基于Python的串口通信(1)

基于Python的串口通信(1)
Pyserial
1.1安装pyserial
1.1.1source安装
(1)下载pySerial
① 2.6版本:
https://www.sodocs.net/doc/728437366.html,/packages/source/p/pyserial/pyserial-2.6.tar.gz
② 2.7版本
https://www.sodocs.net/doc/728437366.html,/packages/source/p/pyserial/pyserial-2.7.tar.gz
③最新版本(目前为3.1版本):
https://https://www.sodocs.net/doc/728437366.html,/pypi/pyserial
(2)解压
①命令解压
cd /xxx/xxx/pyserial-2.6.tar.gz(以2.6版本为例,切换到相关文件所在目录)
tar zxvf pyserial-2.6.tar.gz
②手动解压(Mac下像.zip类的格式一般会在Safari下载完成后自动解压)
(3)安装serial module
cd /xxx/xxx/pyserial-2.6(切换到解压后的文件所在目录)
sudo python setup.py install(加sudo以避免权限问题:”Permission denied...”)
1.1.2pip安装
(1)方法一:
sudo pip install pyserial
注:上图中之所以写成pip2是因为系统里除了自带的Python2外,还装了Python3(pip3为默认pip),而安装是在Python2环境下进行的。
(2)方法二:
sudo apt-get install -y python-pip
sudo pip install -y pySerial
1.2serial通信测试
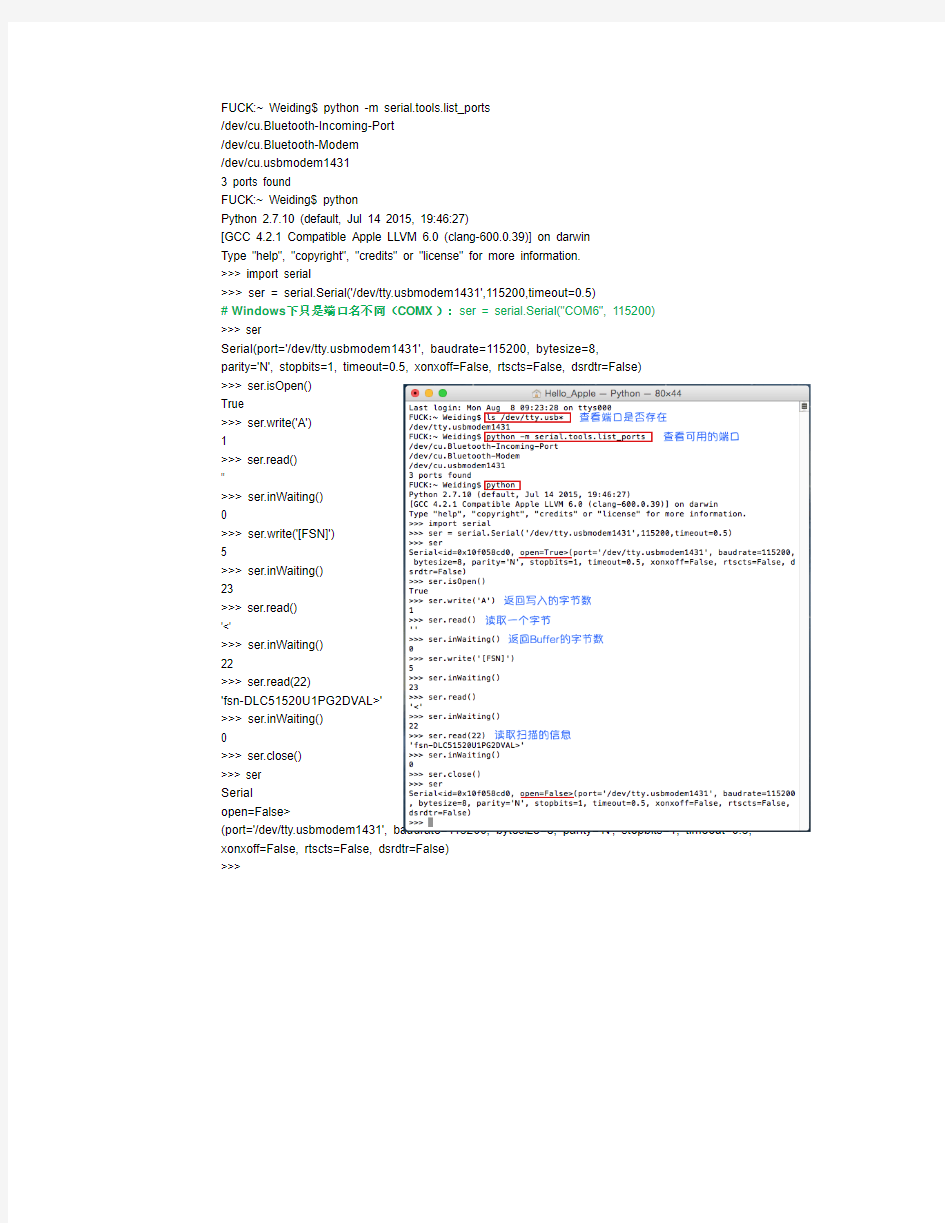
在Terminal中进行如下测试:
Last login: Mon Aug 8 09:23:28 on ttys000
FUCK:~ Weiding$ ls /dev/https://www.sodocs.net/doc/728437366.html,b*
/dev/https://www.sodocs.net/doc/728437366.html,bmodem1431
FUCK:~ Weiding$ python -m serial.tools.list_ports
/dev/cu.Bluetooth-Incoming-Port
/dev/cu.Bluetooth-Modem
/dev/https://www.sodocs.net/doc/728437366.html,bmodem1431
3 ports found
FUCK:~ Weiding$ python
Python 2.7.10 (default, Jul 14 2015, 19:46:27)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.39)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import serial
>>> ser = serial.Serial('/dev/https://www.sodocs.net/doc/728437366.html,bmodem1431',115200,timeout=0.5)
#Windows下只是端口名不同(COMX):ser = serial.Serial("COM6", 115200)
>>> ser
Serial
>>> ser.isOpen()
True
>>> ser.write('A')
1
>>> ser.read()
''
>>> ser.inWaiting()
>>> ser.write('[FSN]')
5
>>> ser.inWaiting()
23
>>> ser.read()
'<'
>>> ser.inWaiting()
22
>>> ser.read(22)
'fsn-DLC51520U1PG2DVAL>'
>>> ser.inWaiting()
>>> ser.close()
>>> ser
Serial open=False> (port='/dev/https://www.sodocs.net/doc/728437366.html,bmodem1431', baudrate=115200, bytesize=8, parity='N', stopbits=1, timeout=0.5, xonxoff=False, rtscts=False, dsrdtr=False) >>> 基于Python的网络信息自动抓取系统 摘要 随着移动互联网的快速发展和5G技术的投入建设,信息在社会发展中起着至关重要的作用,具备着前所未有的价值。人们想要掌握最新的信息和了解社会的发展趋势,就要不断递增花在阅读网络信息的时间。怎么从浩瀚的信息海洋中迅速有效地提取所需信息已经越来越重要。搜索引擎也随着我们的需求而诞生和发展,它以爬虫技术为核心。为提高用户访问网页信息的效率,本设计基于Python的Scrapy爬虫框架和MySQL后台数据库,以“百度新闻”为爬取对象,实现定时自动抓取指定范围的网页信息并存储到后台数据库中,并使用hashlib模块过滤重复数据。 