声音处理软件 GoldWave-声音降噪处理
开奇学堂免费教程声音处理软件GoldWave-声音降噪处理
我们录制的声音有噪声吗,应该是肯定有的,去掉声音中的噪声是一件很困难的事,因为各种各样的波形混合在一起,要把某些波形去掉是不可能的,而这个GoldWave软件却能将噪声大大减少。
要知道怎么降低噪声,我们先看噪声是怎么产生的。
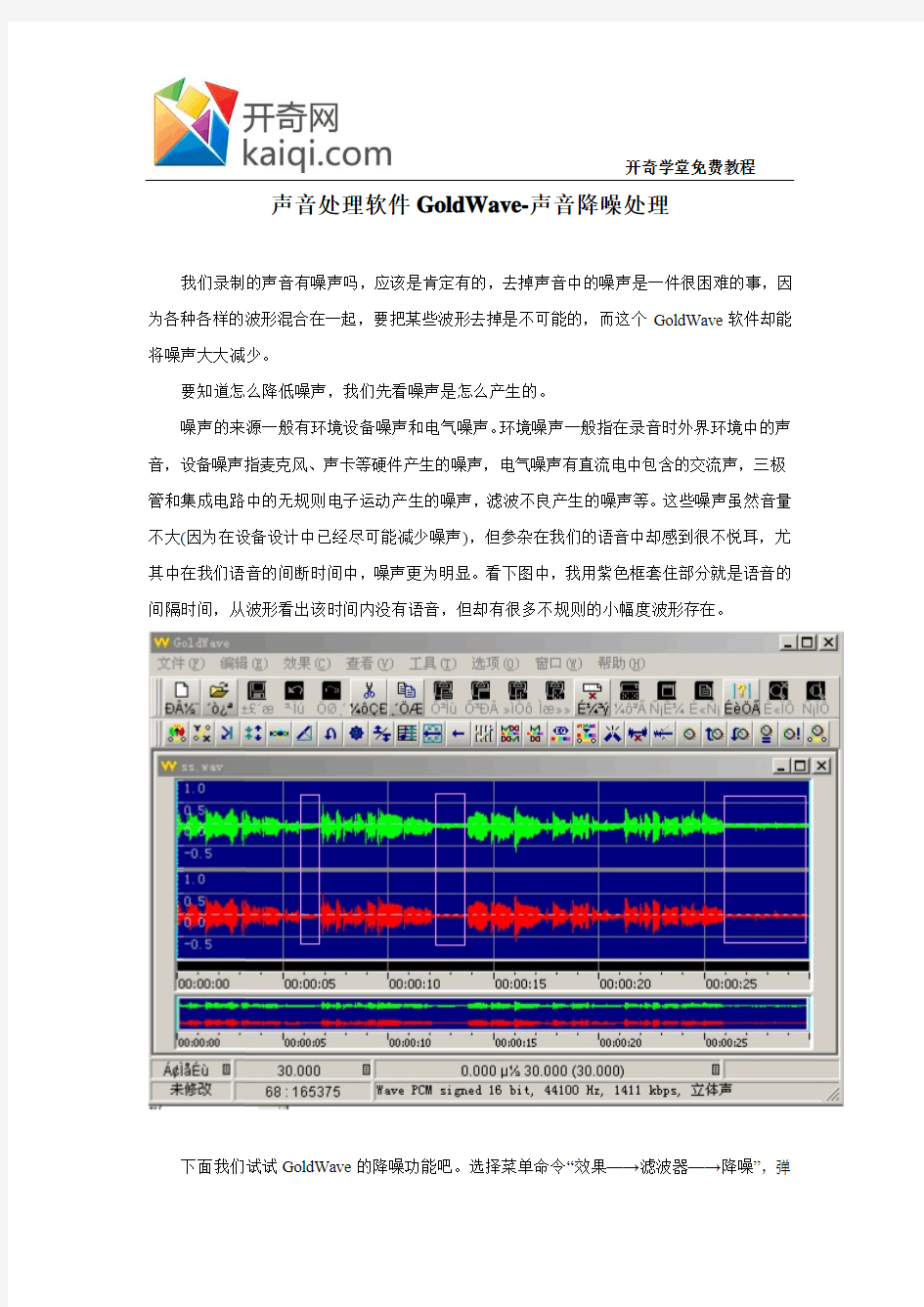
噪声的来源一般有环境设备噪声和电气噪声。环境噪声一般指在录音时外界环境中的声音,设备噪声指麦克风、声卡等硬件产生的噪声,电气噪声有直流电中包含的交流声,三极管和集成电路中的无规则电子运动产生的噪声,滤波不良产生的噪声等。这些噪声虽然音量不大(因为在设备设计中已经尽可能减少噪声),但参杂在我们的语音中却感到很不悦耳,尤其中在我们语音的间断时间中,噪声更为明显。看下图中,我用紫色框套住部分就是语音的间隔时间,从波形看出该时间内没有语音,但却有很多不规则的小幅度波形存在。
下面我们试试GoldWave的降噪功能吧。选择菜单命令“效果—→滤波器—→降噪”,弹
开奇学堂免费教程
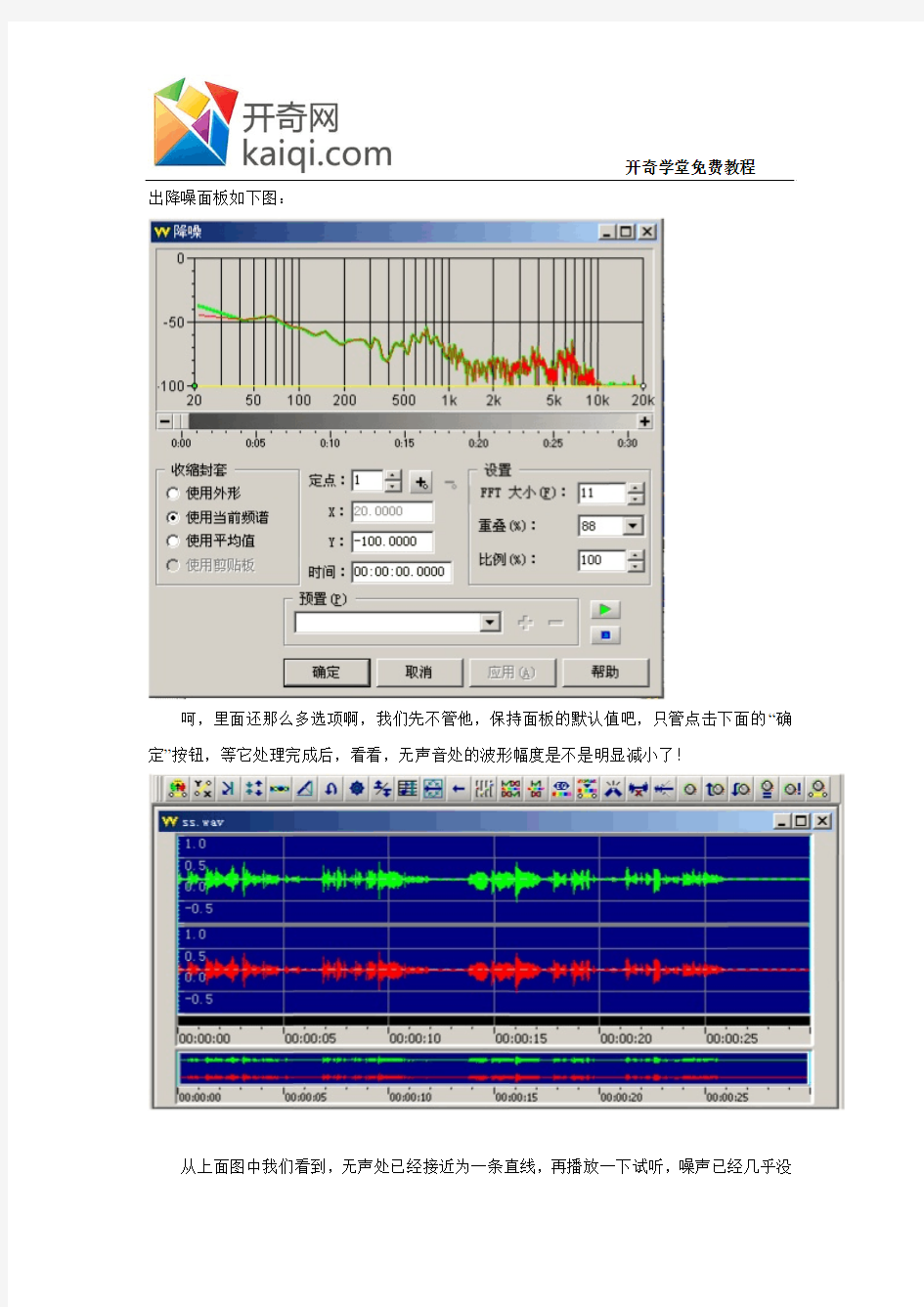
