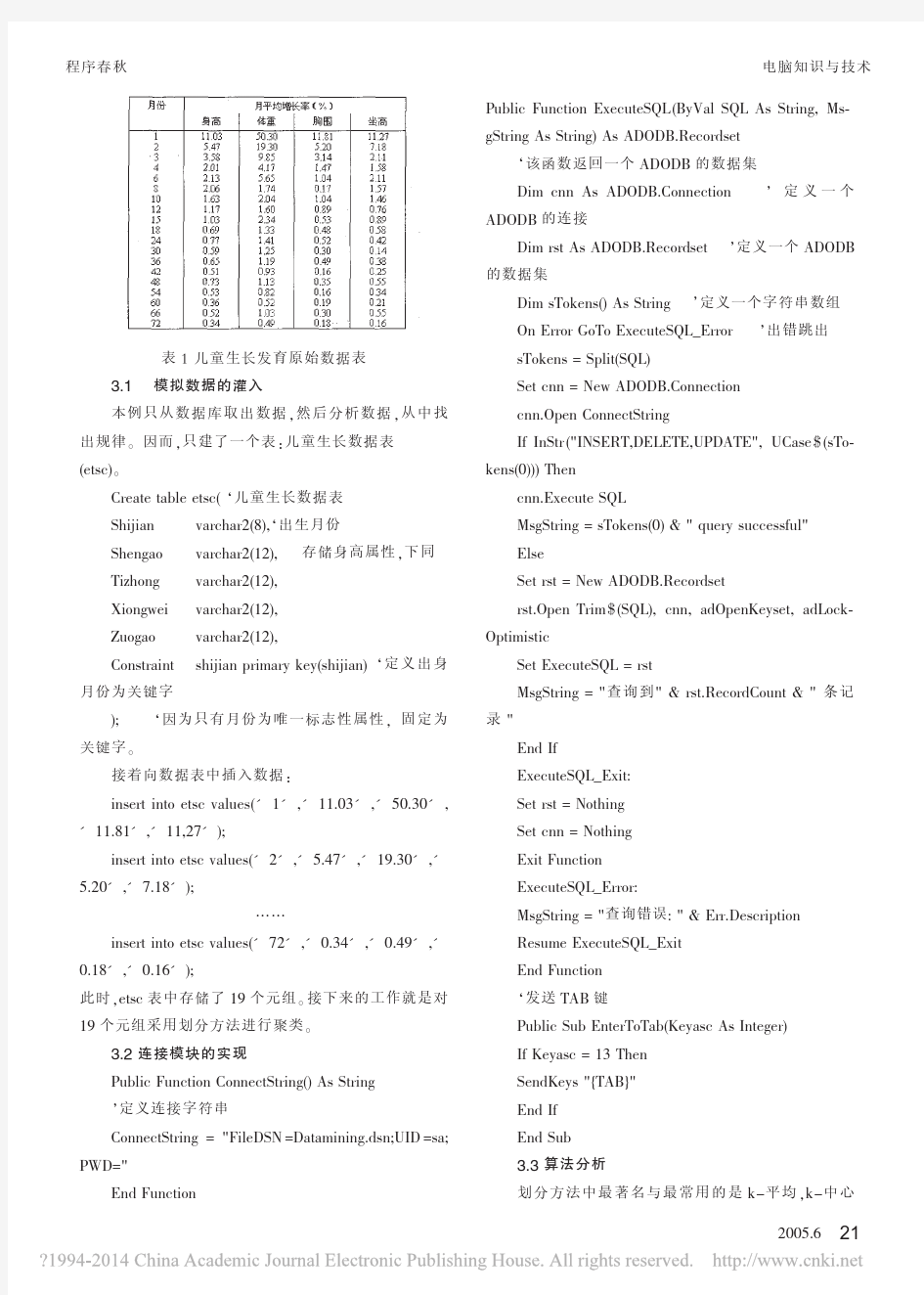
“K-中心点”聚类算法分析及其实现

模式识别最近邻和fisher分类matlab实验报告
一、Fisher 线性判别 Fisher 线性判别是统计模式识别的基本方法之一。它简单,容易实现,且计算量和存储量小,是实际应用中最常用的方法之一。Fisher 判别法Fisher 在1936年发表的论文中首次提出的线性判别法。Fisher 判别法的基本思想是寻找一个最好的投影,当特征向量x 从d 维空间映射到这个方向时,两类能最好的分开。这个方法实际上涉及到特征维数的压缩问题。 一维空间的Fisher 线性判别函数为: 2 1212 ()()F m m J w S S -= + (1) i m = ∑x N 1,i=1,2 (2) 2,1,)()(=--=∑∈i m x m x S T i x i i i ξ (3) 其中,1m 和2m 是两个样本的均值,1S ,2S 分别为各类样本的的类内离散度。投影方向w 为: )(211 m m S w w -=- (4) 12w S S S =+ (5) 在Fisher 判决函数中,分子反应了映射后两类中心的距离平方,该值越大,类间可分性越好;分母反应了两类的类内的离散度,其值越小越好;从总体上讲,()F J w 的值越大越好,在这种可分性评价标准下,使()F J w 达到最大值的w 即为最佳投影方向。
1.1、 Fisher线性判别实验流程图
1.2 Fisher线性判别mtalab代码 data=importdata('C:\Users\zzd\Desktop\data-ch5.mat'); data1=data.data; data2=https://www.sodocs.net/doc/639940539.html,bel; sample1=data1(1:25,:); sample2=data1(51:75,:); sample=[sample1 sample2]; sp_l=data2(26:75); test1=data1(26:50,:); test2=data1(76:100,:); test=[test1 test2]; lth=zeros(50,50); sample_m1=mean(sample1); sample_m2=mean(sample2); m1=sample_m1'; m2=sample_m2'; sb=(m1-m2)*(m1-m2)'; s1=zeros(2); for n=1:25 temp = (sample1(n,:)'-m1)*(sample1(n,:)'-m1)'; s1=s1+temp; end; s2=zeros(2); for n=1:25 temp = (sample2(n,:)'-m2)*(sample2(n,:)'-m2)'; s2 = s2+temp; end; sw=s1+s2; vw=inv(sw)*(m1-m2); a_m1 = vw'*m1; a_m2 = vw'*m2; w0 = (a_m1+a_m2)/2;
K - M e a n s 聚 类 算 法
基于K-means聚类算法的入侵检测系统的设计 基于K-means聚类算法的入侵检测系统的设计 今天给大家讲述的是K-means聚类算法在入侵检测系统中的应用首先,介绍一下 聚类算法 将认识对象进行分类是人类认识世界的一种重要方法,比如有关世界的时间进程的研究,就形成了历史学,有关世界空间地域的研究,则形成了地理学。 又如在生物学中,为了研究生物的演变,需要对生物进行分类,生物学家根据各种生物的特征,将它们归属于不同的界、门、纲、目、科、属、种之中。 事实上,分门别类地对事物进行研究,要远比在一个混杂多变的集合中更清晰、明了和细致,这是因为同一类事物会具有更多的近似特性。 通常,人们可以凭经验和专业知识来实现分类。而聚类分析(cluster analysis)作为一种定量方法,将从数据分析的角度,给出一个更准确、细致的分类工具。 (聚类分析我们说得朴实一点叫做多元统计分析,说得时髦一点叫做数据挖掘算法,因为这个算法可以在一堆数据中获取很有用的信息,这就不就是数据挖掘吗,所以大家平时也不要被那些高大上的名词给吓到了,它背后的核心原理大多数我们都是可以略懂一二的,再
