搜索引擎与PageRank算法数模论文终稿

福建农林大学计算机与信息学院
(数学类课程)
课程论文报告
课程名称:数学模型
课程论文题目:搜索引擎与PageRank
姓名:魏福鹏
系:应用数学
专业:数学与应用数学
年级:2011级
学号:3116002054
指导教师:姜永
职称:副教授
2013年10月31日
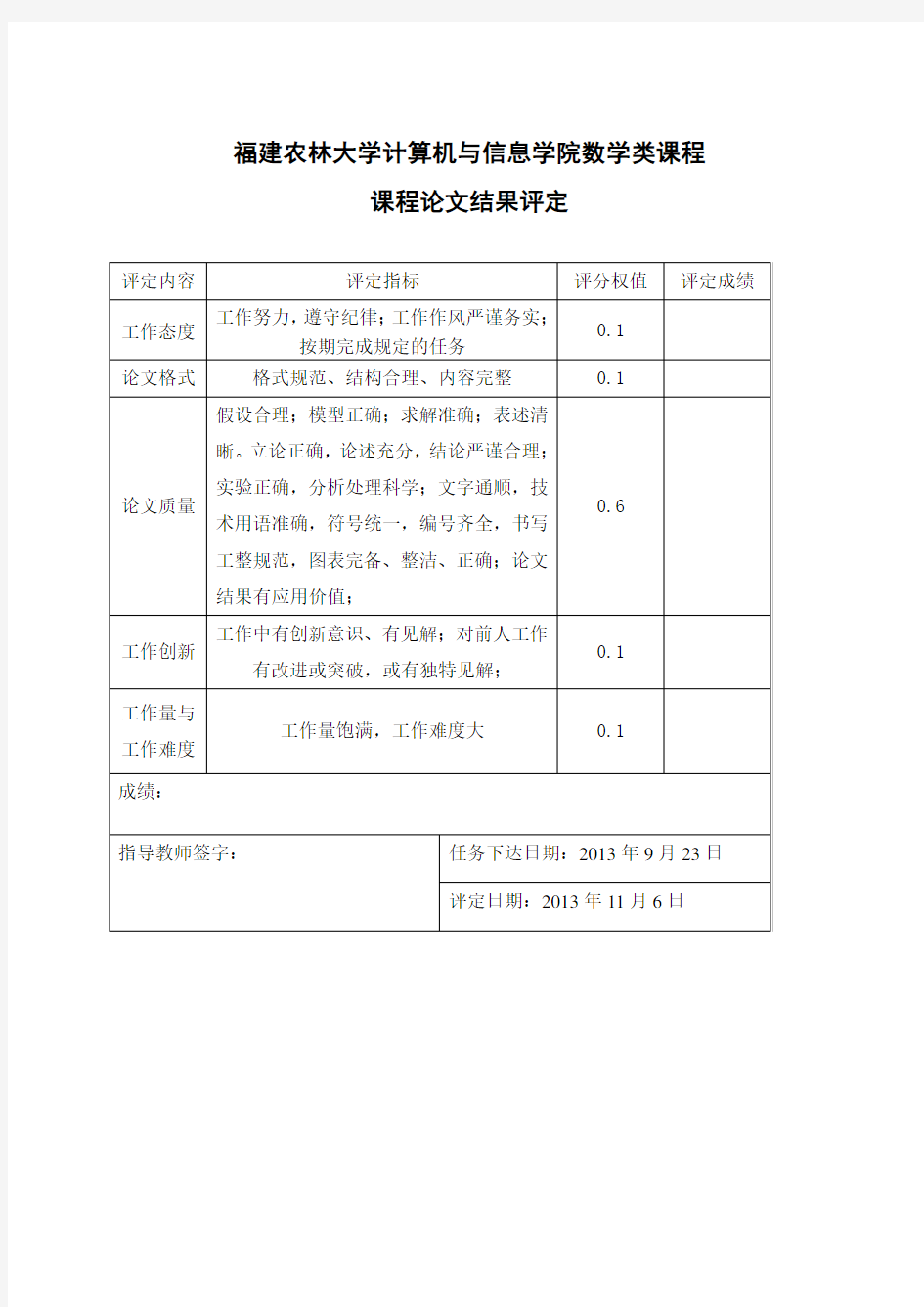
福建农林大学计算机与信息学院数学类课程
课程论文结果评定
目录
摘要 (1)
关键词 (1)
一、问题的重述 (2)
二、模型的假设 (2)
三、符号说明 (2)
四、模型的建立与求解............................................................................................... 错误!未定义书签。
4.1模型建立 (3)
4.1.1问题一 (3)
4.1.2 问题二 (5)
4.1.3 问题三 (5)
4.2模型求解 (6)
4.2.1问题一 (6)
4.2.2问题二 (6)
4.2.3问题三 (6)
五、模型的评价 (6)
六、模型的改进及推广 (6)
七、参考文献 (6)
附录 (6)
8.1附件一: (6)
8.2附件二: (6)
8.3附件三: (9)
搜索引擎与PageRank
摘 要
本文是一篇关于经费的使用计划模型。在现实经济高速发展的背景下,人们越来越重视生产、投资、规划等实际应用项目,而其中一个合理的的数学应用模型就是项目完成度的最大保障。
本文通过分析,把求经费的最佳使用方案问题转化为求n 年所得利息最大时的投资配置问题,在求最大利息的过程中,我们将投入项目不同期限看成不同的投资项目,收益高的优先得到资金。我们根据分析,采用搜索算法解决这个最优化问题。
为了尽可能的使资金被利用,我们总是把扣除奖金后所余的现有资金全部用来购买国库券或者存款。由于银行的存款和买国库券的最大期限不大于五年,而我们所面对的是一个十年的基金投资计划,所以我们把时间分为两个五年来考虑。又因针对第三个情况假设下(学校在基金到位后的第8年(2010年)要举行建校50周年校庆,基金会希望这一年的奖金比其它年度多20%。),我们的解答将对其相应的参数做处理。
本文给出了经费使用方案的数学模型。对于基金M 使用n 年的情况而言,首先把基金M 分成n 份()j n m ,,(()j n m ,:计划中第n 年投资于存款的存期为j 的资金,其中5,3,2,1,2
1=j )。这样,对前面的1-n 年,第i 年终时()j n m ,到期,将()j n m ,及其利息均取出来作为当年的奖金发放;而第n 年,则用除去M 元所剩下的钱作为第n 年的奖金发放,当基金按最佳投资策略投资n 年后的本金与收益金的和等于当年的奖金数与原基金M 之和时,每年发放的奖金数将达到最大值。而对于问题二,我们把基金M 分成n 份()j n m ,和n 份()t n g ,,(计划中第n 年投资于国库券的周期为t 的资金,其中5,3,2=t )和每年都有的一部分??? ??21,1m ,其中到期的()j n m ,和到期的()t n g ,经过半年定期存款也
可用于年初的奖金发放。问题三则是问题二的一个特殊情况,校庆时奖金数额比其他年多20%的问题分析方法和模型的解决方法只要稍加条件限制就可以达到。
关键词:搜索算法;最优化问题;分段考虑;LONGO 软件;
一、问题的重述
世界最受欢迎的网站恐怕以各大搜索引擎为首,以Google 为例,日访问量在5亿次以上。如何在茫茫互联网中找到用户所关心的网页,是各个搜索引擎的主要职能,假如你是搜索引擎的建设者,找到与用户输入的关键词大概匹配的网页并非难事,但这些网页的数目可能数以亿计,而一般用户只会有耐心浏览前五页大约五十个结果,所以如何对数以亿记的相关网页进行排序成为搜索引擎算法的核心问题。
一个搜索引擎的算法,要考虑很多的方面。主要是“域名、密度、内链、外链、相关度、服务器稳定、内容更新、域名时间、内容数量”这些方面。不同的搜索引擎侧重点也不同,比如Google ,它对收录的网站有一个重要性排名的指数,被称为PageRank ,作为对搜索网页排序的重要参数。
请就搜索引擎与PageRank 考虑如下问题:
1. 考察Google 的PageRank 算法,建立数学模型,给出你认为合理的Pagerank 的计算方法;
2. 如果你是搜索引擎的建设者,请考虑你会侧重考虑搜索网页的那些方面,给出你对搜索网页进行排序的方法;
3. 如果你是某新网站的建设者,请考虑使你的网站在第2题中你建立的搜索引擎中排名靠前的方法。
二、模型的假设
1. 只考虑网页间的超链关系,并仅仅以此进行网页重要度的分析。
2. 不考虑网页本身内容特征对权值的影响
3. 网页之间的链入链出量能反映实际情况
4. 假设网页集合的主体之间有相关性,并且体现在他们的相互链接上
5. 假设用户顺序浏览网页,不考虑他们在网页上驻留的时间。
6.
