强连通的Tarjan算法
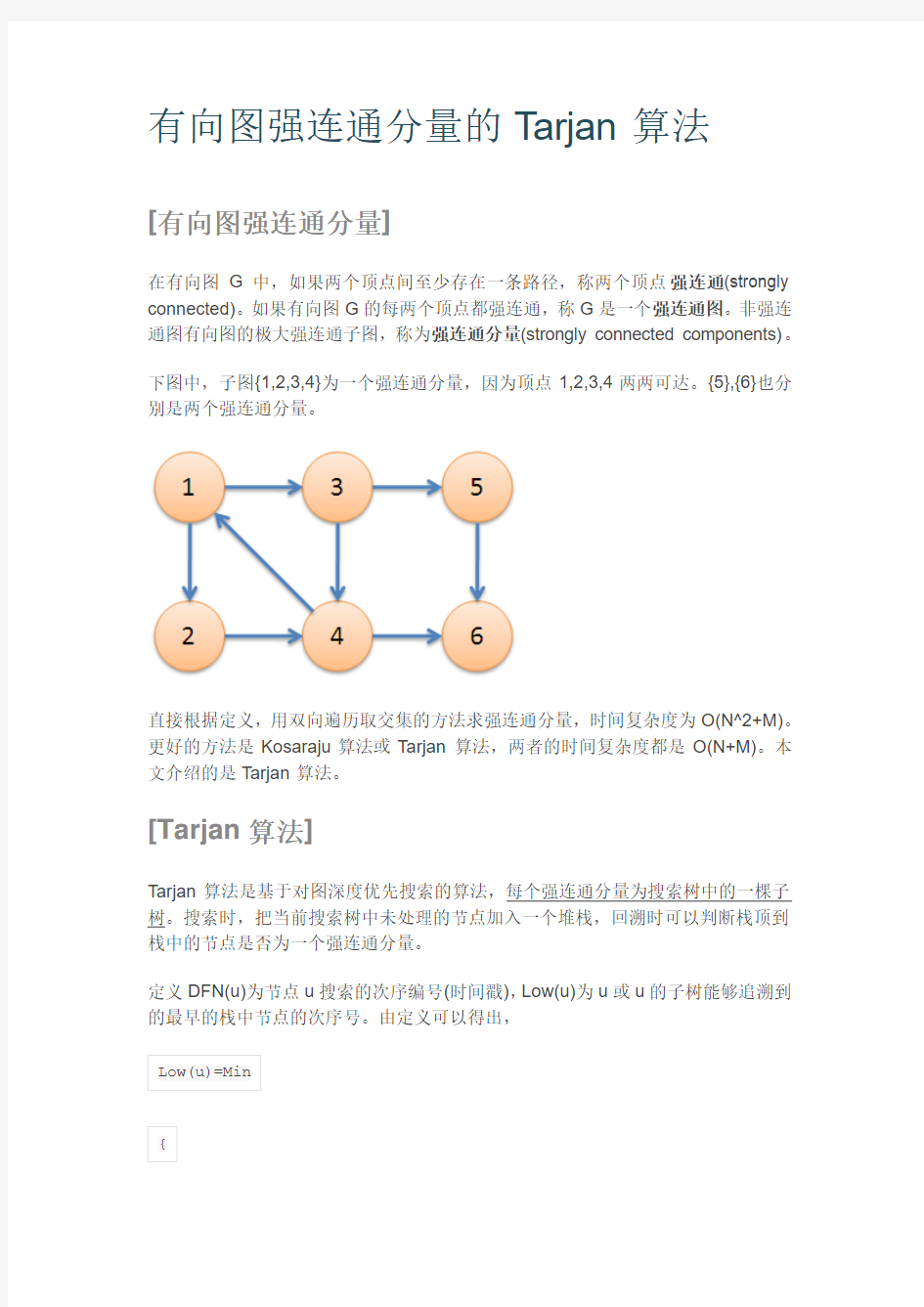

有向图强连通分量的Tarjan算法
返回节点3,继续搜索到节点4,把4加入堆栈。发现节点4向节点1有后向边,节点1还在栈中,所以LOW[4]=1。节点6已经出栈,(4,6)是横叉边,返回3,(3,4)为树枝边,所以LOW[3]=LOW[4]=1。
继续回到节点1,最后访问节点2。访问边(2,4),4还在栈中,所以LOW[2]=DFN[4]=5。返回1后,发现DFN[1]=LOW[1],把栈中节点全部取出,组成一个连通分量{1,3,4,2}。
图的连通性总结
图的连通性总结 boboo 目录 1.图的遍历及应用 1.1.DFS遍历 1.2.DFS树的边分类 1.3.DFS树的性质 1.4.拓补排序 1.5.欧拉回路 2.无向图相关 2.1求割顶 2.2求图的桥 2.3求图的块 3.有向图相关 3.1求强连通分量(SCC划分) 3.2求传递闭包 4.最小环问题
一、图的遍历及应用 1.1 DFS遍历 DFS是求割顶、桥、强连通分量等问题的基础。 DFS对图进行染色, 白色:未访问; 灰色:访问中(正在访问它的后代); 黑色:访问完毕 一般在具体实现时不必对图的顶点进行染色,只需进行访问开始时间和访问结束时间的记录即可,这样就可以得出需要的信息了。 -发现时间D[v]:变灰的时间 -结束时间f[v]:变黑的时间 -1<=d[v] 08-图论-离散数学讲义-海南大学(共十一讲) 8.图论Topics in Graph Theory §8.1 图Graphs G= v i 起点弧尾, v j 终点弧头 TD(v i ):顶点的度degree: 以v i 为端点的边的数目。 OD(vi): 出度, 以v i 为起点的边的数目。 ID(v i ): 入度,以v i 为终点的边的数目。 TD(v i )= OD(vi)+ ID(v i ) OD=ID, TD=2|E|,E| =1/2*TD TD OD ID 为整个图的总度,出度,入度数。 路径path : v i ······v j , 以v i 为起点v j 为终点的顶点序列,相邻顶点相邻。 路径的长length : 路径上边的数目, 简单路径simple path :点都不重复的路径, 回路circuit : 首尾相接的路径, 简单回路simple circuit : 除起点和终点以外都不重复的路径, v i v j 连通connected : 有路径 v i ······v j 相连。 连通图: 任意两点都连通的图。 例 左图a,c,d,g 是简单路径 右图a,d,b,c,e 是简单路径。 f,e,a,d,b,a,f 是简单回路。 f,e,d,c,e,f 不是简单回路。 b f g d c e a f d c a e b 连通图的割点、割边(桥)、块、缩点,有向图的强连通分量 一、基本概念 无向图 割点:删掉它之后(删掉所有跟它相连的边),图必然会分裂成两个或两个以上的子图。 块:没有割点的连通子图 割边:删掉一条边后,图必然会分裂成两个或两个以上的子图,又称桥。 缩点:把没有割边的连通子图缩为一个点,此时满足任意两点间都有两条路径相互可达。 求块跟求缩点非常相似,很容易搞混,但本质上完全不同。割点可以存在多个块中(假如存在k个块中),最终该点与其他点形成k个块,对无割边的连通子图进行缩点后(假设为k个),新图便变为一棵k个点由k-1条割边连接成的树,倘若其中有一条边不是割边,则它必可与其他割边形成一个环,而能继续进行缩点。 有割点的图不一定有割边,如: 3是割点,分别与(1,2)和(4,5)形成两个无割点的块 有割边的图也不定有割点,如: w(1,2)为割边, 有向图 强连通分量:有向图中任意两点相互可达的连通子图,其实也相当于无向图中的缩点 二、算法 无向图 借助两个辅助数组dfn[],low[]进行DFS便可找到无向图的割点和割边,用一个栈st[]维护记录块和“缩点”后连通子图中所有的点。 dfn[i]表示DFS过程中到达点i的时间,low[i]表示能通过其他边回到其祖先的最早时间。low[i]=min(low[i],dfn[son[i]]) 设 v,u之间有边w(v,u),从v->u: 如果low[u]>=dfn[v],说明v的儿子u不能通过其他边到达v的祖先,此时如果拿掉v,则必定把v的祖先和v的儿子u,及它的子孙分开,于是v便是一个割点,v和它的子孙形成一个块。 