比如说现在AI这么火,如果大家还有印象的话,以前我们在大二上学习概率论的时候,我也和大家分享过自然语言处理的数学原理,就是如何让机器人理解我们人类的自然语言,比如说,苹果手机上的Siri系统,当时还让杨帆同学帮我在黑板上写了三句话,其实就是贝叶斯公式+隐含马尔可夫链。估计大家不记得了,扯得有点远了接下来还是回归我们的正题,今天要讨论的聚类算法。) K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,结果稳定,聚类的效果也还不错, 相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:如何定量计算两个可比较元素间的相异度。用通俗的话说,相异度就是两个东西差别有多大,例如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能我们直观感受到的。但是,计算机没有这种直观感受能力,我们必须对相异度在数学上进行定量定义。 要用数量化的方法对事物进行分类,就必须用数量化的方法描述事物之间的相似程度。一个事物常常需要用多个特征变量来刻画,就比如说我们举一个例证,就有一项比较神奇的技术叫面部识别技术,其实听起来很高大上,它是如何做到的,提取一个人的面部特征,比如说嘴巴的长度,鼻梁的高度,眼睛中心到鼻子的距离,鼻子到嘴巴的距离,这些指标对应得数值可以组成一个向量作为每一个个体的一个标度变量(),或者说叫做每一个人的一个特征向量。 如果对于一群有待分类的样本点需用p 个特征变量值描述,则每
聚类分析算法解析.doc
聚类分析算法解析 一、不相似矩阵计算 1.加载数据 data(iris) str(iris) 分类分析是无指导的分类,所以删除数据中的原分类变量。 iris$Species<-NULL 2. 不相似矩阵计算 不相似矩阵计算,也就是距离矩阵计算,在R中采用dist()函数,或者cluster包中的daisy()函数。dist()函数的基本形式是 dist(x, method = "euclidean", diag = FALSE, upper = FALSE, p = 2) 其中x是数据框(数据集),而方法可以指定为欧式距离"euclidean", 最大距离"maximum", 绝对值距离"manhattan", "canberra", 二进制距离非对称"binary" 和明氏距离"minkowski"。默认是计算欧式距离,所有的属性必须是相同的类型。比如都是连续类型,或者都是二值类型。 dd<-dist(iris) str(dd) 距离矩阵可以使用as.matrix()函数转化了矩阵的形式,方便显示。Iris数据共150例样本间距离矩阵为150行列的方阵。下面显示了1~5号样本间的欧式距离。 dd<-as.matrix(dd)
二、用hclust()进行谱系聚类法(层次聚类) 1.聚类函数 R中自带的聚类函数是hclust(),为谱系聚类法。基本的函数指令是 结果对象 <- hclust(距离对象, method=方法) hclust()可以使用的类间距离计算方法包含离差法"ward",最短距离法"single",最大距离法"complete",平均距离法"average","mcquitty",中位数法 "median" 和重心法"centroid"。下面采用平均距离法聚类。 hc <- hclust(dist(iris), method="ave") 2.聚类函数的结果 聚类结果对象包含很多聚类分析的结果,可以使用数据分量的方法列出相应的计算结果。 str(hc) 下面列出了聚类结果对象hc包含的merge和height结果值的前6个。其行编号表示聚类过程的步骤,X1,X2表示在该步合并的两类,该编号为负代表原始的样本序号,编号为正代表新合成的类;变量height表示合并时两类类间距离。比如第1步,合并的是样本102和143,其样本间距离是0.0,合并后的类则使用该步的步数编号代表,即样本-102和-143合并为1类。再如第6行表示样本11和49合并,该两个样本的类间距离是0.1,合并后的类称为6类。 head (hc$merge,hc$height)
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.sodocs.net/doc/639940539.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.sodocs.net/doc/639940539.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
聚类分析K-means算法综述