三、符号说明
()j n m , 计划中第n 年投资于存款的存期为j 的资金,其中5,3,2,1,2
1=j (单位:万元) ()t n g , 计划中第n 年投资于国库券的周期为t 的资金,其中5,3,2=t (单位:万元) M 初始时某大学基金会的总金额(单位:万元)
N 每年该大学基金所要支出的奖金总额(单位:万元)
j r 存款中存储周期j 年的年实际收益利率
t s
购买国库券周期为t 的年实际收益率
四、问题分析
4.1.1问题一
PageRank 算法是Google搜索引擎的对检索结果的一种排序算法。它的基本思想主要是来自传统文献计量学的文献引文分析,即一篇文献的质量和重要性可以通过其它文献对其引用的数量和引文质量来衡量,也就是说,一篇文献被其它文献引用越多,并且引用它的文献的质量越高,则该文献本身就越重要。Google在给出页面排序时也有两条标准:一是看有多少超级链接指向它;二是要看超级链接指向它的那个页面重要不重要。这两条直观的想法就PageRank算法的数学基础,也是Google搜索引擎最基本的工作原理。
PageRank算法利用了互联网独特的超链接结构。在庞大的超链接资源中, Google 提取出上亿个超级链接页面进行分析,制作出一个巨大的网络地图。具体的讲,就是把所有的网页看作图里面相应的顶点,如果网页A有一个指向网页B的链接,则认为一条从顶点A到顶点B的有向边。这样就可以利用图论来研究网络的拓扑结构。
PageRank算法正是利用网络的拓扑结构来判断网页的重要性。。
通过下面的图我们来具体地看一下刚才所阐述的思想。具体的算法是,将某个页面的页面等级值 PageRank 除以从该网页出发的超链接数,由此得到的值分别和超链接所指向的页面已有的页面等级值 PageRank 相加,即得到了被链接的页面的 PageRank。
4.1.2问题二
4.1.3问题三
五、模型的建立与求解
5.1模型建立
5.1.1问题一
5.1.1.1 PageRank 算法
PageRank 算法的具体实现可以利用网页所对应的图的邻接矩阵来表达超链接关系。为此,首先写出所对应图的邻接矩阵A。为了能将网页的页面等级值平均分配给该网页所链接指向的网页,对各个行向量进行归一化处理,得矩阵A。PageRank算法的矩阵是
将归一化所得矩阵A 转置所得矩阵T A W =。这样形成的矩阵W 被称为转移概率矩阵,它各个列向量之和为全概率1, 各个行矢量表示状态之间的转移概率。转移概率矩阵与 Markoff 过程有着密切的联系。转置的理由是, PageRank 算法并非重视链接到多少页面,而是重视被多少页面链接。各个网页的页面等级值 PageRank 的计算,就是求这个转移概率矩阵W 的最大特征值所属的特征向量。
现在以前面给出的三个页面之间的超链接关系为例,说明PageRank 算法如何计算给定网页的页面等级值PageRank ,从而定量地知道哪些网页是最重要的。
算法的具体实现可以利用网页所对应的图的邻接矩阵来表达链接关系。为此,首先写出所对应图的邻接矩阵
????? ??=001100110A
为了能将网页的页面等级值平均分配给该网页所链接指向的网页,对各个行向量进行归一化处理,得
??????
? ??=00110021210A 将归一化所得的矩阵A 转置,所得到的转移概率矩阵()ij w W =为 ?????
? ??==01210021100T A W 现给每个页面i P 一个 PageRank 值i x ,这些PageRank 值链接到该页面的那些页面的PageRank 值确定,即
i j j ij
x x w λ=∑=31
(1) 其中λ为归一化因子。令()T x x x x 321,,=,则由矩阵乘法(1)可以写成
x Wx λ=
由此求出转移概率矩阵的最大正特征值1=λ,相应非负特征向量()T
x 1,21,1=,由此可以确定网页得排序为 C ,A ,B ,其中页面 A ,C 的排序无显著差别,之所以将 C 排在前面是因为指向C 的超链接数更多一些。
5.1.1.2 随机冲浪模型
PageRank 算法原理中有一个重要的假设: 所有的网页形成一个闭合的链接图,除了这些文档以外没有其他任何链接的出入,并且每个网页能从其他网页通过超链接达到。但是在现实的网络中,并不完全是这样的情况。当一个页面没有出链的时候,它的
PageRank 值就不能被分配给其它的页面。同样道理,只有出链接而没有入链接的页面也是存在的。但 PageRank 并不考虑这样的页面, 因为没有流入的PageRank 而只流出的 PageRank ,从对称性角度来考虑是很奇怪的。同时,有时候也有链接只在一个集合内部旋转而不向外界链接的现象。在现实中的页面,无论怎样顺着链接前进,仅仅顺着链接是
绝对不能进入的页面群总归是存在的。
PageRank 技术为了解决这样的问题,提出用户的随机冲浪模型(Random Surfer Model ): 用户虽然在大多数场合都顺着当前页面中的链接前进,但有时会突然重新打开浏览器随机进入到完全无关的页面里。PageRank 算法认为:用户在85%的情况下沿着链接前进,但在15%的情况下会跳跃到无关的页面中。用公式表示相应的转移概率矩阵为
()T ee n d dW W -==1
其中,e 为分量全为1的n 维列向量,
从而T ee 为全1 矩阵,()1,0∈d 为权重因子(damping factor ),在实际中Google 取85.0=d 。也就是说,在随机冲浪模型中,求各个页面等级PageRank 值的问题变成了求正矩阵W 的最大特征值所属的特征向量问题。根据著名的 Perron -Frobenius 定理,转移概率矩阵W 的最大正特征值是1。同时注意到,在随机冲浪模型中,页面的PageRank 值即冲浪者随机打开浏览器能访问到该页面的概率,可以由网页的总数来权衡,为计算方便不妨设n x n
i i =∑=1。由此可得相应特征向量问题的分
量形式为
()j n
j ij i x w d d x ∑=+-=11 (2)
注意该(2)式是递归定义的。在实际计算过程中,可以先给每一个网页赋一个初始 PageRank 值,然后根据PageRank 算法进行递归计算,直至相邻两次计算的差值相差小于某一个值就可以了。
还是考虑前面给出的三个网页 A 、B 、C 之间的超链接关系,在随机冲浪模型下为方便计算令5.0=d ,相应的转移概率矩阵为
()????
