based on statistical learning theory foundation, overcome the neural network classification and traditional statistical classification method of faults, and has high generalization performance. But, because the support vector machine (SVM) is still in the development stage, many still not perfect, the existing results more limited to the theoretical analysis, and the use of appear more weak and therefore study and improve the use of support vector machines to image classification support vector machine to further advance in the application of image analysis play a positive role in promoting. In this paper, support vector machine (SVM) technology and image feature extraction technology implements a image classification experiment system. This paper first introduces the concept of support vector machine (SVM), the support vector machine (SVM) made a more comprehensive introduction; Then, discussed the image characteristics of description and extraction method, the image color moment features described in detail, also made detailed instructions for the SVM classification; Finally discussed the classification results of some problems. Test results show that using the torque characteristics of the image color classification method is feasible, and deduce the comprehensive characteristic method than using single feature method to classify the results are more satisfactory. Keywords: support vector machine image classification feature extraction Color Moment