如果low[u]>dfn[v]时,则说明u不仅不能到达v的祖先,连v也不能通过另外一条边直接到达,从而它们之间的边w(v,u)便是割边,求割边的时候有一个重边的问题要视情况处理,如果v,u之间有两条无向边,需要仍视为割边的话,则在DFS的时候加一个变量记录它的父亲,下一步遇到父结点时不扩展回去,从而第二条无向重边不会被遍历而导致low[u]==dfn[v] ,而在另外一些问题中,比如电线连接两台设备A,B 如果它们之间有两根电线,则应该视为是双连通的,因为任何一条电线出问题都不会破坏A和B之间的连通性,这个时候,我们可以用一个used[]数组标记边的id,DFS时会把一条无向边拆成两条有向边进行遍历,但我们给它们俩同一个id号,在开始遍历v->u前检查它的id是否在上一次u->v 时被标记,这样如果两点之间有多条边时,每次遍历都只标记其中一条,还可以通过其他边回去,形成第二条新的路 求割点的时候,维护一个栈st 每遍历到一个顶点v则把它放进去,对它的子孙u如果dfn[u]为0,则表示还没有遍历到则先DFS(u),之后再判断low[u]和dfn[v],如果low[u]>=dfn[v],则把栈中从栈顶到v这一系列元素弹出,这些点与v 形成一个块,如果u的子孙x也是一个割点,这样做会不会错把它们和v,u放在一起形成一个块呢,这种情况是不会发生的,如果发现x是一个割点,则DFS 到x那一步后栈早就把属于x的子孙弹出来了,而只剩下v,u的子孙,它们之间不存在割点,否则在回溯到v之前也早就提前出栈了!画一个图照着代码模拟一下可以方便理解。 求割边也是一样的。 浅谈强连通分量与拓扑排序的应用 浙江唐文斌摘要 强连通分量与拓扑排序是图论中最基础的算法之一。本文选取了两个简单但富有代表性的例子,说明这两个算法在一类图论问题中的应用。 [例一]Going from u to v or from v to u?1 给定一个有向图,问是否对于图中的任意两点u、v,总是存在u到v可达或者v到u (下文中将以a→b表示a到b可达)可达。图中点数不超过1000,边数不超过6000。 算法分析 题目描述很简单,我们最直观的想法就是求一个传递闭包,然后对于任意两点a、b判断是否a→b或者b→a。然而在本题中点数多达1000,传统的求传递闭包方法Floyd是行不通的。题目中的规模很小,似乎我们可以枚举起点s,并且从s开始对图进行一次宽度优先搜索,这样我们可以在O(N*(N+M))时间内求得传递闭包。似乎这个办法可行,但事实上,在本题中虽然规模小,但是数据组数高达200组,所以这个方法也是必然超时的。 我们抛开传递闭包,重新来看问题。题目中问是否对于任意两点都在至少一个方向上可达。那么如果两个点u、v,u→v且v→u,它们当然是符合要求的。所以我们第一个想法就是找到一个点集,该点集内所有点两两可达。由于其内部两两可达,所以我们可以将其缩成一个点,仅保留连向外界的边,并不会影响问题的本质。这个点集,就是强连通分量。所以我们的第一步操作就是:求图中所有的极大强连通分量,将每一个强连通分量缩成一个点,保留不同分量间的连边信息,得到一个新图。 我们对原图进行强连通分量缩点得到新图有什么好处呢?在这个过程中,我们将一些冗余信息进行了处理,得到的新图具有一个很重要的性质:无环(拓扑有序)。因为如果有环存在,那么这些环上的点都是互相可达的,所以它们应该同属于一个极大强连通分量,将被缩成一个点。所以我们现在的问题就是对于新图——一个拓扑有序的图,判断图中是否任意两点是否在至少一个方向上可达。 如果一个拓扑有序的图满足要求,那么它将拥有一些什么性质呢?我们先来看一些小规模的情况: (1)如果图只有一个点,则必然满足条件 (2)如果图中包含两个点,那么必须从一个点到另一个点有边相连。不妨设为a→b (显然b到a不可达)。 (3)如果图中包含3个点,不妨设第三个为c。那么必须满足c→a或者b→c。 通过上面3个情况的观察,我们大致就有了一个猜想: 1Poj Monthly Special – Jiajia&Wind’s story , problem G (POJ2762) 实验报告 课程名称数据结构 实验项目名称有向图的强连通分量 班级与班级代码14计算机实验班 实验室名称(或课室)实验楼803 专业计算机科学与技术 任课教师 学号: 姓名: 实验日期:2015年12 月03 日 广东财经大学教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日说明:指导教师评分后,实验报告交院(系)办公室保存。 