? ??=-==1667.06667.04167.01667.01667.04167.06667.01667.01667.035.015.0T ee W W 易知W 的最大特征为1,相应的特征向量为()T
6572.0,4381.0,6134.0。 若根据 Perron -Frobenius 定理考虑特征向量问题x x W =分量形式,则为计算方便假设31=∑=n
i i x ,得
()()?????++=?+=+=213
12315.05.05.05.05.05.05.05.0x x x x x x x
解此方程组可得各个页面的PageRank 值为()T
x 1315,1310,1314=。由此可以确定网页的排序为 C ,A ,B 。可见随机冲浪模型下的排序结果更合理一些。
4.1.2 问题二
4.1.3 问题三
4.2模型求解
然后在LINGO运行后求得如下结果:(具体运行过程及输出见附件)
4.2.1问题一
4.2.2问题二
4.2.3问题三
五、模型的评价
本文相较于普遍情况,针对基金的操作,我们进行了五年为一期的规律总结,设定了以五年为一个周期的初始假设,同时对于国库券的购买我们也设定为每年在六月末发行且即时购买,从七月一日起开始计息,并且假设定期存款和国库券无法提前支取,但是相较于实际情况,需要考虑提前支取这一情况。而以五年为一期虽然便于推广,但是实际情况可能会更加复杂,需要对期限等进行限制。
就本题而言,建立的模型可以较好的完成对基金的最优化使用,同时可以很明确的展现在过程中,每一批基金的投资方向和最终收益情况,便于投资的比较和追踪。
六、模型的改进及推广
可以进一步细化参数设定,不仅仅以五年为一期,可以在更长或更短的整数或非整数投资期内进行基金的使用优化。同时可以在实际情况下,更细化的考虑基于投资风险的风险规避等问题,在投资数额等问题上根据需要进行限制,以期达到更完善和稳定的投资计划。
参考文献
[1] 姜启源等;数学模型(第四版)[M];高等教育出版杜;2011.1
[2] 《中华人民共和国国库券条例》
[3]李少猛,赵玉庆,徐晶;基金最佳使用计划[J];工程数学学报,2002年2月
[4]陈恩水,孙志忠;“基金使用计划"模型和评述[J];工程数学学报,2002年2月
[5]潘国祥,刘智宾,李皓;基金存储方案[J];工程数学学报,2002年2月
附录
8.1附件一:
8.2附件二:
model:
max=z;
x10+x11+x12+x13+x15<=5000.00;
y12+y13+y15<=1.00945*x10;
x20+x21+x22+x23+x25<=x11*1.01584-z;
y22+y23+y25<=1.00945*x20;
x30+x31+x32+x33+x35<=x21*1.01584+x12*1.036-z;
y32+y33+y35<=1.00945*x30;
x40+x41+x42+x43+x45<=x31*1.01584+x22*1.036+x13*1.06048+1.00945*1.045*y1 2-z;
y42+y43+y45<=1.00945*x40;
x50+x51+x52+x53+x55<=x41*1.01584+x32*1.036+x23*1.06048+1.00945*1.045*y2 2+1.00945*1.0756*y13-z;
y52+y53+y55<=1.00945*x50;
x60+x61+x62+x63+x65<=x51*1.01584+x42*1.036+x33*1.06048+x15*1.1116+1.009 45*1.045*y32+1.00945*1.0756*y23-z;
y62+y63<=1.00945*x60;
x70+x71+x72+x73<=x61*1.01584+x52*1.036+x43*1.06048+x25*1.1116+1.00945*1 .045*y42+1.00945*1.0756*y33+1.00945*1.1395*y15-z;
y72+y73<=1.00945*x70;
x80+x81+x82+x83<=x71*1.01584+x62*1.036+x53*1.06048+x35*1.1116+1.00945*1 .045*y52+1.00945*1.0756*y43+1.00945*1.1395*y25-z;
y82<=1.00945*x80;
x91+x92<=x81*1.01584+x72*1.036+x63*1.06048+x45*1.1116+1.00945*1.045*y62 +1.00945*1.0756*y53+1.00945*1.1395*y35-z;
x101<=x91*1.01584+x82*1.036+x73*1.06048+x55*1.1116+1.00945*1.045*y72+1. 00945*1.0756*y63+1.00945*1.1395*y45-z;
5000.00=x101*1.01584+x92*1.036+x83*1.06048+x65*1.1116+1.00945*1.045*y82 +1.00945*1.0756*y73+1.00945*1.1395*y55-z;
end
运行后,显示如下:
Global optimal solution found.
Objective value: 121.2505
Infeasibilities: 0.000000
Total solver iterations: 22
Variable Value Reduced Cost
Z 121.2505 0.000000
X10 4451.110 0.000000
X11 331.0578 0.000000
X12 217.8323 0.000000
X13 0.000000 0.4638899E-03 X15 0.000000 0.1815734E-03 Y12 213.9346 0.000000
Y13 4173.828 0.000000
X20 215.0513 0.000000
X21 0.000000 0.4376698E-03 X22 0.000000 0.1301125E-02 X23 0.000000 0.1905976E-02 X25 0.000000 0.3064300E-02 Y22 0.000000 0.1441660E-02 Y23 111.6729 0.000000
Y25 105.4106 0.000000
X30 104.4238 0.000000
X31 0.000000 0.1275805E-02 X32 0.000000 0.2265854E-02 X33 0.000000 0.1445411E-02 X35 0.000000 0.2585673E-02 Y32 0.000000 0.9923679E-03 Y33 0.000000 0.2391680E-02 Y35 105.4106 0.000000
X40 104.4238 0.000000
X41 0.000000 0.1388312E-02 X42 0.000000 0.9746112E-03 X43 0.000000 0.2919818E-02 X45 0.000000 0.1701906E-02 Y42 0.000000 0.2471048E-02 Y43 0.000000 0.1110232E-02 Y45 105.4106 0.000000
X50 4410.543 0.000000
X51 0.000000 0.000000
X52 0.000000 0.2282061E-02 X53 0.000000 0.1507626E-02 X55 0.000000 0.1511035E-02 Y52 0.000000 0.1078647E-02 Y53 0.000000 0.1419282E-03 Y55 4452.223 0.000000
X60 0.000000 0.000000
X61 0.000000 0.2636978E-02 X62 0.000000 0.2246477E-02 X63 0.000000 0.1877613E-02 X65 0.000000 0.2795830E-02 Y62 0.000000 0.1453243E-02 Y63 0.000000 0.1314101E-02 X70 0.000000 0.000000
X71 0.000000 0.000000
X72 0.000000 0.000000
X73 0.000000 0.3995130E-03