关键词:爬虫技术 Scrapy爬虫框架 MySQL数据库定时自动 Automatic network information grabbing system based on Python Name: Diao Yangjian Major: Electronic Information Science and technology Instructor: Wan Changlin, Assistant Researcher (Electronic Information and Electrical Engineering Department of Huizhou University, No. 46, Yanda Avenue, Huizhou City, Guangdong Province, 516007) Abstract With the rapid development of mobile Internet and the investment of 5g technology, information plays an important role in the social development and has unprecedented value. If people want to master the latest information and understand the development trend of society, they need to spend more and more time reading network information. How to extract the needed information from the vast ocean of information quickly and effectively has become more and more important. Search engine is also born and developed with our needs. It takes crawler technology as the core. In order to improve the efficiency of users' access to web information, this design is based on Python's scrapy crawler framework and MySQL background database, taking "Baidu news" as the crawling object, to realize the automatic crawling of the specified range of Web information and storage in the background database, and use hashlib module to filter the duplicate data. Keywords:crawler technology scrapy crawler framework MySQL database timed auto crawl Python实例应用 她——一种最初由Guido van Rossum开发的开源(Open Source)的脚本语言。 Python已经有10年的历史了,在国外十分盛行。 Google搜索引擎的脚本,现在流行的BT(Bite Torrnet),还有著名的应用服务器Zope都是用Python编写的。但在国内的使用还不是很多。她十分有自己的特色。语法简洁,但功能强大,可以跨平台使用,在Linux、Windows和Mac上都有很好支持。她的设计很出色。 这里有两个Python的使用例子,都是对磁盘文件的操作,以次来看看Python 的特色。以下的程序是在 Windows平台上完成的。在Windows上安装Python十分方便,到Python的官方站点(https://www.sodocs.net/doc/728437366.html,)可以免费下载 Windows平台上的二进制安装包后直接安装就可以了,安装程序会完成所有的配置,不用象Java 一样要自己设置环境变量。 情景一: 在文件夹里有六十多个RM格式的视频文件,我现在需要把它们的文件名都提取出来,并去掉文件的扩展名,以便放到需要的网页里。 应该有什么软件可以完成这个简单的要求,可是一时间到哪里去找这样一个符合要求的软件呢?总不能手工完成把。在Linux上用强大的shell脚本应该也可以完成,可是使用Windows的朋友呢?其实象这样一个简单任务用Python这个强大脚本语言只要几条语句就可以搞定了。个大家知道,要完成这样一个任务根本不用动用C/C++或Java这样的大家伙。 好来看看Python的身手,用自己喜欢的文本编辑器或者直接使用安装包自带的IDE都可以: # --- picknames.py --- import os filenames=os.listdir(os.getcwd()) for name in filenames: filenames[filenames.index(name)]=name[:-3] out=open('names.txt','w') for name in filenames: out.write(name+'\n') out.close() 句字不多,一句句看。 山东建筑大学 课程设计成果报告 题目:基于Python的网络爬虫设计课程:计算机网络A 院(部):管理工程学院 专业:信息管理与信息系统 班级: 学生姓名: 学号: 指导教师: 完成日期: 目录 1 设计目的 0 2 设计任务内容 0 3 网络爬虫程序总体设计 0 4 网络爬虫程序详细设计 0 4.1 设计环境和目标分析 0 4.1.1 设计环境 0 4.1.2 目标分析 (1) 4.2 爬虫运行流程分析 (1) 4.3 控制模块详细设计 (2) 4.3 爬虫模块详细设计 (2) 4.3.1 URL管理器设计 (2) 4.3.2 网页下载器设计 (2) 4.3.3 网页解析器设计 (2) 4.4数据输出器详细设计 (3) 5 调试与测试 (3) 5.1 调试过程中遇到的问题 (3) 5.2测试数据及结果显示 (4) 6 课程设计心得与体会 (4) 7 参考文献 (5) 8 附录1 网络爬虫程序设计代码 (5) 9 附录2 网络爬虫爬取的数据文档 (8) 1 设计目的 本课程设计是信息管理与信息系统专业重要的实践性环节之一,是在学生学习完《计算机网络》课程后进行的一次全面的综合练习。