聚类分析K-means算法综述 摘要:介绍K-means聚类算法的概念,初步了解算法的基本步骤,通过对算法缺点的分析,对算法已有的优化方法进行简单分析,以及对算法的应用领域、算法未来的研究方向及应用发展趋势作恰当的介绍。 关键词:K-means聚类算法基本步骤优化方法应用领域研究方向应用发展趋势 算法概述 K-means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足方差最小标准的k个聚类。 评定标准:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算。 解释:基于质心的划分方法就是将簇中的所有对象的平均值看做簇的质心,然后根据一个数据对象与簇质心的距离,再将该对象赋予最近的簇。 k-means 算法基本步骤 (1)从n个数据对象任意选择k 个对象作为初始聚类中心 (2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分 (3)重新计算每个(有变化)聚类的均值(中心对象) (4)计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到步骤(2) 形式化描述 输入:数据集D,划分簇的个数k 输出:k个簇的集合 (1)从数据集D中任意选择k个对象作为初始簇的中心; (2)Repeat (3)For数据集D中每个对象P do (4)计算对象P到k个簇中心的距离 (5)将对象P指派到与其最近(距离最短)的簇;
(6)End For (7)计算每个簇中对象的均值,作为新的簇的中心; (8)Until k个簇的簇中心不再发生变化 对算法已有优化方法的分析 (1)K-means算法中聚类个数K需要预先给定 这个K值的选定是非常难以估计的,很多时候,我们事先并不知道给定的数据集应该分成多少个类别才最合适,这也是K一means算法的一个不足"有的算法是通过类的自动合并和分裂得到较为合理的类型数目k,例如Is0DAIA算法"关于K一means算法中聚类数目K 值的确定,在文献中,根据了方差分析理论,应用混合F统计量来确定最佳分类数,并应用了模糊划分嫡来验证最佳分类数的正确性。在文献中,使用了一种结合全协方差矩阵RPCL算法,并逐步删除那些只包含少量训练数据的类。文献中针对“聚类的有效性问题”提出武汉理工大学硕士学位论文了一种新的有效性指标:V(k km) = Intra(k) + Inter(k) / Inter(k max),其中k max是可聚类的最大数目,目的是选择最佳聚类个数使得有效性指标达到最小。文献中使用的是一种称为次胜者受罚的竞争学习规则来自动决定类的适当数目"它的思想是:对每个输入而言不仅竞争获胜单元的权值被修正以适应输入值,而且对次胜单元采用惩罚的方法使之远离输入值。 (2)算法对初始值的选取依赖性极大以及算法常陷入局部极小解 不同的初始值,结果往往不同。K-means算法首先随机地选取k个点作为初始聚类种子,再利用迭代的重定位技术直到算法收敛。因此,初值的不同可能导致算法聚类效果的不稳定,并且,K-means算法常采用误差平方和准则函数作为聚类准则函数(目标函数)。目标函数往往存在很多个局部极小值,只有一个属于全局最小,由于算法每次开始选取的初始聚类中心落入非凸函数曲面的“位置”往往偏离全局最优解的搜索范围,因此通过迭代运算,目标函数常常达到局部最小,得不到全局最小。对于这个问题的解决,许多算法采用遗传算法(GA),例如文献中采用遗传算法GA进行初始化,以内部聚类准则作为评价指标。 (3)从K-means算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大 所以需要对算法的时间复杂度进行分析,改进提高算法应用范围。在文献中从该算法的时间复杂度进行分析考虑,通过一定的相似性准则来去掉聚类中心的候选集,而在文献中,使用的K-meanS算法是对样本数据进行聚类。无论是初始点的选择还是一次迭代完成时对数据的调整,都是建立在随机选取的样本数据的基础之上,这样可以提高算法的收敛速度。
(完整版)聚类算法总结
1.聚类定义 “聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有一些相似的属性”——wikipedia “聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。它是一种重要的人类行为。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。”——百度百科 说白了,聚类(clustering)是完全可以按字面意思来理解的——将相同、相似、相近、相关的对象实例聚成一类的过程。简单理解,如果一个数据集合包含N个实例,根据某种准则可以将这N 个实例划分为m个类别,每个类别中的实例都是相关的,而不同类别之间是区别的也就是不相关的,这个过程就叫聚类了。 2.聚类过程: 1) 数据准备:包括特征标准化和降维. 2) 特征选择:从最初的特征中选择最有效的特征,并将其存储于向量中. 3) 特征提取:通过对所选择的特征进行转换形成新的突出特征.