Y73 0.000000 0.000000
X80 0.000000 0.000000
X81 0.000000 0.3769317E-03 X82 0.000000 0.1120560E-02 X83 0.000000 0.1641472E-02 Y82 0.000000 0.1241592E-02 X91 0.000000 0.1098754E-02 X92 0.000000 0.1951408E-02 X101 0.000000 0.1195647E-02
Row Slack or Surplus Dual Price
1 121.2505 1.000000
2 0.000000 0.1131967
3 0.000000 0.1121370
4 0.000000 0.1114317
5 0.000000 0.1103885
6 0.000000 0.1092633
7 0.000000 0.1082404
8 0.000000 0.1063036
9 0.000000 0.1053084
10 0.000000 0.1032793
11 0.000000 0.1023125
12 0.000000 0.1016689
13 0.000000 0.1007171
14 0.000000 0.9748772E-01
15 0.000000 0.9657509E-01
16 0.000000 0.9596759E-01
17 0.000000 0.9506919E-01
18 0.000000 0.9410012E-01
19 0.000000 0.9155119E-01
20 0.000000 0.8894663E-01
8.3附件三:
model:
max=z;
x10+x11+x12+x13+x15<=5000.00;
y12+y13+y15<=1.00945*x10;
x20+x21+x22+x23+x25<=x11*1.01584-z;
y22+y23+y25<=1.00945*x20;
x30+x31+x32+x33+x35<=x21*1.01584+x12*1.036-z;
y32+y33+y35<=1.00945*x30;
x40+x41+x42+x43+x45<=x31*1.01584+x22*1.036+x13*1.06048+1.00945*1.045*y1 2-z;
y42+y43+y45<=1.00945*x40;
x50+x51+x52+x53+x55<=x41*1.01584+x32*1.036+x23*1.06048+1.00945*1.045*y2 2+1.00945*1.0756*y13-z;
y52+y53+y55<=1.00945*x50;
x60+x61+x62+x63+x65<=x51*1.01584+x42*1.036+x33*1.06048+x15*1.1116+1.009 45*1.045*y32+1.00945*1.0756*y23-z;
y62+y63<=1.00945*x60;
x70+x71+x72+x73<=x61*1.01584+x52*1.036+x43*1.06048+x25*1.1116+1.00945*1 .045*y42+1.00945*1.0756*y33+1.00945*1.1395*y15-z;
y72+y73<=1.00945*x70;
x80+x81+x82+x83<=x71*1.01584+x62*1.036+x53*1.06048+x35*1.1116+1.00945*1 .045*y52+1.00945*1.0756*y43+1.00945*1.1395*y25-z;
y82<=1.00945*x80;
x91+x92<=x81*1.01584+x72*1.036+x63*1.06048+x45*1.1116+1.00945*1.045*y62 +1.00945*1.0756*y53+1.00945*1.1395*y35-1.2*z;
x101<=x91*1.01584+x82*1.036+x73*1.06048+x55*1.1116+1.00945*1.045*y72+1. 00945*1.0756*y63+1.00945*1.1395*y45-z;
5000.00=x101*1.01584+x92*1.036+x83*1.06048+x65*1.1116+1.00945*1.045*y82 +1.00945*1.0756*y73+1.00945*1.1395*y55-z;
end
运行后,显示如下:
Global optimal solution found.
Objective value: 119.0107
Infeasibilities: 0.000000
Total solver iterations: 22
Variable Value Reduced Cost
Z 119.0107 0.000000
X10 4441.462 0.000000
X11 324.9424 0.000000
X12 233.5951 0.000000
X13 0.000000 0.4553207E-03 X15 0.000000 0.1782193E-03 Y12 209.9827 0.000000
Y13 4169.988 0.000000
Y15 103.4634 0.000000
X20 211.0788 0.000000
X21 0.000000 0.4295850E-03 X22 0.000000 0.1277090E-02 X23 0.000000 0.1870768E-02 X25 0.000000 0.3007695E-02 Y22 0.000000 0.1415029E-02
Y23 109.6101 0.000000
Y25 103.4634 0.000000
X30 122.9938 0.000000
X31 0.000000 0.1252238E-02 X32 0.000000 0.2223999E-02 X33 0.000000 0.1418711E-02 X35 0.000000 0.2537909E-02 Y32 0.000000 0.9740366E-03 Y33 0.000000 0.2347500E-02 Y35 124.1561 0.000000
X40 102.4949 0.000000
X41 0.000000 0.1362666E-02 X42 0.000000 0.9566078E-03 X43 0.000000 0.2865882E-02 X45 0.000000 0.1670468E-02 Y42 0.000000 0.2425401E-02 Y43 0.000000 0.1089724E-02 Y45 103.4634 0.000000
X50 4408.614 0.000000
X51 0.000000 0.000000
X52 0.000000 0.2239906E-02 X53 0.000000 0.1479776E-02 X55 0.000000 0.1483123E-02 Y52 0.000000 0.1058722E-02 Y53 0.000000 0.1393065E-03 Y55 4450.275 0.000000
X60 0.000000 0.000000
X61 0.000000 0.2588267E-02 X62 0.000000 0.2204979E-02 X63 0.000000 0.1842929E-02 X65 0.000000 0.2744185E-02 Y62 0.000000 0.1426399E-02 Y63 0.000000 0.1289826E-02 X70 0.000000 0.000000
X71 0.000000 0.000000
X72 0.000000 0.000000
X73 0.000000 0.3921331E-03 Y72 0.000000 0.000000
Y73 0.000000 0.000000
X80 0.000000 0.000000
X81 0.000000 0.3699688E-03 X82 0.000000 0.1099860E-02 X83 0.000000 0.1611150E-02 Y82 0.000000 0.1218656E-02
X91 0.000000 0.1078457E-02 X92 0.000000 0.1915361E-02 X101 0.000000 0.1173561E-02