本课程设计的目的和任务: 1.巩固和加深学生对计算机网络基本知识的理解和掌握; 2.培养学生进行对网络规划、管理及配置的能力或加深对网络协议体系结构的理解或提高网络编程能力; 3.提高学生进行技术总结和撰写说明书的能力。 2 设计任务内容 网络爬虫是从web中发现,下载以及存储内容,是搜索引擎的核心部分。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。 参照开放源码分析网络爬虫实现方法,给出设计方案,画出设计流程图。 选择自己熟悉的开发环境,实现网络爬虫抓取页面、从而形成结构化数据的基本功能,界面适当美化。给出软件测试结果。 3 网络爬虫程序总体设计 在本爬虫程序中共有三个模块: 1、爬虫调度端:启动爬虫,停止爬虫,监视爬虫的运行情况 2、爬虫模块:包含三个小模块,URL管理器、网页下载器、网页解析器。 (1)URL管理器:对需要爬取的URL和已经爬取过的URL进行管理,可以从URL 管理器中取出一个待爬取的URL,传递给网页下载器。 (2)网页下载器:网页下载器将URL指定的网页下载下来,存储成一个字符串,传递给网页解析器。 (3)网页解析器:网页解析器解析传递的字符串,解析器不仅可以解析出需要爬取的数据,而且还可以解析出每一个网页指向其他网页的URL,这些URL被解析出来会补充进URL管理器 3、数据输出模块:存储爬取的数据 4 网络爬虫程序详细设计 4.1 设计环境和目标分析 4.1.1 设计环境 0 前言 工作之余,时常会想能做点什么有意思的玩意。互联网时代,到处都是互联网思维,大数据、深度学习、人工智能,这些新词刮起一股旋风。所以笔者也赶赶潮流,买了本Python爬虫书籍研读起来。 网络爬虫,顾名思义就是将互联网上的内容按照自己编订的规则抓取保存下来。理论上来讲,浏览器上只要眼睛能看到的网页内容都可以抓起保存下来,当然很多网站都有自己的反爬虫技术,不过反爬虫技术的存在只是增加网络爬虫的成本而已,所以爬取些有更有价值的内容,也就对得起技术得投入。 1案例选取 人有1/3的时间在工作,有一个开心的工作,那么1/3的时间都会很开心。所以我选取招聘网站来作为我第一个学习的案例。 前段时间和一个老同学聊天,发现他是在从事交互设计(我一点也不了解这是什么样的岗位),于是乎,我就想爬取下前程无忧网(招聘网_人才网_找工作_求职_上前程无忧)上的交互设计的岗位需求: 2实现过程 我这里使用scrapy框架来进行爬取。 2.1程序结构 C:\Users\hyperstrong\spiderjob_jiaohusheji │scrapy.cfg │ └─spiderjob │ items.py │ pipelines.py │ settings.py │ __init__.py │ middlewares.py ├─spiders │ jobSpider.py │ __init__.py 其中: items.py是从网页抽取的项目 jobSpider.py是主程序 2.2链接的构造 用浏览器打开前程无忧网站 招聘网_人才网_找工作_求职_上前程无忧,在职务搜索里输入“交互设计师”,搜索出页面后,观察网址链接: 【交互设计师招聘】前程无忧手机网_触屏版 https://www.sodocs.net/doc/728437366.html,/jobsearch/search_result.php?fromJs=1&k eyword=%E4%BA%A4%E4%BA%92%E8%AE%BE%E8%AE%A1%E5%B8%88&keywordty pe=2&lang=c&stype=2&postchannel=0000&fromType=1&confirmdate=9 网址链接中并没有页码,于是选择第二页,观察链接: Python的应用领域有哪些? Python是一门简单、易学并且很有前途的编程语言,很多人都对Python感兴趣,但是当学完Python基础用法之后,又会产生迷茫,尤其是自学的人员,不知道接下来的Python学习方向,以及学完之后能干些什么?以下是Python十大应用领域! 1. WEB开发 Python拥有很多免费数据函数库、免费web网页模板系统、以及与web服务器进行交互的库,可以实现web开发,搭建web框架,目前比较有名气的Python web框架为Django。从事该领域应从数据、组件、安全等多领域进行学习,从底层了解其工作原理并可驾驭任何业内主流的Web框架。 2. 网络编程 网络编程是Python学习的另一方向,网络编程在生活和开发中无处不在,哪里有通讯就有网络,它可以称为是一切开发的“基石”。对于所有编程开发人员必须要知其然并知其所以然,所以网络部分将从协议、封包、解包等底层进行深入剖析。 3. 爬虫开发 在爬虫领域,Python几乎是霸主地位,将网络一切数据作为资源,通过自动化程序进行有针对性的数据采集以及处理。从事该领域应学习爬虫策略、高性能异步IO、分布式爬虫等,并针对Scrapy框架源码进行深入剖析,从而理解其原理并实现自定义爬虫框架。 4. 云计算开发 Python是从事云计算工作需要掌握的一门编程语言,目前很火的云计算框架OpenStack就是由Python开发的,如果想要深入学习并进行二次开发,就需要具备Python 的技能。 5. 人工智能 MASA和Google早期大量使用Python,为Python积累了丰富的科学运算库,当AI 时代来临后,Python从众多编程语言中脱颖而出,各种人工智能算法都基于Python编写,尤其PyTorch之后,Python作为AI时代头牌语言的位置基本确定。 6. 自动化运维 Python是一门综合性的语言,能满足绝大部分自动化运维需求,前端和后端都可以做,从事该领域,应从设计层面、框架选择、灵活性、扩展性、故障处理、以及如何优化等层面进行学习。 