4) 聚类(或分组):首先选择合适特征类型的某种距离函数(或构造新的距离函数)进行接近程度的度量;而后执行聚类或分组. 5) 聚类结果评估:是指对聚类结果进行评估.评估主要有3 种:外部有效性评估、内部有效性评估和相关性测试评估. 3聚类算法的类别 没有任何一种聚类技术(聚类算法)可以普遍适用于揭示各种多维数据集所呈现出来的多种多样的结构,根据数据在聚类中的积聚规则以及应用这些规则的方法,有多种聚类算法.聚类算法有多种分类方法将聚类算法大致分成层次化聚类算法、划分式聚类算法、基于密度和网格的聚类算法和其他聚类算法,如图1 所示 的4 个类别.
Parzen窗估计与KN近邻估计实验报告
模式识别实验报告 题目:Parzen 窗估计与KN 近邻估计 学 院 计算机科学与技术 专 业 xxxxxxxxxxxxxxxx 学 号 xxxxxxxxxxxx 姓 名 xxxx 指导教师 xxxx 20xx 年xx 月xx 日 Parzen 窗估计与KN 近邻估计 装 订 线
一、实验目的 本实验的目的是学习Parzen窗估计和k最近邻估计方法。在之前的模式识别研究中,我们假设概率密度函数的参数形式已知,即判别函数J(.)的参数是已知的。本节使用非参数化的方法来处理任意形式的概率分布而不必事先考虑概率密度的参数形式。在模式识别中有躲在令人感兴趣的非参数化方法,Parzen窗估计和k最近邻估计就是两种经典的估计法。二、实验原理 1.非参数化概率密度的估计 对于未知概率密度函数的估计方法,其核心思想是:一个向量x落在区域R中的概率可表示为: 其中,P是概率密度函数p(x)的平滑版本,因此可以通过计算P来估计概率密度函数p(x),假设n个样本x1,x2,…,xn,是根据概率密度函数p(x)独立同分布的抽取得到,这样,有k个样本落在区域R中的概率服从以下分布: 其中k的期望值为: k的分布在均值附近有着非常显著的波峰,因此若样本个数n足够大时,使用k/n作为概率P的一个估计将非常准确。假设p(x)是连续的,且区域R足够小,则有: 如下图所示,以上公式产生一个特定值的相对概率,当n趋近于无穷大时,曲线的形状逼近一个δ函数,该函数即是真实的概率。公式中的V是区域R所包含的体积。综上所述,可以得到关于概率密度函数p(x)的估计为:
在实际中,为了估计x处的概率密度函数,需要构造包含点x的区域R1,R2,…,Rn。第一个区域使用1个样本,第二个区域使用2个样本,以此类推。记Vn为Rn的体积。kn为落在区间Rn中的样本个数,而pn (x)表示为对p(x)的第n次估计: 欲满足pn(x)收敛:pn(x)→p(x),需要满足以下三个条件: 有两种经常采用的获得这种区域序列的途径,如下图所示。其中“Parzen窗方法”就是根据某一个确定的体积函数,比如Vn=1/√n来逐渐收缩一个给定的初始区间。这就要求随机变量kn和kn/n能够保证pn (x)能收敛到p(x)。第二种“k-近邻法”则是先确定kn为n的某个函数,如kn=√n。这样,体积需要逐渐生长,直到最后能包含进x的kn个相邻点。
利用K-Means聚类进行航空公司客户价值分析
利用K-Means聚类进行航空公司客户价值分析 1.背景与挖掘目标 1.1背景航空公司业务竞争激烈,从 产品中心转化为客户中心。针对不同类型客户,进行精准营 销,实现利润最大化。建立客户价值评估模型,进行客户分 类,是解决问题的办法 1.2挖掘目标借助航空公司客户数据, 对客户进行分类。对不同的客户类别进行特征分析,比较不 同类客户的客户价值对不同价值的客户类别提供个性化服 务,制定相应的营销策略。详情数据见数据集内容中的 air_data.csv和客户信息属性说明 2.分析方法与过程 2.1分析方法首先,明确目标是客户价值识别。识别客户价值,应用 最广泛的模型是三个指标(消费时间间隔(Recency),消费频率(Frequency),消费金额(Monetary))以上指标简称RFM 模型,作用是识别高价值的客户消费金额,一般表示一段时 间内,消费的总额。但是,因为航空票价收到距离和舱位等 级的影响,同样金额对航空公司价值不同。因此,需要修改 指标。选定变量,舱位因素=舱位所对应的折扣系数的平均 值=C,距离因素=一定时间内积累的飞行里程=M。再考虑到,航空公司的会员系统,用户的入会时间长短能在一定程度上 影响客户价值,所以增加指标L=入会时间长度=客户关系长度总共确定了五个指标,消费时间间隔R,客户关系长度L,消费频率F,飞行里程M和折扣系数的平均值C以上指标,
作为航空公司识别客户价值指标,记为LRFMC模型如果采用传统的RFM模型,如下图。它是依据,各个属性的平均 值进行划分,但是,细分的客户群太多,精准营销的成本太 高。 综上,这次案例,采用聚类的办法进行识别客户价值,以LRFMC模型为基础本案例,总体流程如下图 2.2挖掘步骤从航空公司,选择性抽取与新增数据抽取,形 成历史数据和增量数据对步骤一的两个数据,进行数据探索 性分析和预处理,主要有缺失值与异常值的分析处理,属性 规约、清洗和变换利用步骤2中的已处理数据作为建模数据,基于旅客价值的LRFMC模型进行客户分群,对各个客户群 再进行特征分析,识别有价值客户。针对模型结果得到不同 价值的客户,采用不同的营销手段,指定定制化的营销服务,或者针对性的优惠与关怀。(重点维护老客户) 2.3数据抽取选取,2014-03-31为结束时间,选取宽度为两年的时间段, 作为观测窗口,抽取观测窗口内所有客户的详细数据,形成 历史数据对于后续新增的客户信息,采用目前的时间作为重 点,形成新增数据 2.4探索性分析本案例的探索分析,主要 对数据进行缺失值和异常值分析。发现,存在票价为控制, 折扣率为0,飞行公里数为0。票价为空值,可能是不存在 飞行记录,其他空值可能是,飞机票来自于积分兑换等渠道,查找每列属性观测值中空值的个数、最大值、最小值的代码