Row Slack or Surplus Dual Price
1 119.0107 1.000000
2 0.000000 0.1111057
3 0.000000 0.1100656
4 0.000000 0.1093732
5 0.000000 0.1083493
6 0.000000 0.1072449
7 0.000000 0.1062409
8 0.000000 0.1043399
9 0.000000 0.1033631
10 0.000000 0.1013715
11 0.000000 0.1004225
12 0.000000 0.9979084E-01
13 0.000000 0.9885664E-01
14 0.000000 0.9568689E-01
15 0.000000 0.9479112E-01
16 0.000000 0.9419485E-01
17 0.000000 0.9331304E-01
18 0.000000 0.9236186E-01
19 0.000000 0.8986002E-01
20 0.000000 0.8730358E-01
蚁群算法综述
智能控制之蚁群算法 1引言 进入21世纪以来,随着信息技术的发展,许多新方法和技术进入工程化、产品化阶段,这对自动控制技术提出新的挑战,促进了智能理论在控制技术中的应用,以解决用传统的方法难以解决的复杂系统的控制问题。随着计算机技术的飞速发展,智能计算方法的应用领域也越来越广泛。 智能控制技术的主要方法有模糊控制、基于知识的专家控制、神经网络控制和集成智能控制等,以及常用优化算法有:遗传算法、蚁群算法、免疫算法等。 蚁群算法是近些年来迅速发展起来的,并得到广泛应用的一种新型模拟进化优化算法。研究表明该算法具有并行性,鲁棒性等优良性质。它广泛应用于求解组合优化问题,所以本文着重介绍了这种智能计算方法,即蚁群算法,阐述了其工作原理和特点,同时对蚁群算法的前景进行了展望。 2 蚁群算法概述 1、起源 蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型技术。它由Marco Dorigo于1992年在他的博士论文中引入,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为。 Deneubourg及其同事(Deneubourg et al.,1990; Goss et al.,1989)在可监控实验条件下研究了蚂蚁的觅食行为,实验结果显示这些蚂蚁可以通过使用一种称为信息素的化学物质来标记走过的路径,从而找出从蚁穴到食物源之间的最短路径。 在蚂蚁寻找食物的实验中发现,信息素的蒸发速度相对于蚁群收敛到最短路径所需的时间来说过于缓慢,因此在模型构建时,可以忽略信息素的蒸发。然而当考虑的对象是人工蚂蚁时,情况就不同了。实验结果显示,对于双桥模型和扩展双桥模型这些简单的连接图来说,同样不需要考虑信息素的蒸发。相反,在更复杂的连接图上,对于最小成本路径问题来说,信息素的蒸发可以提高算法找到好解的性能。 2、基于蚁群算法的机制原理 模拟蚂蚁群体觅食行为的蚁群算法是作为一种新的计算智能模式引入的,该算法基于如下假设: (1)蚂蚁之间通过信息素和环境进行通信。每只蚂蚁仅根据其周围的环境作出反应,也只对其周围的局部环境产生影响。 (2)蚂蚁对环境的反应由其内部模式决定。因为蚂蚁是基因生物,蚂蚁的行为实际上是其基因的自适应表现,即蚂蚁是反应型适应性主体。 (3)在个体水平上,每只蚂蚁仅根据环境作出独立选择;在群体水平上,单
启发式优化算法综述
启发式优化算法综述 一、启发式算法简介 1、定义 由于传统的优化算法如最速下降法,线性规划,动态规划,分支定界法,单纯形法,共轭梯度法,拟牛顿法等在求解复杂的大规模优化问题中无法快速有效地寻找到一个合理可靠的解,使得学者们期望探索一种算法:它不依赖问题的数学性能,如连续可微,非凸等特性; 对初始值要求不严格、不敏感,并能够高效处理髙维数多模态的复杂优化问题,在合理时间内寻找到全局最优值或靠近全局最优的值。于是基于实际应用的需求,智能优化算法应运而生。智能优化算法借助自然现象的一些特点,抽象出数学规则来求解优化问题,受大自然的启发,人们从大自然的运行规律中找到了许多解决实际问题的方法。对于那些受大自然的运行规律或者面向具体问题的经验、规则启发出来的方法,人们常常称之为启发式算法(Heuristic Algorithm)。 为什么要引出启发式算法,因为NP问题,一般的经典算法是无法求解,或求解时间过长,我们无法接受。因此,采用一种相对好的求解算法,去尽可能逼近最优解,得到一个相对优解,在很多实际情况中也是可以接受的。启发式算法是一种技术,这种技术使得在可接受的计算成本内去搜寻最好的解,但不一定能保证所得的可行解和最优解,甚至在多数情况下,无法阐述所得解同最优解的近似程度。 启发式算法是和问题求解及搜索相关的,也就是说,启发式算法是为了提高搜索效率才提出的。人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题
时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案,以随机或近似随机方法搜索非线性复杂空间中全局最优解的寻取。启发式解决问题的方法是与算法相对立的。算法是把各种可能性都一一进行尝试,最终能找到问题的答案,但它是在很大的问题空间内,花费大量的时间和精力才能求得答案。启发式方法则是在有限的搜索空间内,大大减少尝试的数量,能迅速地达到问题的解决。 2、发展历史 启发式算法的计算量都比较大,所以启发式算法伴随着计算机技术的发展,才能取得了巨大的成就。纵观启发式算法的历史发展史: 40年代:由于实际需要,提出了启发式算法(快速有效)。 50年代:逐步繁荣,其中贪婪算法和局部搜索等到人们的关注。 60年代: 反思,发现以前提出的启发式算法速度很快,但是解得质量不能保证,而且对大规模的问题仍然无能为力(收敛速度慢)。 70年代:计算复杂性理论的提出,NP问题。许多实际问题不可能在合理的时间范围内找到全局最优解。发现贪婪算法和局部搜索算法速度快,但解不好的原因主要是他们只是在局部的区域内找解,等到的解没有全局最优性。由此必须引入新的搜索机制和策略。 Holland的遗传算法出现了(Genetic Algorithm)再次引发了人们研究启发式算法的兴趣。 80年代以后:模拟退火算法(Simulated Annealing Algorithm),人工神经网络(Artificial Neural Network),禁忌搜索(Tabu Search)相继出现。 最近比较火热的:演化算法(Evolutionary Algorithm), 蚁群算法(Ant Algorithms),拟人拟物算法,量子算法等。
蚁群算法研究综述
蚁群算法综述 控制理论与控制工程09104046 吕坤一、蚁群算法的研究背景 蚂蚁是一种最古老的社会性昆虫,数以百万亿计的蚂蚁几乎占据了地球上每一片适于居住的土地,它们的个体结构和行为虽然很简单,但由这些个体所构成的蚁群却表现出高度结构化的社会组织,作为这种组织的结果表现出它们所构成的群体能完成远远超越其单只蚂蚁能力的复杂任务。就是他们这看似简单,其实有着高度协调、分工、合作的行为,打开了仿生优化领域的新局面。 从蚁群群体寻找最短路径觅食行为受到启发,根据模拟蚂蚁的觅食、任务分配和构造墓地等群体智能行为,意大利学者M.Dorigo等人1991年提出了一种模拟自然界蚁群行为的模拟进化算法——人工蚁群算法,简称蚁群算法(Ant Colony Algorithm,ACA)。 二、蚁群算法的研究发展现状 国内对蚁群算法的研究直到上世纪末才拉开序幕,目前国内学者对蚁群算法的研究主要是集中在算法的改进和应用上。吴庆洪和张纪会等通过向基本蚁群算法中引入变异机制,充分利用2-交换法简洁高效的特点,提出了具有变异特征的蚊群算法。吴斌和史忠植首先在蚊群算法的基础上提出了相遇算法,提高了蚂蚁一次周游的质量,然后将相遇算法与采用并行策略的分段算法相结合。提出一种基于蚁群算法的TSP问题分段求解算法。王颖和谢剑英通过自适应的改变算法的挥发度等系数,提出一种自适应的蚁群算法以克服陷于局部最小的缺点。覃刚力和杨家本根据人工蚂蚁所获得的解的情况,动态地调整路径上的信息素,提出了自适应调整信息素的蚁群算法。熊伟清和余舜杰等从改进蚂蚁路径的选择策略以及全局修正蚁群信息量入手,引入变异保持种群多样性,引入蚁群分工的思想,构成一种具有分工的自适应蚁群算法。张徐亮、张晋斌和庄昌文等将协同机制引入基本蚁群算法中,分别构成了一种基于协同学习机制的蚁群算法和一种基于协同学习机制的增强蚊群算法。 随着人们对蚁群算法研究的不断深入,近年来M.Dorigo等人提出了蚁群优化元启发式(Ant-Colony optimization Meta Heuristic,简称ACO-MA)这一求解复杂问题的通用框架。ACO-MH为蚁群算法的理论研究和算法设计提供了技术上的保障。在蚁群优化的收敛性方面,W.J.Gutjahr做了开创性的工作,提出了基于图的蚂蚁系统元启发式(Graph-Based Ant System Metaheuristic)这一通用的蚁群优化 的模型,该模型在一定的条件下能以任意接近l的概率收敛到最优解。T.StBtzle 和M.Dorigo对一类ACO算法的收敛性进行了证明,其结论可以直接用到两类实验上,证明是最成功的蚁群算法——MMAs和ACS。N.Meuleau和M.Dorigo研究了