一、实验目的与要求 采用邻接表存储的有向图。 二、实验内容 (1)创建N个节点的空图 DiGraph CreateGraph(int NumVertex)//创建一个N个节点的空图 { DiGraph G; G = malloc( sizeof( struct Graph ) ); if( G == NULL ) FatalError( "Out of space!!!" ); G->Table = malloc( sizeof( struct TableEntry ) * NumVertex ); if( G->Table == NULL ) FatalError( "Out of space!!!" ); G->NumVertex = NumVertex; G->NumEdge = 0; int i; for (i=0;i 【题17】计算连通性问题 输入一张无向图,指出该图中哪些顶点对之间有路。 输入: n (顶点数,1≤n ≤20) e (边数1≤e ≤210) 以下e 行,每行为有边连接的一对顶点 输出: k 行,每行两个数,为存在通路的顶点对序号i 、j(i 7.4.1无向图的连通分量和生成树。 void DFSForest(Graph G,CSTree &T) //建立无向图G的深度优先生成森林的 //(最左)孩子(右)兄弟链表T。 { T=NULL; for(v=0;v 求强连通分量的Kosaraju算法和Tarjan算法的比较 一、定义 在有向图中,如果两个顶点vi,vj间有一条从vi到vj的有向路径,同时还有一条从vj到vi的有向路径,则称两个顶点强连通(strongly connected)。如果有向图的每两个顶点都强连通,则称该有向图是一个强连通图。非强连通的有向图的极大强连通子图,称为强连通分量(strongly connected components)。 而对于一个无向图,讨论强连通没有意义,因为在无向图中连通就相当于强连通。 由一个强连通分量内的所有点所组成的集合称为缩点。在有向图中的所有缩点和所有缩点之间的边所组成的集合称为该有向图的缩图。 例子: 原图: 缩图: 上面的缩图中的 缩点1包含:1、2,;缩点2包含:3; 缩点3包含:4;缩点4包含:5、6、7。 二、求强连通分量的作用 把有向图中具有相同性质的点找出来,形成一个集合(缩点),建立缩图,能够方便地进行其它操作,而且时间效率会大大地提高,原先对多个点的操作可以简化为对它们所属的缩点的操作。 求强连通分量常常用于求拓扑排序之前,因为原图往往有环,无法进行拓扑排序,而求强连通分量后所建立的缩图则是有向无环图,方便进行拓扑排序。 三、Kosaraju算法 时间复杂度:O(M+N)注:M代表边数,N代表顶点数。 所需的数据结构:原图、反向图(若在原图中存在vi到vj的有向边,在反向图中就变成为vj到vi的有向边)、标记数组(标记是否遍历过)、一个栈(或记录顶点离开时间的数组)。 算法描叙: 步骤1:对原图进行深度优先遍历,记录每个顶点的离开时间。 步骤2:选择具有最晚离开时间的顶点,对反向图进行深度优先遍历,并标记能够遍历到的顶点,这些顶点构成一个强连通分量。 步骤3:如果还有顶点没有遍历过,则继续进行步骤2,否则算法结束。 hdu1269(Kosaraju算法)代码: #include 网络连通性算法 网络定义 节点与支路的集合,该集合中的节点与支路的连接关系可通过一节点-节点关联矩阵A 充分表达: A =[a ij ]n ×n i,j=1,2,…,n 式中:a ij =???间有支路直接相连。 与节点,当节点间无支路直接相连,与节点,当节点j i 1j i 0 n —网络节点数 连通性算法 理论算法: 称矩阵A 为网络一级连通矩阵,A 2为二级连通矩阵,…,A n-1为n-1级连通矩阵。 A 2=AA =[a 2ij ]n ×n i,j=1,2,…,n 式中:a 2ij =???相连。节点间有支路直接或经第 与节点,当节点相连,节点间无支路直接且经第与节点,当节点k 3j i 1 3j i 0k k=1,2,…,n ,k ≠i,j …… A n-1= 个1-?n A AA =[a n-1ij ]n ×n i,j =1,2,…,n 式中: a n-1ij =???