7. 金融分析 金融分析包含金融知识和Python相关模块的学习,学习内容囊括Numpy\Pandas\Scipy数据分析模块等,以及常见金融分析策略如“双均线”、“周规则交易”、“羊驼策略”、“Dual Thrust 交易策略”等。 8. 科学运算 Python是一门很适合做科学计算的编程语言,97年开始,NASA就大量使用Python 进行各种复杂的科学运算,随着NumPy、SciPy、Matplotlib、Enthought librarys等众多程序库的开发,使得Python越来越适合做科学计算、绘制高质量的2D和3D图像。 9. 游戏开发 在网络游戏开发中,Python也有很多应用,相比于Lua or C++,Python比Lua有更高阶的抽象能力,可以用更少的代码描述游戏业务逻辑,Python非常适合编写1万行以上的项目,而且能够很好的把网游项目的规模控制在10万行代码以内。 10. 桌面软件 Python在图形界面开发上很强大,可以用tkinter/PyQT框架开发各种桌面软件! 寻找自我的博客 p ython爬虫抓站的总结 分类: Python 2012-08-22 22:41 337人阅读 评论(0) 收藏举报 1.最基本的抓站 import urllib2 content = urllib2.urlopen('http://XXXX').read() 2.使用代理服务器 这在某些情况下比较有用,比如IP被封了,或者比如IP访问的次数受到限制等等。 import urllib2 proxy_support = urllib2.ProxyHandler({'http':'http://XX.XX.XX.XX:XXXX'}) opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler) urllib2.install_opener(opener) content = urllib2.urlopen('http://XXXX').read() 3.需要登录的情况 登录的情况比较麻烦我把问题拆分一下: 3.1 cookie的处理 import urllib2, cookielib cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar()) opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler) urllib2.install_opener(opener) content = urllib2.urlopen('http://XXXX').read() 是的没错,如果想同时用代理和cookie,那就加入proxy_support然后operner改为 opener = urllib2.build_opener(proxy_support, cookie_support, urllib2.HTTPHandler) 3.2 表单的处理 登录必要填表,表单怎么填?首先利用工具截取所要填表的内容。 比如我一般用firefox+httpfox插件来看看自己到底发送了些什么包 这个我就举个例子好了,以verycd为例,先找到自己发的POST请求,以及POST表单项: 第十三课人生苦短我用Python语法简单才会越来越被编程界欢迎初始函数 1.1 函数的作用 ;1.2函数的组成 1.3定义和调用函数 函数的进阶使用 2.1函数类型 2.2返回多个值 多函数协作 3.1变量作用域 3.2函数嵌 /\e这两节课的主要内容是带大家探究“熟悉的陌生人”——函数。之所以这么说,是因 为我们之前已经接触过Python函数,但是对它没有系统地了解过。这节课,我们一起经营KFC,在我们KFC门店里通过运用函数解决我们的问题。首先在学习具体知识前,我向大家简 要的介绍下函数的作用,知道函数是做什么用的? 1 函数的作用 人生苦短,我用Python”,正因为Python语法简单,才会越来越被编程界欢迎。换言之,我们编程,更应该避免重复性代码。前面学习的循环是减少代码重复的一种手段,那么接下来要学习的函数也是减少重复性代码的另一种手段。它的定义是: 什么意思呢?我们之前写的代码只能执行一次,但是函数中的代码可以使用多次。通俗来讲,函数就如同一个包裹,每个包裹都有一个功能,无论你在哪儿,只要你需要包裹,就把它拿过去用;你需要什么样功能的包裹,就用什么样的包裹;你需要使用多少次包裹,就使用多少次。这就是函数,在之后的旅程中,你会越来越体会到函数的妙用。讲了这么多了,先看一下函数长什么样子? 1.2函数的组成 先不着急看Python的函数,先来个数学函数,那些年,我们错过的函数。数学函数y = 6*x +9 , x是自变量,6*x+9是执行过程,y是因变量,自变量x决定了因变量y得值。那么,你可以将y = 6*x +9看作成3部分 在Python中,我们遇到很多函数,有负责输入数据的函数,有负责数据处理的函数,有负责数据输出的函数。 以上就是我们见过的Python的函数,这些函数是Python自带的函数,我们不需要管这些函数怎么来的,就负责用就好了,这些函数也叫内置函数。你会发现,上面这些函数,都有括号(),里面存放我们需要传给函数的数据,在Python江湖中,这种数据称为【函数的参数】。【参数】指的是函数要接受、处理的数据,其实就是一个变量。 https://www.sodocs.net/doc/728437366.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子: https://www.sodocs.net/doc/728437366.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.sodocs.net/doc/728437366.