基于蚁群算法的TSP问题研究
南京航空航天大学金城学院毕业设计(论文)开题报告 题目基于蚁群算法的TSP问题研究 系部XXXX系 专业XXXX 学生姓名XXXX学号XXXX 指导教师XXXX职称讲师 毕设地点XXXX 年月日
填写要求 1.开题报告只需填写“文献综述”、“研究或解决的问题和拟采用的方法”两部分内容,其他信息由系统自动生成,不需要手工填写。 2.为了与网上任务书兼容及最终打印格式一致,开题报告采用固定格式,如有不适请调整内容以适应表格大小并保持整体美观,切勿轻易改变格式。 3.任务书须用A4纸,小4号字,黑色宋体,行距1.5倍。 4.使用此开题报告模板填写完毕,可直接粘接复制相应的内容到毕业设计网络系统。
1.结合毕业设计(论文)课题任务情况,根据所查阅的文献资料,撰写1500~2000字左右的文献综述: 1.1蚁群算法的发展和应用 在计算机自动控制领域中,控制和优化始终是两个重要问题。使用计算机进行控制和优化本质上都表现为对信息的某种处理。随着问题规模的日益庞大,特性上的非线性及不确定性等使得难以建立精确的“数学模型”。人们从生命科学和仿生学中受到启发,提出了许多智能优化方法,为解决复杂优化问题(NP-hard问题)提供了新途径。 蚁群算法(Ant Colony Algorithm,ACA)是Dorigo M等人于1991年提出的。 经观察发现,蚂蚁个体之间是通过一种称之为信息素的物质进行信息传递的。在运动过程中,蚂蚁能够在它所经过的路径上留下该种信息素,而且能够感知信息素的浓度,并以此指导自己的运动方向。蚁群的集体行为表现出一种信息正反馈现象:某一路径上走过的蚂蚁越多,则后来者选择该路径的概率就越大。蚂蚁个体之间就是通过这种信息的交流达到搜索食物的目的。它充分利用了生物蚁群通过个体间简单的信息传递,搜索从蚁巢至食物间最短路径的集体寻优特征,以及该过程与旅行商问题求解之间的相似性。同时,该算法还被用于求解二次指派问题以及多维背包问题等,显示了其适用于组合优化问题求解的优越特征。 蚁群算法应用于静态组合优化问题,其典型代表有旅行商问题(TSP)、二次分配问题(QAP)、车间调度问题、车辆路径问题等。在动态优化问题中的应用主要集中在通讯网络方面。这主要是由于网络优化问题的特殊性,如分布计算,随机动态性,以及异步的网络状态更新等。例如将蚁群算法应用于QOS组播路由问题上,就得到了优于模拟退火(SA)和遗传算法(GA)的效果。蚁群优化算法最初用于解决TSP 问题,经过多年的发展,已经陆续渗透到其他领域中,如图着色问题、大规模集成电路设计、通讯网络中的路由问题以及负载平衡问题、车辆调度问题等。蚁群算法在若干领域获得成功的应用,其中最成功的是在组合优化问题中的应用。 1.2蚁群算法求解TSP问题 (1)TSP问题的描述 TSP问题的简单形象描述是:给定n个城市,有一个旅行商从某一城市出发,访问各城市一次且仅有一次后再回到原出发城市,要求找出一条最短的巡回路径。 (2)TSP问题的理论意义 该问题是作为所有组合优化问题的范例而存在的。它已经成为并将继续成为测
比较PageRank算法和HITS算法的优缺点
题目:请比较PageRank算法和HITS算法的优缺点,除此之外,请再介绍2种用于搜索引擎检索结果的排序算法,并举例说明。 答: 1998年,Sergey Brin和Lawrence Page[1]提出了PageRank算法。该算法基于“从许多优质的网页链接过来的网页,必定还是优质网页”的回归关系,来判定网页的重要性。该算法认为从网页A导向网页B的链接可以看作是页面A对页面B的支持投票,根据这个投票数来判断页面的重要性。当然,不仅仅只看投票数,还要对投票的页面进行重要性分析,越是重要的页面所投票的评价也就越高。根据这样的分析,得到了高评价的重要页面会被给予较高的PageRank值,在检索结果内的名次也会提高。PageRank是基于对“使用复杂的算法而得到的链接构造”的分析,从而得出的各网页本身的特性。 HITS 算法是由康奈尔大学( Cornell University ) 的JonKleinberg 博士于1998 年首先提出。Kleinberg认为既然搜索是开始于用户的检索提问,那么每个页面的重要性也就依赖于用户的检索提问。他将用户检索提问分为如下三种:特指主题检索提问(specific queries,也称窄主题检索提问)、泛指主题检索提问(Broad-topic queries,也称宽主题检索提问)和相似网页检索提问(Similar-page queries)。HITS 算法专注于改善泛指主题检索的结果。 Kleinberg将网页(或网站)分为两类,即hubs和authorities,而且每个页面也有两个级别,即hubs(中心级别)和authorities(权威级别)。Authorities 是具有较高价值的网页,依赖于指向它的页面;hubs为指向较多authorities的网页,依赖于它指向的页面。HITS算法的目标就是通过迭代计算得到针对某个检索提问的排名最高的authority的网页。 通常HITS算法是作用在一定范围的,例如一个以程序开发为主题的网页,指向另一个以程序开发为主题的网页,则另一个网页的重要性就可能比较高,但是指向另一个购物类的网页则不一定。在限定范围之后根据网页的出度和入度建立一个矩阵,通过矩阵的迭代运算和定义收敛的阈值不断对两个向量authority 和hub值进行更新直至收敛。 从上面的分析可见,PageRank算法和HITS算法都是基于链接分析的搜索引擎排序算法,并且在算法中两者都利用了特征向量作为理论基础和收敛性依据。
蚁群算法及其在序列比对中的应用研究综述
蚁群算法及其在序列比对中的应用研究综述摘要:蚁群算法是一种新颖的仿生进化算法。作为一种全局搜索的方法,蚂蚁算法具有正反馈性、并行性、分布性、自组织性等特点,自提出以来,便在求解复杂组合优化问题上显示出了强大的优势。序列比对是生物信息学的基础,通过在比对中获得大量的序列信息,可以推断基因的结构、功能和进化关系。本文首先详细阐述了蚁群算法的基本原理、各种改进技术及收敛性分析,然后对蚁群算法在双序列比对和多序列比对的应用研究进行了综述和评价,最后指出了下一步的研究方向。 关键词:蚁群算法;序列比对;信息素 Abstract: Ant colony algorithm (ACA) is a novel bionic evolutionary algorithm. As a global searching approach,ACA has some characteristic,such as positive feedback, distributing,paralleling, self-organizing, etc,and from it was introduced, it has been used to solve all kinds of complex optimization problem. Sequence alignment is the basement of Bioinformatics. With the wealth of sequence information obtained from sequence alignment, one can infers the structure, function and evolutionary relationship of genes. In this paper, the basic principles of ACA are introduced at length, and various improvements and convergence Analysis of ACA are also presented. Then the current study of double sequence alignment and multiple sequence alignment based on ant colony algorithm are reviewed and evaluated. Finally, some future research directions about ACA are proposed. Key words: Ant Colony Algorithm; Sequence Alignment; Pheromone 1 引言 蚁群算法(Ant Algorithm)是一种源于大自然中生物世界的新的仿生类算法,作为通用型随机优化方法,它吸收了昆虫王国中蚂蚁的行为特性,通过其内在的搜索机制,在一系列困难的组合优化问题求解中取得了成效。