-?-?个节点相连。,,,间有支路直接或经其它 与节点,当节点个节点相连,,,,间无支路直接且经其它与节点,当节点221j i 1 221j i 0n n 矩阵A n-1的每一线性无关的行或列中“1”元素对应的节点均处于同一连通子集中。 实际算法: 若矩阵A 第i (i=1,2,…,n )行元素与第j (j=i+1,i+2,…,n )行元素中第k 列元素a ik 和a jk 同为“1”,则第j 行中的其它“1”元素均填入第i 行的相应列中。结果矩阵A 第i 行中所有“1”元素对应的节点处于同一连通子集中。 数据定义 Nc —元件数 Nd —节点数 NOD (Nc,3)—每个元件的节点编号i 、j 、k KND (Nc )—每个元件的种类(断路器、隔离开关、母线、线路、变压器……) CNT (Nc )—每个开关元件的分、合状态(逻辑型,例如:合为“真”,分为“假”) NDS0(Nd )—每个节点初始所在连通子集编号 NDS (Nd )—每个节点所在连通子集编号 NCT0(Nc )—每个元件初始所在连通子集编号 算法总结 一、动态规划和递推 dp一般的解题步骤: 分析问题,弄清题意——从原问题中抽象出模型——根据模型设计状态,要求状态满足最优子结构和无后效性——直接设计状态有难度的话则需要考虑转化模型——根据设计的状态考虑转移——如果过不了题目要求的数据范围,则需要考虑优化 由于动态规划涉及的内容太多,只言片语难以讲清,所以附件中放了很多篇关于动态规划的文章,大部分系原创,并附上了一些经典的论文,主要讲了DP的优化,一些特殊的状态设计技巧 Dp和递推没有本质区别,都是用一些状态来描述问题,并记录下一些信息,根据已知信息推出未知信息,直到得到问题的解 关于DP的优化有两篇神级论文,放在附件里面了,写的非常好。 二、图论及网络流 最小生成树:克鲁斯卡尔算法和普利姆算法, ——重要性质1:最小生成树上任意两点的路径的最大边最小 ——重要性质2:最小生成树的多解(方案个数)只与相同权值的的边有关(省队集训题生成树计数) 最短路:spfa算法、堆+迪杰斯特拉算法 Spfa算法是基于松弛技术的,随机图效果极佳,最坏(网格图或存在负权环)O(nm),适用于任意图,能够判断负权环 ——判负权环的方法:记录每个点当前从原点到它的最短路上边的条数,如果某次更新后这个条数>n-1则存在负权环 堆+迪杰斯特拉则是用了贪心的思想,不断扩大确定dist的集合,同时更新dist,如果边权有负值就不能做,复杂度是O((n+m)logn)的 拓扑排序:可以将有向图转化为一个线性的序列,满足一个点所有的前驱结点都出现在这个点在序列中的位置之前。可以判断这个有向图是否有环 ——一个简单而实用的扩展:给树做类top排序,可以有类似的功能,即每次去掉叶子结点,将树转化为一个具有拓扑关系的序列 ——再扩展:树同构判断,可用类top确定树根是谁,再最小表示法+hash即可 强连通分量、缩点:tarjan算法 核心是每个点记一个时间戳ti[i], 另外low[i]表示i点能延伸出的搜索树中节点的ti[i]的最小值,还要维护个栈记当前路径上的点,low[i]初始化为ti[i],如果搜完i了,ti[i]=low[i]则当前栈顶到i的所有点会在一个强连同分量内。 求强连通分量的tarjan算法 强连通分量:是有向图中的概念,在一个图的子图中,任意两个点相互可达,也就是存在互通的路径,那么这个子图就是强连通分量。(如果一个有向图的任意两个点相互可达,那么这个图就称为强连通图)。 如果u是某个强连通分量的根,那么: (1)u不存在路径可以返回到它的祖先。 (2)u的子树也不存在路径可以返回到u的祖先。 ?例如: ?强连通分量。在一个非强连通图中极大的强连通子图就是该图的强连通分量。比如图中子图{1,2,3,5}是一个强连通分量,子图{4}是一个强连通分量。 tarjan算法的基础是深度优先搜索,用两个数组low和dfn,和一个栈。low数组是一个标记数组,记录该点所在的强连通子图所在搜索子树的根节点的dfn值,dfn数组记录搜索到该点的时间,也就是第几个搜索这个点的。根据以下几条规则,经过搜索遍历该图和对栈的操作,我们就可以得到该有向图的强连通分量。 算法规则: ?