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8') Python学习之Python应用领域介绍(一) 最近Python这个词可是在我们的生活里火了,无论是朋友圈还是身边的人,几乎所有人都知道Python,那Python到底有多大魅力呢,今天我们就从Python的一方面来分析,就是Python的应用领域有哪些。 下面就让我们一起来看看它的强大功能: Python(派森),它是一个简单的、解释型的、交互式的、可移植的、面向对象的超高级语言。这就是对Python语言的最简单的描述。 Python有一个交互式的开发环境,因为Python是解释运行,这大大节省了每次编译的时间。Python语法简单,且内置有几种高级数据结构,如字典、列表等,使得使用起来特别简单,程序员一个下午就可学会,一般人员一周内也可掌握。Python具有大部分面向对象语言的特征,可完全进行面向对象编程。它可以在MS-DOS、Windows、Windows NT、Linux、Soloris、Amiga、BeOS、OS/2、VMS、QNX等多种OS上运行。 编程语言 Python语言可以用来作为批处理语言,写一些简单工具,处理些数据,作为其他软件的接口调试等。Python语言可以用来作为函数语言,进行人工智能程序的开发,具有Lisp语言的大部分功能。Python语言可以用来作为过程语言,进行我们常见的应用程序开发,可以和VB等语言一样应用。Python 语言可以用来作为面向对象语言,具有大部分面向对象语言的特征,常作为大型应用软件的原型开发,再用C++改写,有些直接用Python来开发。 数据库 Python在数据库方面也很优秀,可以和多种数据库进行连接,进行数据处理,从商业型的数据库到开放源码的数据库都提供支持。例如:Oracle,Ms SQL Server等等。有多种接口可以与数据库进行连接,至少包括ODBC。有许多公司采用着Python+MySql的架构。因此,掌握了Python使你可以充分利用面向对象的特点,在数据库处理方面如虎添翼。 https://www.sodocs.net/doc/728437366.html, Python3中urllib详细使用方法_光环大数据Python培训python3 抓取网页资源的 N 种方法 1、最简单 import urllib.request response = urllib.request.urlopen(‘https://www.sodocs.net/doc/728437366.html,/’) html = response.read() 2、使用 Request import urllib.request req = urllib.request.Request(‘https://www.sodocs.net/doc/728437366.html,/’) response = urllib.request.urlopen(req) the_page = response.read() 3、发送数据 #! /usr/bin/env python3 import urllib.parse import urllib.request url = ‘http://localhost/login.php’ user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)’ https://www.sodocs.net/doc/728437366.html, values = { ‘act’ : ‘login’, ‘login[email]’ : ‘yzhang@https://www.sodocs.net/doc/728437366.html,’, ‘login[password]’ : ‘123456’ } data = urllib.parse.urlencode(values) req = urllib.request.Request(url, data) req.add_header(‘Referer’, ‘https://www.sodocs.net/doc/728437366.html,/’) response = urllib.request.urlopen(req) the_page = response.read() print(the_page.decode(“utf8”)) 4、发送数据和header #! /usr/bin/env python3 import urllib.parse import urllib.request url = ‘http://localhost/login.php’ user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)’values = { ‘act’ : ‘login’, ‘login[email]’ : ‘yzhang@https://www.sodocs.net/doc/728437366.html,’, ‘login[password]’ : ‘123456’ } 1.使用turtle 库绘制轮廓颜色为红色(red)、填充颜色为粉红色(pink)的心形图形,效果如下图所示。阅读程序框架,补充横线处代码。 from turtle import * color('red', ____①____) (____②____) left(135) fd(100) right(180) circle(50, –180) left(90) circle(50, –180) right(180) fd(100) end_fill() hideturtle() done() 输出 参考代码: from turtle import * color('red','pink') begin_fill() left(135) fd(100) right(180) circle(50,-180) left(90) circle(50,-180) right(180) fd(100) end_fill() hideturtle() done() 2.