第9章rapidminer_k_means聚类.辨别分析v1
第9章K-Means 聚类、辨别分析 9.1理解聚类分析 餐饮企业经常会碰到这样的问题: 1)如何通过餐饮客户消费行为的测量,进一步评判餐饮客户的价值和对餐饮客户进行细分,找到有价值的客户群和需关注的客户群? 2)如何合理对菜品进行分析,以便区分哪些菜品畅销毛利又高,哪些菜品滞销毛利又低? 餐饮企业遇到的这些问题,可以通过聚类分析解决。 9.1.1常用聚类分析算法 与分类不同,聚类分析是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。与分类模型需要使用有类标记样本构成的训练数据不同,聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将他们划分为若干组,划分的原则是组样本最小化而组间(外部)距离最大化,如图9-1所示。 图9-1 聚类分析建模原理 常用聚类方法见表9-1。 表9-1常用聚类方法 类别包括的主要算法
常用聚类算法见图9-2。 表9-2常用聚类分析算法 9.1.2K-Means聚类算法 K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。 1.算法过程 1)从N个样本数据中随机选取K个对象作为初始的聚类中心; 2)分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中; 3)所有对象分配完成后,重新计算K个聚类的中心; 4)与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转2),否则转 5); 5)当质心不发生变化时停止并输出聚类结果。 聚类的结果可能依赖于初始聚类中心的随机选择,可能使得结果严重偏离全局最优分类。实践中,为了得到较好的结果,通常以不同的初始聚类中心,多次运行K-Means算法。在所有对象分配完成后,重新计算K个聚类的中心时,对于连续数据,聚类中心取该簇的均值,但是当样本的某些属性是分类变量时,均值可能无定义,可以使用K-众数方
聚类算法比较
聚类算法: 1. 划分法:K-MEANS算法、K-M EDOIDS算法、CLARANS算法; 1)K-means 算法: 基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。 K-Means聚类算法主要分为三个步骤: (1)第一步是为待聚类的点寻找聚类中心 (2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去 (3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心 反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止 下图展示了对n个样本点进行K-means聚类的效果,这里k取2: (a)未聚类的初始点集 (b)随机选取两个点作为聚类中心 (c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去 (d)计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心 (e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去 (f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心 优点: 1.算法快速、简单; 2.对大数据集有较高的效率并且是可伸缩性的; 3.时间复杂度近于线性,而且适合挖掘大规模数据集。 缺点: 1. 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。 2. 在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响。
KNN算法实验报告
KNN算法实验报告 一试验原理 K最近邻(k-NearestNeighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。 该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决 定待分样本所属的类别。KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。 KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比。 该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量
并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。 二试验步骤 那么根据以上的描述,我把结合使用反余弦匹配和kNN结合的过程分成以下几个步骤: 1.计算出样本数据和待分类数据的距离 2.为待分类数据选择k个与其距离最小的样本 3.统计出k个样本中大多数样本所属的分类 4.这个分类就是待分类数据所属的分类 数学表达:目标函数值可以是离散值(分类问题),也可以是连续值(回归问题).函数形势为f:n维空间R—〉一维空间R。 第一步:将数据集分为训练集(DTrn)和测试集(DTES)。 第二步:在测试集给定一个实例Xq;在训练集(DTrn)中找到与这个实例Xq的K-最近邻子集{X1、、、、XK},即:DKNN。 第三步:计算这K-最近邻子集得目标值,经过加权平均: ^f(Xq)=(f(X1)+...+f(XK))/k作为f(Xq)的近似估计。改进的地方:对