数组的初始化:当首次搜索到点p时,Dfn与Low数组的值都为到该点的时间。 ?堆栈:每搜索到一个点,将它压入栈顶。 ?当点p有与点p’相连时,如果此时(时间为dfn[p]时)p’不在栈中,p 的low值为两点的low值中较小的一个。 ?当点p有与点p’相连时,如果此时(时间为dfn[p]时)p’在栈中,p的low值为p的low值和p’的dfn值中较小的一个。 ?每当搜索到一个点经过以上操作后(也就是子树已经全部遍历)的low 值等于dfn值,则将它以及在它之上的元素弹出栈。这些出栈的元素组成一个强连通分量。 ?继续搜索(或许会更换搜索的起点,因为整个有向图可能分为两个不连通的部分),直到所有点被遍历。 算法伪代码: tarjan(u) { DFN[u]=Low[u]=++Index // 为节点u设定次序编号和Low初值 Stack.push(u) // 将节点u压入栈中 for each (u, v) in E // 枚举每一条边 if (!dfn[v]) // 如果节点v未被访问过 { tarjan(v) // 继续向下找 Low[u] = min(Low[u], Low[v]) } else if (v in S) // 如果节点v还在栈内 Low[u] = min(Low[u], DFN[v]) if (DFN[u] == Low[u]) // 如果节点u是强连通分量的根 do{ v = S.pop // 将v退栈,为该强连通分量中一个顶点}while(u == v); } 演示算法流程; 有向图的强连通分量 分类:C/C++程序设计2009-04-15 16:50 2341人阅读评论(1) 收藏举报最关键通用部分:强连通分量一定是图的深搜树的一个子树。 一、Kosaraju算法 1.算法思路 基本思路: 这个算法可以说是最容易理解,最通用的算法,其比较关键的部分是同时应用了原图G和反图G T。(步骤1)先用对原图G进行深搜形成森林(树),(步骤2)然后任选一棵树对其进行深搜(注意这次深搜节点A能往子节点B走的要求是E AB存在于反图G T),能遍历到的顶点就是一个强连通分量。余下部分和 原来的森林一起组成一个新的森林,继续步骤2直到没有顶点为止。7 改进思路: 当然,基本思路实现起来是比较麻烦的(因为步骤2每次对一棵树进行深搜时,可能深搜到其他树上去,这是不允许的,强连通分量只能存在单棵树中(由开篇第一句话可知)),我们当然不这么做,我们可以巧妙的选择第二深搜选择的树的顺序,使其不可能深搜到其他树上去。想象一下,如果步骤2是从森林里选择树,那么哪个树是不连通(对于G T来说)到其他树上的 呢?就是最后遍历出来的树,它的根节点在步骤1的遍历中离开时间最晚,而且可知它也是该树中离开时间最晚的那个节点。这给我们提供了很好的选择,在第一次深搜遍历时,记录时间i离开的顶点j,即numb[i]=j。那么,我们每次只需找到没有找过的顶点中具有最晚离开时间的顶点直接深搜(对于G T来说)就可以了。每次深搜都得到一个强连通分量。 隐藏性质: 分析到这里,我们已经知道怎么求强连通分量了。但是,大家有没有注意到我们在第二次深搜选择树的顺序有一个特点呢?如果在看上述思路的时候,你的脑子在思考,相信你已经知道了!!!它就是:如果我们把求出来的每个强连通分量收缩成一个点,并且用求出每个强连通分量的顺序来标记收缩后的节点,那么这个顺序其实就是强连通分量收缩成点后形成的有向无环图的拓扑序列。为什么呢?首先,应该明确搜索后的图一定是有向无环图呢?废话,如果还有环,那么环上的顶点对应的所有原来图上的顶点构成一个强连通分量,而不是构成环上那么多点对应的独自的强连通分量了。然后就是为什么是拓扑序列,我们在改进分析的时候,不是先选的树不会连通到其他树上(对于反图GT来说),也就是后选的树没有连通到先选的树,也即先出现的强连通分量收缩的点只能指向后出现的强连通分量收缩的点。那么拓扑序列不是理所当然的吗?这就是Kosaraju算法的一个隐藏性质。 强联通分量与模拟链表 作者:逸水之寒 1.强连通分量 强连通分量的定义是:在有向图中,u可以到达v,但是v不一定能到达u,如果u,v 到达,则他们就属于一个强连通分量。 求强连通分量最长用的方法就是Kosaraju算法,比较容易理解而且效率很高,本文对强连通分量的求法均采用Kosaraju算法。 