使用turtle 库绘制红色五角星图形,效果如下图所示。阅读程序框架,补充横线处代码。(____①____) setup(400,400) penup() goto(–100,50) pendown() color("red") begin_fill() for i in range(5): forward(200) (____②____) end_fill() hideturtle() done() 输出 参考代码: from turtle import * setup(400,400) penup() goto(-100,50) pendown() color("red") begin_fill() for i in range(5): forward(200) right(144) end_fill() hideturtle() done() 3. 使用turtle 库绘制正方形螺旋线,效果如下图所示。阅读程序框架,补充横线处代码。import turtle n = 10 1.使用 turtle 库绘制轮廓颜色为红色(red)、填充颜色为粉红色(pink)的心形图形,效果如下图所示。阅读程序框架,补充横线处代码。 from turtle import * color('red', ____①____) (____②____) left(135) fd(100) right(180) circle(50, –180) left(90) circle(50, –180) right(180) fd(100) end_fill() hideturtle() done() 输出 参考代码: from turtle import * color('red','pink') begin_fill() left(135) fd(100) right(180) circle(50,-180) left(90) circle(50,-180) right(180) fd(100) end_fill() hideturtle() done() 2.使用 turtle 库绘制红色五角星图形,效果如下图所示。阅读程序框架,补充横线处代码。(____①____) setup(400,400) penup() goto(–100,50) pendown() color("red") begin_fill() for i in range(5): forward(200) (____②____) end_fill() hideturtle() done() 输出 参考代码: from turtle import * setup(400,400) penup() goto(-100,50) pendown() color("red") begin_fill() for i in range(5): forward(200) right(144) end_fill() hideturtle() done() 3. 使用 turtle 库绘制正方形螺旋线,效果如下图所示。阅读程序框架,补充横线处代码。 import turtle n = 10 for i in range(1,10,1): for j in [90,180,–90,0]: (____①____) (____②____) n += 5 计算机病毒 实验报告 姓名:郭莎莎学号: 201306043023 培养类型:技术类年级: 2013级 专业:信息安全所属学院:计算机学院 指导教员:龙军职称:教授 实验室:实验日期: 2016.7.3 国防科学技术大学训练部制 《本科实验报告》填写说明 1.学员完成人才培养方案和课程标准要所要求的每个实验后,均须提交实验报告。 2.实验报告封面必须打印,报告内容可以手写或打印。 3.实验报告内容编排及打印应符合以下要求: (1)采用A4(21cm×29.7cm)白色复印纸,单面黑字打印。上下左右各侧的页边距均为3cm;缺省文档网格:字号为小4号,中文为宋体,英文和阿拉伯数字为Times New Roman,每页30行,每行36字;页脚距边界为2.5cm,页码置于页脚、居中,采用小5号阿拉伯数字从1开始连续编排,封面不编页码。 (2)报告正文最多可设四级标题,字体均为黑体,第一级标题字号为3号,其余各级标题为4号;标题序号第一级用“一、”、“二、”……,第二级用“(一)”、“(二)” ……,第三级用“1.”、“2.”……,第四级用“(1)”、“(2)” ……,分别按序连续编排。 (3)正文插图、表格中的文字字号均为5号。 实验题目 Python病毒功能实现 目录 一、实验目的 (4) 二、实验内容 (4) 三、实验原理 (4) (一)Linux病毒 (4) 1.Linux病毒的发展史 (4) 2.Linux平台下的病毒分类 (5) (二)文件型病毒 (6) 1.感染COM文件: (6) 2.感染EXE文件: (6) (三)python文件 (7) 四、实验所需软硬件 (8) 五、实验步骤 (8) (一)程序框架 (8) 1.传播感染模块 (8) 2.备份模块 (9) 3.触发和破坏模块 (9) (二)具体实现 (9) (三)结果截屏 (11) 六、实验结果与分析 (12) 七、思考与总结 (12) Python的特点 1. 简单 Python是一种代表简单思想的语言。 2. 易学 Python有极其简单的语法。 3. 免费、开源 Python是FLOSS(自由/开放源码软件)之一。 4. 高层语言 使用Python编写程序时无需考虑如何管理程序使用的内存一类的底层细节。 5. 可移植性 Python已被移植到很多平台,这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、 BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、 Windows CE甚至还有PocketPC。 6. 解释性 可以直接从源代码运行。