由于在模拟仿真中使用的是人工蚂蚁概念,因此有时亦被称为蚂蚁系统(Ant System)。据昆虫学家的观察和研究发现,生物世界中的蚂蚁有能力在没有任何可见提示下找出从其窝巢至食物源的最短路径,并能随环境的变化而变化,适应性地搜索新的路径,产生新的选择。作为昆虫的蚂蚁在寻找食物源时,能在其走过的路径上释放一种蚂蚁特有的分泌物——信息激素(Pheromone),使得一定范围内的其他蚂蚁能够察觉到并由此影响它们以后的行为。当一些路径上通过的蚂蚁越来越多时,其留下的信息激素轨迹(Trail)也越来越多,以致信息素强度增大(随时间的推移会逐渐减弱),后来蚂蚁选择该路径的概率也越高,从而更增加了该路径的信息素强
大数据pagerank算法设计
算法设计: 假设一个有集合:A,B,C和D 是由4个网页组成的。在同一个页面之中,多个指向相同的链接,把它们看作是同一个链接,并且每个页面初始的PageRank值相同。因为要满足概率值位于0到1之间的需求,我们假设这个值是0.25。 在每一次的迭代中,给定页面的PR值(PageRank值)会被平均分配到此页面所链接到的页面上。 倘若全部页面仅链接到A,这样的话A的PR值就是B,C和D的PR值之和,即:PR(A)=PR(B)+PR(C)+PR(D){\displaystyle PR(A)=PR(B)+PR(C)+PR(D)} 再次假设C链接到了A,B链接到了A和C,D链接到了A,B,C。最开始的时候一个页面仅仅只会有一票。正因为这样,所以的话B将会给A ,C这两个页面每一个页面半票。按照这样来类比推算,D所投出去的票将只会有三分之一的票会被添加到属于A 的PR值上: {\displaystyle PR(A)={\frac {PR(B)}{2}}+{\frac {PR(C)}{1}}+{\frac {PR(D)}{3}}} 换个方式表达的话,算法将会依据每一个页面链接出来的总数 {\displaystyle L(x)}平均的分配每一个页面的PR值,然后把它添加至它指向的页面:
最后,这些全部的PR值将会被变换计算成为百分比的形式然后会再乘上一个修正系数。因为“没有向外链接的网页”它传递出去的PR值将会是0,而且这将递归地差生影响从而使得指向它的页面的PR值的计算出来得到的结果同样是零,因此每一个页面要有预先设置好了的一个最小值: 需要注意的是,在Sergey Brin和Lawrence Page的1998年原版论文中给每一个页面设定的最小值是1-d,而不是这里的(1-d)/N,这将导致集合中所有网页的PR值之和为N(N为集合中网页的数目)而并不是所期待的1。 所以,一个页面的PR值直接取决于指向它的的页面。如果在最初给每个网页一个随机且非零的PR值,经过重复计算,这些页面的PR值将会逐渐接近于某一个固定 定值,也就是处于收敛的状态,即最终结果。这就是搜索引擎使用该算法的原因。【测试环境】 【测试数据】
人工蜂群算法在警用无人机战术需求中的应用浅析
人工蜂群算法在警用无人机战术需求中的应用浅析 摘要随着无人机在警务工作中越来越广泛的应用,以及适应新形势下警务实战化改革需求的无人机联合信息传导概念的不断发展,如何发挥无人机集群智能成为了当前警用无人机需解决的问题。立足于生物科技,将人工蜂群算法与警用无人机控制应用技术结合,探索能够有效优化无人机集群智能的应用方法。 关键词人工蜂群算法;集群智能;无人机;最优值 引言 当前国内外对无人机战术规划的研究成果比较多,但主要集中在无人机的航行移动上。虽然无人机战术功能研究近年来受到了广泛的重视,也取得了较大的进展,但相对于无人机的航行移动仍处于远远滞后的状态。航行移动和战术功能是无人机战术规划中密不可分的两个重要步骤,只有保证两者协调发展,才能对无人机执行作战任务提供全面支持,从而使无人机能够满足更多任务需求。通过对无人机集群智能问题进行层次分析,将无人机集群智能问题劃分为航行移动问题和战术功能问题分别进行分析,再进行有机结合,有效地降低原问题的复杂性。 1 从航行移动上发挥警用无人机集群智能优势 在传统的警用无人机应用中,首先要解决无人机在飞行过程中的供能问题,既无人机本身的载荷能力考量。一般小型无人机动力不足以支持长时间的作战任务需求。为此,从提高任务执行效能上考虑,要优化执行任务中的航行移动问题。针对此类问题,我们要将地形学和ABC算法相结合,通过地形学对航行移动路线的拓展,以降低航行移动路线的复杂程度,再通过ABC算法对相关任务地形进行快速的路线搜索,针对航行移动问题的实际要求,将集群智能机制引入ABC 算法的信息更新机制中,显著地提高了最优值的搜索效率。同时,分析警用无人机在实际过程中情报搜集问题的特殊性与复杂性,从最大程度满足用户需求出发,给出了需求满足最优值的战术处理路径和行动路线。利用ABC算法协同性强、搜索行为灵活等优点,在算法的基础上,利用蜂群采蜜行为的分工协同能力,引入蜂群当前循环中的生物天性,调整了多无人机现实战术计划,从而提高了搜索效率[1]。 2 从战术功能上发挥警用无人机集群智能优势 愈来愈加特殊化和复杂化的任务和战术环境,使得警务无人机在应用方面更趋向于多元化。在过去的研究中,无人机任务类型及能力制约是指对单架无人机,其机上携带的任务载荷和功能配备是有限的,所能完成的任务类型及数量受其任务载荷限制。为此,在无人机协同多任务分配问题中,由于单架无人机所能完成的任务类型和数量有限,故特定的无人机只能执行与自身能力相符合的任务,且其任务过程不能超过自身最大任务数量限制和飞行载荷限制,超出自身能力范围的任务就必须交由其他无人机执行。为此,在当前警用无人机的技术水平上,依
Pagerank算法与网页排序方法的建模
Pagerank 算法与网页排序方法的建模 摘要 随着互联网的飞速发展,各种杂乱无章的信息充斥其中,如何对数以亿记的相关网页进行排序成为搜索引擎的核心问题。针对这个现象本文根据题目要求建立了两个模型: 模型一:结合Google 的Pagerank 算法,建立了网上冲浪模型,得到Pagerank 算法定义: n i i 1 i P R(T )P R(A )(1d )d C (T ) ==-+∑ 用迭代算法通过MATLAB 编程计算出网页的PR 值; 模型二:由于传统PR 值算法仅考虑网页的外链和内链数量,偏重于旧网页;另外,传统算法不能区分网页中的链接与网页的主题是否相关,容易产生主题漂移现象;考虑其算法存在的缺陷,在此基础上为给出对搜索网页进行排序的方法,着重考虑搜索出的网页以下几个方面:外链,内链,时间反馈因子和相关度,对PR 值进行改进,得到以下公式: Wt V VT sim VT V sim T PR d d p PR k i m j j i i P i +?+-=∑ ∑==1 1 , ,) () ()()1()( 以PR 值的高低来对搜索网页进行排序; 对于如何使新网站在搜索引擎中排名靠前,从影响网页的PR 值的因素:內链、外链、时间反馈因子和相关度出发对提高网页的PR 值以使其在搜索引擎中排名靠前给出了稳健的建议。 关键词 Pagerank 迭代算法 MATLAB 时间反馈因子 相关度 一、问题重述 随着互联网的发展,面对众多杂乱无章的信息,如何对数以亿计的相关网页进行排序成为搜索引擎算法的核心问题。一个搜索引擎的算法,要考虑很多的方面。主要是“域