其主要思想:首先对原图G进行深搜形成森林(树),然后选择一棵树进行第二次深搜,注意第一次是要判断节点A能不能通向节点B,而第二次要判断的是节点B能不能通向A,能遍历到的就是一个强连通分量。(附录给出伪代码) Kosaraju算法如果采用了合适的数据结构,它的时间复杂度是O(n)的。相关题目有很多,例如USACO 5.3.3,2009NOIP Senior No.3。下面将以USACO 5.3.3 schlnet 举例说明。 Preblem 1. Network of Schools (USACO 5.3.3 schlnet\IOI96 No.3) A number of schools are connected to a computer network. Agreements have been developed among those schools: each school maintains a list of schools to which it distributes software (the "receiving schools"). Note that if B is in the distribution list of school A, then A does not necessarily appear in the list of school B. You are to write a program that computes the minimal number of schools that must receive a copy of the new software in order for the software to reach all schools in the network according to the agreement (Subtask A). As a further task, we want to ensure that by sending the copy of new software to an arbitrary school, this software will reach all schools in the network. To achieve this goal we may have to extend the lists of receivers by new members. Compute the minimal number of extensions that have to be made so that whatever school we send the new software to, it will reach all other schools (Subtask B). One extension means introducing one new member into the list of receivers of one school. M Tarjan 算法的总结 tarjan 专题 这是我在博客里整 理的有关tarjan 的内容。 最主要的分为两个板块,有向图和无向图 一、有向图 1 ?缩点、强连通分量代码和注释 如果在一个有向图中,任意两个节点可以互相到达,那么这些点和它们之间的边构成的 图叫强连通分量,如果这些边没有边权,等价于一个点,如洛谷P2812校园网络。如果这 些点有点权,那么它们所缩成的点最大点权等于强连通分量中点权之和,见洛谷P3387缩 点。 对于求强连通分量,我们由tarjan 算法来实现。首先对每个没有遍历过的点为起点,进 行dfs ,每找到一个新点入栈一次,如果遍历到了已经遍历过的点,说明这个被二次遍历的 点可以通过一个有xy4hs wjyyy O 、tarjan 算法的大纲 厂 有向图 1 ?缩点 tarja n< 〔2.强连通分量二> 3.环 树二> 4./ca 无向图2桥/害ij 边二> 5 ?边双连通分量 割点二> 6 ?点双连通 分量 I ------------------- 7缩点 向环回溯到自己。如果回溯所找到的时间戳小于自己所能回溯找到的最小时间戳(默认为自己的时间戳),那么将自己的回溯时间戳更新到更小。 当dfs的递归回溯到自己时,将自己的回溯时间戳更新到子节点和自己中最小的一个,如果无法更新到比自己更小,说明自己是一个强连通分量的根结点,把栈中所有自己以上的点全部出栈,认为在同一个强连通分量中,根据题目需要进行处理。