聚类算法分析报告汇总
嵌入式方向工程设计实验报告 学院班级:130712 学生学号:13071219 学生姓名:杨阳 同作者:无 实验日期:2010年12月
聚类算法分析研究 1 实验环境以及所用到的主要软件 Windows Vista NetBeans6.5.1 Weka3.6 MATLAB R2009a 2 实验内容描述 聚类是对数据对象进行划分的一种过程,与分类不同的是,它所划分的类是未知的,故此,这是一个“无指导的学习” 过程,它倾向于数据的自然划分。其中聚类算法常见的有基于层次方法、基于划分方法、基于密度以及网格等方法。本文中对近年来聚类算法的研究现状与新进展进行归纳总结。一方面对近年来提出的较有代表性的聚类算法,从算法思想。关键技术和优缺点等方面进行分析概括;另一方面选择一些典型的聚类算法和一些知名的数据集,主要从正确率和运行效率两个方面进行模拟实验,并分别就同一种聚类算法、不同的数据集以及同一个数据集、不同的聚类算法的聚类情况进行对比分析。最后通过综合上述两方面信息给出聚类分析的研究热点、难点、不足和有待解决的一些问题等。 实验中主要选择了K 均值聚类算法、FCM 模糊聚类算法并以UCI Machine Learning Repository 网站下载的IRIS 和WINE 数据集为基础通过MATLAB 实现对上述算法的实验测试。然后以WINE 数据集在学习了解Weka 软件接口方面的基础后作聚类分析,使用最常见的K 均值(即K-means )聚类算法和FCM 模糊聚类算法。下面简单描述一下K 均值聚类的步骤。 K 均值算法首先随机的指定K 个类中心。然后: (1)将每个实例分配到距它最近的类中心,得到K 个类; (2)计分别计算各类中所有实例的均值,把它们作为各类新的类中心。 重复(1)和(2),直到K 个类中心的位置都固定,类的分配也固定。 在实验过程中通过利用Weka 软件中提供的simpleKmeans (也就是K 均值聚类算法对WINE 数据集进行聚类分析,更深刻的理解k 均值算法,并通过对实验结果进行观察分析,找出实验中所存在的问题。然后再在学习了解Weka 软件接口方面的基础上对Weka 软件进行一定的扩展以加入新的聚类算法来实现基于Weka 平台的聚类分析。 3 实验过程 3.1 K 均值聚类算法 3.1.1 K 均值聚类算法理论 K 均值算法是一种硬划分方法,简单流行但其也存在一些问题诸如其划分结果并不一定完全可信。K 均值算法的划分理论基础是 2 1 min i c k i k A i x v ∈=-∑∑ (1) 其中c 是划分的聚类数,i A 是已经属于第i 类的数据集i v 是相应的点到第i 类的平均距离,即
自动确定聚类中心的势能聚类算法
自动确定聚类中心的势能聚类算法* 于晓飞1,葛洪伟1,2+ 1.江南大学物联网工程学院,江苏无锡214122 2.江南大学轻工过程先进控制教育部重点实验室,江苏无锡214122 Potential Clustering by Automatic Determination of Cluster Centers YU Xiaofei 1,GE Hongwei 1,2+ 1.School of Internet of Things Engineering,Jiangnan University,Wuxi,Jiangsu 214122,China 2.Ministry of Education Key Laboratory of Advanced Process Control for Light Industry,Jiangnan University,Wuxi,Jiangsu 214122,China +Corresponding author:E-mail:ghw8601@https://www.sodocs.net/doc/639940539.html, YU Xiaofei,GE Hongwei.Potential clustering by automatic determination of cluster centers.Journal of Fron-tiers of Computer Science and Technology,2018,12(6):1004-1012. Abstract:Potential-based hierarchical agglomerative clustering (PHA)uses a new similarity metric to get clustering results more efficiently.However,it suffers from the problem how to determine the number of clusters automatically.And it assigns samples according to distance measure,which ignores the influence of potential.To overcome these shortcomings,this paper proposes a new algorithm that can determine