名、密度、内链、外链、相关度、服务器稳定、内容更新、域名时间、内容数量”这些方面。不同的搜索引擎侧重点也不同,比如Google,它对收录的网站有一个重要性排名的指数,被称为Pagerank,作为对搜索网页排序的重要参数。 根据搜索引擎与Pagerank,考虑如下问题: 1.考察Google的Pagerank算法,建立数学模型,给出合理的Pagerank的计算方法; 2.如果你是搜索引擎的建设者,请考虑你会侧重考虑搜索网页的那些方面,给出你对搜索网页进行排序的方法; 3.如果你是某新网站的建设者,请考虑使你的网站在第2题中你建立的搜索引擎中排名靠前的方法。 二、问题分析 互联网的迅速发展,使现有的搜索引擎面临着巨大的挑战,面对众多杂乱无章的信息,如何对数以亿计的相关网页进行排序成为搜索引擎算法的核心问题,因此,搜索引擎排序算法也就称为众多搜索引擎关注的关键问题之一。 对于问题1,根据题目要求,结合Google的Pagerank算法,PageRank算法的基本思想是:页面的重要程度用PageRank值来衡量,PageRank值主要体现在两个方面:引用该页面的页面个数和引用该页面的页面重要程度。若B网页设置有连接A网页的链接(B为A的导入链接时),说明B认为A有链接价值,是一个“重要”的网页。当B网页级别(重要性)比较高时,则A网页可从B网页这个导入链接分得一定的级别(重要性),并平均分配给A网页上的导出链接,由此建立了网上冲浪模型,用迭代算法计算出网页的PR值。 对于问题2,经过对Google的Pagerank算法的分析,发现该算法仅考虑了搜索出的网页的外链和内链的数量,以此来确定网页的PR值偏重于旧网页,即越旧的网页排名越靠前;对一个刚放到网上不久的新网页,指向它的网页就很少,通过计算后的PR 值就很低,在搜索结果中也就被排在了靠后的位置。然而在有些时候,比如新闻类网页和商务性信息,用户当然是希望先看到新的网页,因此我们在计算PR值时考虑加入时间反馈因子,使得在网络上存在时间比较长的网页被沉下去,在搜索结果中被排在靠后的位置;存在时间短的网页就会浮上来,在搜索结果中被排在较靠前的位置,方便用户查看。时间反馈因子利用搜索引擎的搜索周期来表征,即如果一个网页存在时间较长,它将在每个搜索周期中都能被搜到,对网页采取在同一个周期里不管搜到该网页几次,都算一次处理的方法,网页的存在时间正比于搜索引擎搜到该网页的次数,时间反馈因子与网页的存在时间成反比关系。 另外,Google的Pagerank算法是基于网页链接结构进行分析的算法,不能区分网页中的链接与网页的主题是否相关,这样就容易出现搜索引擎排序结果中大量与查询主题无关的网页的现象,即产生主题漂移现象。为解决这个问题,引入主题相关度这个概念。主题相关度就是搜索出的网页与其链入和链出网页的相似度,可用余弦相似度来度量计算。 在加入了时间反馈因子和相关性因素后,改进网页的PR值的算法,以PR值高低的来对搜索的网页进行排序。 对于问题三,主要通过模型二的结果,加强有力的因素,避免不利的方面 三、模型假设与符号说明
pagerank算法实验报告
PageRank算法实验报告 一、算法介绍 PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。它由Larry Page 和Sergey Brin在20世纪90年代后期发明。PageRank实现了将链接价值概念作为排名因素。 PageRank的核心思想有2点: 1.如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是pagerank值会相对较高; 2.如果一个pagerank值很高的网页链接到一个其他的网页,那么被链接到的网页的pagerank值会相应地因此而提高。 若页面表示有向图的顶点,有向边表示链接,w(i,j)=1表示页面i存在指向页面j的超链接,否则w(i,j)=0。如果页面A存在指向其他页面的超链接,就将A 的PageRank的份额平均地分给其所指向的所有页面,一次类推。虽然PageRank 会一直传递,但总的来说PageRank的计算是收敛的。 实际应用中可以采用幂法来计算PageRank,假如总共有m个页面,计算如公式所示: r=A*x 其中A=d*P+(1-d)*(e*e'/m) r表示当前迭代后的PageRank,它是一个m行的列向量,x是所有页面的PageRank初始值。 P由有向图的邻接矩阵变化而来,P'为邻接矩阵的每个元素除以每行元素之和得到。 e是m行的元素都为1的列向量。 二、算法代码实现
三、心得体会 在完成算法的过程中,我有以下几点体会: 1、在动手实现的过程中,先将算法的思想和思路理解清楚,对于后续动手实现 有很大帮助。 2、在实现之前,对于每步要做什么要有概念,然后对于不会实现的部分代码先 查找相应的用法,在进行整体编写。 3、在实现算法后,在寻找数据验证算法的过程中比较困难。作为初学者,对于 数据量大的数据的处理存在难度,但数据量的数据很难寻找,所以难以进行实例分析。
PageRank算法的核心思想
如何理解网页和网页之间的关系,特别是怎么从这些关系中提取网页中除文字以外的其他特性。这部分的一些核心算法曾是提高搜索引擎质量的重要推进力量。另外,我们这周要分享的算法也适用于其他能够把信息用结点与结点关系来表达的信息网络。 今天,我们先看一看用图来表达网页与网页之间的关系,并且计算网页重要性的经典算法:PageRank。 PageRank 的简要历史 时至今日,谢尔盖·布林(Sergey Brin)和拉里·佩奇(Larry Page)作为Google 这一雄厚科技帝国的创始人,已经耳熟能详。但在1995 年,他们两人还都是在斯坦福大学计算机系苦读的博士生。那个年代,互联网方兴未艾。雅虎作为信息时代的第一代巨人诞生了,布林和佩奇都希望能够创立属于自己的搜索引擎。1998 年夏天,两个人都暂时离开斯坦福大学的博士生项目,转而全职投入到Google 的研发工作中。他们把整个项目的一个总结发表在了1998 年的万维网国际会议上(WWW7,the seventh international conference on World Wide Web)(见参考文献[1])。这是PageRank 算法的第一次完整表述。 PageRank 一经提出就在学术界引起了很大反响,各类变形以及对PageRank 的各种解释和分析层出不穷。在这之后很长的一段时间里,PageRank 几乎成了网页链接分析的代名词。给你推荐一篇参考文献[2],作为进一步深入了解的阅读资料。
PageRank 的基本原理 我在这里先介绍一下PageRank 的最基本形式,这也是布林和佩奇最早发表PageRank 时的思路。 首先,我们来看一下每一个网页的周边结构。每一个网页都有一个“输出链接”(Outlink)的集合。这里,输出链接指的是从当前网页出发所指向的其他页面。比如,从页面A 有一个链接到页面B。那么B 就是A 的输出链接。根据这个定义,可以同样定义“输入链接”(Inlink),指的就是指向当前页面的其他页面。比如,页面C 指向页面A,那么C 就是A 的输入链接。 有了输入链接和输出链接的概念后,下面我们来定义一个页面的PageRank。我们假定每一个页面都有一个值,叫作PageRank,来衡量这个页面的重要程度。这个值是这么定义的,当前页面I 的PageRank 值,是I 的所有输入链接PageRank 值的加权和。 那么,权重是多少呢?对于I 的某一个输入链接J,假设其有N 个输出链接,那么这个权重就是N 分之一。也就是说,J 把自己的PageRank 的N 分之一分给I。从这个意义上来看,I 的PageRank,就是其所有输入链接把他们自身的PageRank 按照他们各自输出链接的比例分配给I。谁的输出链接多,谁分配的就少一些;反之,谁的输出链接少,谁分配的就多一些。这是一个非常形象直观的定义。
相关文档
- pagerank算法讲解
- 大数据经典算法PageRank 讲解
- PageRank算法的核心思想
- 大数据十大经典算法PageRank 讲解
- PageRank算法
- PageRank算法的分析及其改进_王德广
- pagerank算法介绍
- 加权PageRank算法研究综述
- pagerank算法介绍
- PageRank算法解析.ppt
- PageRank算法研究
- 大数据——PageRank算法
- pagerank算法实验报告
- PageRank算法
- pagerank算法讲解
- PageRank算法介绍
- pagerank 算法
- 比较PageRank算法和HITS算法的优缺点
- pagerank算法讲解