如果可以更新到更小,就把自己留在栈里,继续递归。 2 ?环 在有向图中,我们一般找的是最小环,用一遍dfs就可以完成。不需要栈,只需要一个dfn数组。利用记忆化搜索的技巧,如果遍历到一个被搜过的点,它一定不能更新最小环为更小值,因为它的子树已经被遍历完了。在遍历过程中,用bfs序给各节点打上时间戳,就可以求出最小环的长度了。 二、无向图 1. 树的最近公共祖先(lea )和树上点的距离 最近公共祖先详解树上距离例题 最近公共祖先(和树上距离)是可以通过倍增在0(NlogN)时间内跳出来的,不过是离线算法。tarjan相比较更优,不仅是在线算法,而且一遍dfs复杂度只需要0(N)。用到的技巧有并查集、前缀和等。在dfs过程中,对于一个子树的根结点,它的所有孩子与它自己的最近公共祖先都是它自己,所以先不把当前祖先更新到子树的根结点的父亲。等dfs结束后,子树内的询问处理完毕, 课程设计报告 课程设计名称:数据结构课程设计 课程设计题目:实现求有向图强连通分量的算法 院(系): 专业: 班级: 学号: 姓名: 指导教师: 沈阳航空航天大学课程设计报告 目录 1 系统分析 (1) 1.1题目介绍 (1) 1.2功能要求 (1) 2 概要设计 (2) 2.1流程图 (2) 2.2结构体说明 (2) 3 详细设计 (3) 3.1遍历函数设计 (3) 3.1.1 Kosaraju算法基本思路: (3) 3.1.2伪代码 (4) 3.2调试分析和测试结果 (6) 3.2.1调试分析 (6) 3.2.2测试结果 (6) 参考文献 (8) 附录(关键部分程序清单) (9) 沈阳航空航天大学课程设计报告 1 系统分析 1.1 题目介绍 在键盘上输入有向图,对任意给定的图(顶点数和边数自定),建立它的邻接表并输出。然后判断该图是否强连通。如果是强连通图,求出该图的所有强连通分量并输出字符。 1.2 功能要求 首先输入图的类型,有向图(因为遍历与权值无关,所以没有涉及带权图)。然后输入图的顶点数、边数和各条边,之后生成该图的邻接表并输出。 再输入要遍历该图的起点,然后从所输入的点深度搜索该图的十字链表,并按遍历顺序输出顶点内容。之后决定是否继续遍历该图或输入另一个需要遍历的图亦或是结束程序。 要求采取简单方便的输入方式。并且系统要求提供观察有向图图形结构和各强连通分量结构的功能。 2 概要设计 2.1 流程图 根据程序要求,设计流程图如下: 图2.1——流程图 2.2 结构体说明 //有向图十字链表存储表示 typedef struct arcbox int tailvex,headvex;//该弧的尾和头顶点的位置 图的割点、桥与双连通分支 [点连通度与边连通度] 在一个无向连通图中,如果有一个顶点集合,删除这个顶点集合,以及这个集合中所有顶点相关联的边以后,原图变成多个连通块,就称这个点集为割点集合。一个图的点连通度的定义为,最小割点集合中的顶点数。 类似的,如果有一个边集合,删除这个边集合以后,原图变成多个连通块,就称这个点集为割边集合。一个图的边连通度的定义为,最小割边集合中的边数。 注:以上定义的意思是,即有可能删除两个或两个以上点的时候才能形成多个连通块! [双连通图、割点与桥] 如果一个无向连通图的点连通度大于1,则称该图是点双连通的(point biconnected),简称双连通或重连通。一个图有割点,当且仅当这个图的点连通度为1,则割点集合的唯一元素被称为割点(cut point),又叫关节点(articulation point)。 如果一个无向连通图的边连通度大于1,则称该图是边双连通的(edge biconnected),简称双连通或重连通。一个图有桥,当且仅当这个图的边连通度为1,则割边集合的唯一元素被称为桥(bridge),又叫关节边(articulation edge)。 可以看出,点双连通与边双连通都可以简称为双连通,它们之间是有着某种联系的,下文中提到的双连通,均既可指点双连通,又可指边双连通。 [双连通分支] 在图G的所有子图G’中,如果G’是双连通的,则称G’为双连通子图。如果一个双连通子图G’它不是任何一个双连通子图的真子集,则G’为极大双连通子图。双连通分支(biconnected component),或重连通分支,就是图的极大双连通子图。