在计算机内部,python解释器把源代码转换为字节码的中间形式,然后再把它翻译成计算机使用的机器语言。 7. 面向对象 Python既支持面向过程编程也支持面向对象编程。 8. 可扩展性 部分程序可以使用其他语言编写,如c/c++。 9. 可嵌入型 可以把Python嵌入到c/c++程序中,从而提供脚本功能。 10. 丰富的库 Python标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、 电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk 和其他与系统有关的操作。 ---------------分割线------------------------以下是Python的基本语法--------------------------------------------------------- 一、基本概念 基于python的网络爬虫设计【摘要】近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的利益,而网络爬虫是其中最为常用的 一种从网上爬取数据的手段。 网络爬虫,即Web Spider,是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页) 开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一 直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛 就可以用这个原理把互联网上所有的网页都抓取下来。 那么,既然网络爬虫有着如此先进快捷的特点,我们该如何实现它呢?在众多面向对象的语言中,首选python,因为python是一种“解释型的、面向对象的、带有动态语义的”高级程序,可以使人在编程时保 持自己的风格,并且编写的程序清晰易懂,有着很广阔的应用前景。 关键词python 爬虫数据 1 前言 1.1本编程设计的目的和意义 随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(例如传统的通用搜索引擎AltaVista,Yahoo!和Google等)作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如: (1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。 (2) 通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。 (3) 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频/视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。 (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(generalpurpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。 1.2编程设计目及思路 1.2.1编程设计目的 学习了解并熟练掌握python的语法规则和基本使用,对网络爬虫的基础知识进行了一定程度的理解,提高对网页源代码的认知水平,学习用正则表达式来完成匹配查找的工作,了解数据库的用途,学习mongodb数据库的安装和使用,及配合python的工作。 1.2.2设计思路 利用Python语言轻松爬取数据 对于小白来说,爬虫可能是一件非常复杂、技术门槛很高的事情。比如有人认为学爬虫必须精通Python,然后哼哧哼哧系统学习Python 的每个知识点,很久之后发现仍然爬不了数据;有的人则认为先要掌握网页的知识,遂开始HTML\CSS,结果还是入了前端的坑。下面告诉大家怎么样可以轻松爬取数据。 学习Python 包并完成根本的爬虫进程 大局部爬虫都是按“发送恳求——取得页面——解析页面——抽取并贮存内容”这样的流程来停止,这其实也是模仿了我们运用阅读器获取网页信息的进程。 Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,建议从requests+Xpath 开端,requests 担任衔接网站,前往网页,Xpath 用于解析网页,便于抽取数据。 假如你用过BeautifulSoup,会发现Xpath 要省事不少,一层一层反省元素代码的任务,全都省略了。这样上去根本套路都差不多,普通的静态网站基本不在话下,豆瓣、糗事百科、腾讯旧事等根本上都可以上手了。 当然假如你需求爬取异步加载的网站,可以学习阅读器抓包剖析真实恳求或许学习Selenium来完成自动化,这样,知乎、光阴网、猫途鹰这些静态的网站也可以迎刃而解。 学习scrapy,搭建工程化的爬虫 掌握后面的技术普通量级的数据和代码根本没有成绩了,但是在遇到十分复杂的状况,能够依然会力所能及,这个时分,弱小的scrapy 框架就十分有用了。 scrapy 是一个功用十分弱小的爬虫框架,它不只能便捷地构建request,还有弱小的selector 可以方便地解析response,但是它最让人惊喜的还是它超高的功能,让你可以将爬虫工程化、模块化。 学会scrapy,你可以本人去搭建一些爬虫框架,你就根本具有爬虫工程师的思想了。 掌握各种技巧,应对特殊网站的反爬措施 当然,爬虫进程中也会阅历一些绝望啊,比方被网站封IP、比方各种奇异的验证码、userAgent拜访限制、各种静态加载等等。遇到这些反爬虫的手腕,当然还需求一些初级的技巧来应对,惯例的比方拜访频率控制、运用代理IP池、抓包、验证码的OCR处置等等。 