the number of clusters automatically.Firstly,two variables are used to find the clustering centers automatically:the potential of each point and the distance from points to their parent nodes.Then,the distance and the potential are used to assign the remaining points.Finally,the experiments on artificial data sets and real data sets show that the new algorithm not only determines the number of clusters automatically,but also has better clustering results. Key words:clustering;potential-based hierarchical agglomerative clustering (PHA);potential clustering;automati-cally determining the number of clustering *The National Natural Science Foundation of China under Grant No.61305017(国家自然科学基金);the Research Innovation Pro-gram for College Graduates of Jiangsu Province under Grant No.KYLX15_1169(江苏省普通高校研究生科研创新计划项目).Received 2017-02,Accepted 2017-04. CNKI 网络出版:2017-04-13,https://www.sodocs.net/doc/639940539.html,/kcms/detail/11.5602.TP.20170413.1027.004.html ISSN 1673-9418CODEN JKYTA8 Journal of Frontiers of Computer Science and Technology 1673-9418/2018/12(06)-1004-09 doi:10.3778/j.issn.1673-9418.1702048E-mail:fcst@https://www.sodocs.net/doc/639940539.html, https://www.sodocs.net/doc/639940539.html, Tel:+86-10-89056056万方数据
数据挖掘实验报告
数据挖掘实验报告 ——加权K-近邻法 一、 数据源说明 1. 数据理解 数据来自于天猫对顾客的BuyOrNot(买与不买),BuyDNactDN(消费活跃度),ActDNTotalDN(活跃度),BuyBBrand(成交有效度),BuyHit(活动有效度)这五个变量的统计。 数据分成两类数据,一类作为训练数据集,一类为测试数据集。 2.数据清理 现实世界的数据一般是不完整的、有噪声的和不一致的。数据清理例程试图填充缺失的值,光滑噪声并识别离群点,并纠正数据中的不一致。 a) 缺失值:当数据中存在缺失值是,忽略该元组 b) 噪声数据:本文暂没考虑。 二、 基于变量重要性的加权K-近邻法[1] 由于我们计算K-近邻法默认输入变量在距离测度中有“同等重要”的贡献,但情况并不总是如此。我们知道不同的变量对我们所要预测的变量的作用是不一定一样的,所以找出对输出变量分类预测有意义的重要变量对数据预测具有重要作用。同时也可以减少那些对输出变量分类预测无意义的输入变量,减少模型的变量。为此,采用基于变量重要性的K-近邻法,计算加权距离,给重要的变量赋予较高的权重,不重要的变量赋予较低的权重是必要的。 (1)算法思路: 我们引进1w 为第i 个输入变量的权重,是输入变量重要性(也称特征重要性),FI 函数,定义为:∑== p j i FI FI 1 ) i ()((i)w 。其中(i)FI 为第i 个输入变量的特征重要性, ∑=<1,1w )((i)i w 这里,(i)FI 依第i 个输入变量对预测误差的影响定义。设输入 变量集合包含p 个变量:p x x x x ,...,,,321。剔除第i 个变量后计算输入变量
人工智能实验报告
人工智能课程项目报告 姓名: 班级:二班
一、实验背景 在新的时代背景下,人工智能这一重要的计算机学科分支,焕发出了他强大的生命力。不仅仅为了完成课程设计,作为计算机专业的学生, 了解他,学习他我认为都是很有必要的。 二、实验目的 识别手写字体0~9 三、实验原理 用K-最近邻算法对数据进行分类。逻辑回归算法(仅分类0和1)四、实验内容 使用knn算法: 1.创建一个1024列矩阵载入训练集每一行存一个训练集 2. 把测试集中的一个文件转化为一个1024列的矩阵。 3.使用knnClassify()进行测试 4.依据k的值,得出结果 使用逻辑回归: 1.创建一个1024列矩阵载入训练集每一行存一个训练集 2. 把测试集中的一个文件转化为一个1024列的矩阵。 3. 使用上式求参数。步长0.07,迭代10次 4.使用参数以及逻辑回归函数对测试数据处理,根据结果判断测试数 据类型。 五、实验结果与分析 5.1 实验环境与工具 Window7旗舰版+ python2.7.10 + numpy(库)+ notepad++(编辑)