特殊的,点双连通分支又叫做块。 图论之 Tarjan及其应用 一、Tarjan应用 1.求强连通分量 2.求lca 3.无向图中,求割点和桥 二、图的遍历算法 (一)、宽度优先遍历(BFS) 1、给定图G和一个源点s, 宽度优先遍历按照从近到远的顺序考虑各条边. 算法求出从s到各点的距离。 宽度优先的过程对结点着色. 白色: 没有考虑过的点(还没有入队的点) 黑色: 已经完全考虑过的点(已经出队的点) 灰色: 发现过, 但没有处理过, 是遍历边界(队列中的点) 依次处理每个灰色结点u, 对于邻接边(u, v), 把v着成灰色并加入树中, 在树中u是v的父亲(parent)或称前驱(predecessor). 距离d[v] = d[u] + 1 整棵树的根为s (二)、深度优先遍历(DFS) 1、初始化: time为0, 所有点为白色, dfs森林为空 对每个白色点u执行一次DFS-VISIT(u) 时间复杂度为O(n+m) 2、伪代码 三、DFS树的性质 1、括号结构性质 对于任意结点对(u, v), 考虑区间[d[u], f[u]]和[d[v], f[v]], 以下三个性质恰有一个成立: 完全分离 u的区间完全包含在v的区间内, 则在dfs树上u是v的后代 v的区间完全包含在u的区间内, 则在dfs树上v是u的后代 2、定理(嵌套区间定理): 在DFS森林中v是u的后代当且仅当d[u] 名词解释 数据结构 数据结构是相互之间存在一种或多种特定关系的数据元素的集合。 集合 集合是指数据元素之间除了同属一个集合的关系外,别无其他关系。 逻辑结构 数据的逻辑结构是对数据之间关系的描述,它与数据的存储结构无关,同一种逻辑结构可以有多种存储结构。 物理结构(存储结构) 物理结构又称为数据的存储结构,是指数据的逻辑结构在计算机中的表示(又称映像),它包括数据元素的表示和关系的表示。 算法 算法是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个或多个操作。 线性表 线性表是最常用且最简单的一种数据结构,是n个数据元素的有限序列。 串 串是由零个或多个字符组成的有限序列。 栈 栈是限定仅在表尾进行插入或删除操作的线性表。 队列 队列是一种先进先出的线性表。 递归 一个直接调用自己或通过一系列的调用语句间接地调用自己的函数。 二叉树 二叉树是一种每个结点至多有两颗子树,并且子树有左右之分,次序不能颠倒的树型结构。 满二叉树 深度为k,且有2k-1个结点的二叉树。 完全二叉树 深度为k,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中的编号从1到n的结点一一对应时,称之为完全二叉树。 森林 m棵互相不相交的树的集合,对树中每个节点而言,其子树的集合即为森林。 树的路径长度 树中每个结点到根结点的路径长度之和. 树的带权路径长度(WPL) 树中所有叶子结点的带权路径长度之和. 哈夫曼树(最优二叉树) 设有n个权值的结点构造一棵有n个叶子结点的二叉树,其中WPL最小的那棵树,为哈夫曼树。 哈夫曼编码 一般以N种字符出现的频率做权值,构造哈付曼树,左孩子边做0,右孩子边做1,那么从根到叶子结点经过的0和1序列,构成了哈夫曼编码。 前缀编码 任何一个字符的编码都不是另一个字符编码的前缀,这种编码叫做前缀编码。 线索二叉树 对二叉树以某种次序进行遍历并加上线索的过程叫做线索化。线索化了的二叉树称为线索二叉树。 生成树 一个连通图的生成树是指一个极小连通子图,它含有图中的全部顶点,N-1条边。 最小生成树 在图G的所有生成树中,树权值最小的那棵生成树,称作最小生成树。08-图论-离散数学讲义-海南大学(共十一讲)
连通图的割点、割边(桥)、块、缩点,有向图的强连通分量
浅谈强连通分量与拓扑排序的应用
有向图的强连通分量
【题17】计算连通性问题--试题解析
7.4.1无向图的连通分量和生成树
求强连通分量的Kosaraju算法和Tarjan算法的比较 by ljq
拓扑-网络连通性算法
noip算法总结2016
求强连通分量tarjan算法讲解
有向图的强连通分量算法
强连通分量与模拟链表
对Tarjan算法复习总结.doc
实现有向图强连通分量的算法 数据结构课程设计报告
算法学习:图论之图的割点,桥,双连通分支
图论之 Tarjan及其应用
重要数据结构名词解释