网络爬虫的四种语言 Python总结 目录 Python总结 (1) 前言 (2) (一)如何学习Python (2) (二)一些Python免费课程推荐 (3) (三)Python爬虫需要哪些知识? (4) (四)Python爬虫进阶 (6) (五)Python爬虫面试指南 (7) (六)推荐一些不错的Python博客 (8) (七)Python如何进阶 (9) (八)Python爬虫入门 (10) (九)Python开发微信公众号 (12) (十)Python面试概念和代码 (15) (十一)Python书籍 (23) 前言 知乎:路人甲 微博:玩数据的路人甲 微信公众号:一个程序员的日常 在知乎分享已经有一年多了,之前一直有朋友说我的回答能整理成书籍了,一直偷懒没做,最近有空仔细整理了知乎上的回答和文章另外也添加了一些新的内容,完成了几本小小的电子书,这一本是有关于Python方面的。 还有另外几本包括我的一些数据分析方面的读书笔记、增长黑客的读书笔记、机器学习十大算法等等内容。将会在我的微信公众号:一个程序员的日常进行更新,同时也可以关注我的知乎账号:路人甲及时关注我的最新分享用数据讲故事。 (一)如何学习Python 学习Python大致可以分为以下几个阶段: 1.刚上手的时候肯定是先过一遍Python最基本的知识,比如说:变量、数据结构、语法等,基础过的很快,基本上1~2周时间就能过完了,我当时是在这儿看的基础:Python 简介 | 菜鸟教程 2.看完基础后,就是做一些小项目巩固基础,比方说:做一个终端计算器,如果实在找不到什么练手项目,可以在Codecademy - learn to code, interactively, for free上面进行练习。 3. 如果时间充裕的话可以买一本讲Python基础的书籍比如《Python编程》,阅读这些书籍,在巩固一遍基础的同时你会发现自己诸多没有学习到的边边角角,这一步是对自己基础知识的补充。 4.Python库是Python的精华所在,可以说Python库组成并且造就了Python,Python 库是Python开发者的利器,所以学习Python库就显得尤为重要:The Python Standard Library,Python库很多,如果你没有时间全部看完,不妨学习一遍常用的Python库:Python常用库整理 - 知乎专栏 竭诚为您提供优质文档/双击可除python抓取网页表格数据 篇一:python导入excel数据 1、导入模块 importxlrd 2、打开excel文件读取数据 data=xlrd.open_workbook(excelFile.xls) 3、使用技巧 获取一个工作表 table=data.sheets()[0]#通过索引顺序获取 table=data.sheet_by_index(0)#通过索引顺序获取 table=data.sheet_by_name(usheet1)#通过名称获取获取整行和整列的值(数组) table.row_values(i) table.col_values(i) 获取行数和列数 ows=table.ows ncols=table.ncols 循环行列表数据 foriinrange(ows): printtable.row_values(i) 单元格 cell_a1=table.cell(0,0).value cell_c4=table.cell(2,3).value 使用行列索引 cell_a1=table.row(0)[0].value cell_a2=table.col(1)[0].value 简单的写入 row=0 col=0 #类型 0empty,1string,2number,3date,4boolean,5errorctype=1 value=单元格的值 xf=0#扩展的格式化 table.put_cell(row,col,ctype,value,xf) table.cell(0,0)#单元格的值 table.cell(0,0).value#单元格的值 篇二:python数据处理 cscipy科学计算库(第三方扩展库) https://www.sodocs.net/doc/728437366.html, python原有数据结构的变化基于Python的网络信息自动抓取系统毕业论文
Python实例应用
山东建筑大学计算机网络课程设计基于Python的网络爬虫设计
Python爬虫入门:如何爬取招聘网站并进行分析
Python的应用领域有哪些
python爬虫抓站的总结
第十三课人生苦短我用Python语法简单才会越来越被编程界欢迎
python抓取网页数据的常见方法
Python学习之Python应用领域介绍(一)
Python3中urllib详细使用方法_光环大数据Python培训
Python简单指导应用题
Python简单应用题
用python写的简单病毒(无害)资料
python基础语法
基于python的网络爬虫设计
利用Python语言轻松爬取数据
Python爬虫总结材料
python抓取网页表格数据
相关文档
- python爬虫抓站的总结
- 利用Python语言轻松爬取数据
- 基于python的网络爬虫设计
- 网络爬虫-Python和数据分析
- 基于python的网页爬虫
- 网页内容读取与网页爬虫
- python抓取网页数据
- Python爬虫入门:如何爬取招聘网站并进行分析
- 基于python的网络爬虫设计
- python爬虫技术 动态页面抓取超级指南_光环大数据Python培训
- 基于Python的图片爬虫程序设计
- Python3中urllib详细使用方法_光环大数据Python培训
- 利用Python语言轻松爬取数据[精品文档]
- python爬取的页面没有想要的数据,数据被隐藏
- Python 网络数据抓取课件
- 山东建筑大学计算机网络课程设计基于Python的网络爬虫设计
- 用python爬虫抓站的一些技巧总结 _ observer专栏杂记
- python抓取网页表格数据
- python抓取网页数据
- python抓取网页数据的常见方法