Python这一语言的发展是非常迅速的,既然他支持在window下运行就不必去搞虚拟机。 5.2 实验数据集与参数设置 Knn算法: 训练数据1934个,测试数据有946个。
数据包括数字0-9的手写体。每个数字大约有200个样本。 每个样本保持在一个txt文件中。手写体图像本身的大小是32x32的二值图,转换到txt文件保存后,内容也是32x32个数字,0或者1,如下图所 示 建立一个kNN.py脚本文件,文件里面包含三个函数,一个用来生成将每个样本的txt文件转换为对应的一个向量:img2vector(filename):,一个用 来加载整个数据库loadDataSet():,最后就是实现测试。
利用K-Means聚类进行航空公司客户价值分析.doc
利用 K-Means 聚类进行航空公司客户价值分析 1.背景与挖掘目标 1.1 背景航空公司业务竞争激烈,从 产品中心转化为客户中心。针对不同类型客户,进行精准营 销,实现利润最大化。建立客户价值评估模型,进行客户分 类,是解决问题的办法 1.2 挖掘目标借助航空公司客户数据,对客户进行分类。对不同的客户类别进行特征分析,比较不 同类客户的客户价值对不同价值的客户类别提供个性化服 务,制定相应的营销策略。详情数据见数据集内容中的 air_data.csv 和客户信息属性说明 2.分析方法与过程 2.1 分析方法首先,明确目标是客户价值识别。识别客户价值,应用 最广泛的模型是三个指标(消费时间间隔(Recency) ,消费 频率( Frequency),消费金额( Monetary ))以上指标简称RFM 模型,作用是识别高价值的客户消费金额,一般表示一段时 间内,消费的总额。但是,因为航空票价收到距离和舱位等 级的影响,同样金额对航空公司价值不同。因此,需要修改 指标。选定变量,舱位因素=舱位所对应的折扣系数的平均 值=C,距离因素 =一定时间内积累的飞行里程 =M 。再考虑到,航空公司的会员系统,用户的入会时间长短能在一定程度上 影响客户价值,所以增加指标 L= 入会时间长度 =客户关系长度总共确定了五个指标,消费时间间隔 R,客户关系长度 L ,消费频率 F,飞行里程 M 和折扣系数的平均值 C 以上指标,
作为航空公司识别客户价值指标,记为LRFMC 模型如果采用传统的 RFM 模型,如下图。它是依据,各个属性的平均 值进行划分,但是,细分的客户群太多,精准营销的成本太 高。 综上,这次案例,采用聚类的办法进行识别客户价值,以LRFMC 模型为基础本案例,总体流程如下图 2.2 挖掘步骤从航空公司,选择性抽取与新增数据抽取,形 成历史数据和增量数据对步骤一的两个数据,进行数据探索 性分析和预处理,主要有缺失值与异常值的分析处理,属性 规约、清洗和变换利用步骤 2 中的已处理数据作为建模数据, 基于旅客价值的 LRFMC 模型进行客户分群,对各个客户群再 进行特征分析,识别有价值客户。针对模型结果得到不同 价值的客户,采用不同的营销手段,指定定制化的营销服务,或者针对性的优惠与关怀。(重点维护老客户) 2.3 数据抽取选取, 2014-03-31 为结束时间,选取宽度为两年的时间段,作为观测窗口,抽取观测窗口内所有客户的详细数据,形成 历史数据对于后续新增的客户信息,采用目前的时间作为重 点,形成新增数据 2.4 探索性分析本案例的探索分析,主要对 数据进行缺失值和异常值分析。发现,存在票价为控制,折扣 率为 0,飞行公里数为 0。票价为空值,可能是不存在飞行记录,其他空值可能是,飞机票来自于积分兑换等渠道,查找 每列属性观测值中空值的个数、最大值、最小值的代码
聚类分析法总结
聚类分析法 先用一个例子引出聚类分析 一、聚类分析法的概念 聚类分析又叫群分析、点群分析或者簇分析,是研究多要素事物分类问题的数量,并根据研究对象特征对研究对象进行分类的多元分析技术,它将样本或变量按照亲疏的程度,把性质相近的归为一类,使得同一类中的个体都具有高度的同质性,不同类之间的个体都具有高度的异质性。 聚类分析的基本原理是根据样本自身的属性,用数学方法按照某种相似性或差异性指标,定量地确定样本之间的亲疏关系,并按这种亲疏关系程度对样本进行聚类。 描述亲属程度通常有两种方法:一种是把样本或变量看出那个p维向量,样本点看成P 维空间的一个点,定义点与点之间的距离;另一种是用样本间的相似系数来描述其亲疏程度。有了距离和相似系数就可定量地对样本进行分组,根据分类函数将差异最小的归为一组,组与组之间再按分类函数进一步归类,直到所有样本归为一类为止。 聚类分析根据分类对象的不同分为Q型和R型两类,Q--型聚类是对样本进行分类处理,R--型聚类是对变量进行分类处理。 聚类分析的基本思想是,对于位置类别的样本或变量,依据相应的定义把它们分为若干类,分类过程是一个逐步减少类别的过程,在每一个聚类层次,必须满足“类内差异小,类间差异大”原则,直至归为一类。评价聚类效果的指标一般是方差,距离小的样品所组成的类方差较小。 常见的聚类分析方法有系统聚类法、动态聚类法(逐步聚类法)、有序样本聚类法、图论聚类法和模糊聚类法等。 二、对聚类分析法的评价 聚类分析也是一种分类技术。与多元分析的其他方法相比,该方法较为粗糙,理论上还不完善,但应用方面取得了很大成功。与回归分析、判别分析一起被称为多元分析的三大方法。 聚类的目的:根据已知数据,计算各观察个体或变量之间亲疏关系的统计量(距离或相关系数)。根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的