出降噪面板如下图:
呵,里面还那么多选项啊,我们先不管他,保持面板的默认值吧,只管点击下面的“确定”按钮,等它处理完成后,看看,无声音处的波形幅度是不是明显减小了!
从上面图中我们看到,无声处已经接近为一条直线,再播放一下试听,噪声已经几乎没
开奇学堂免费教程
有了,我们的语音好像没什么改变。
很神奇吧,这是软件编辑者分析了很多噪声的频谱设计顾取样标准,以后对照这些标准,从你的声音文件中把这类噪声消除。但毕竟产生的噪声千差万别,每个人的当前环境、使用设备、工件软件等都不相同,再高明的软件编辑者也不可能都掌握,于是,软件中还设计了另一种降噪算法,就是从你的环境中取出噪声样本,然后根据样本消噪。下面我们再试一下这种功能。
首先我们选取没有语音只有噪声的一段波形,如下图:
选取后点击播放试听一下,确认该段内没有语音内容,然后选择菜单命令“编辑—→复制”,这次复制可不是要粘贴到什么什么地方,只是用作“取样”的。
复制以后,还要全部选中整个文件的波形,然后选择菜单命令“效果—→滤波器—→降噪”打开降噪面板,如下图:
开奇学堂免费教程
在这个面板中,选择“使用剪贴板”项,再点击“确定”按钮,处理后再试听,是不是比上次的降噪效果更好了。为什么这次降噪效果更好呢,因为复制到剪贴板中这一段取出了你环境噪声作为样本,按照该样本消除你的文件中噪声,当然更符合实标。
从降噪面板图中我们看到,里面还有很多项设置,对于没有很深的音乐知识者来说,这些很难理解清楚,一般我们不用改变软件的默认值,只管让它按常规处理就可满足我们的要求了。
在“滤波器”菜单里还有“爆破音”“平滑滤波”等选项。在我们对减麦克风讲话时,有些字的声母发音时有突发式冲击波,造成急促的“爆破音”,在滤波器菜单下选择“爆破音/滴答声”,弹出面板中还按默认设置,点击“确定”按钮,即可使爆破音大大压缩。“平滑滤波”选项可使你的声音更加柔和圆滑,具体效果没法用语言说清楚,你自己试试就知道啦。这里面的功能要多实践才能掌握,反正试了后如果听着不理想,还可以再取消本次操作。如果你做了多次操作,已经不能再回到原来的状态了,那么你只要没有存盘,关闭该窗口并选择不保存就是了,原来的声音文件不会作任何改变。有时我们为了作试验,不想改变原来的声音文件,你在打开声音文件后,先在菜单中执行“另存为”命令,再起一个文件名保存,就可以任意修改编辑啦,修改编辑后如果很满意,可把原来的文件删除,如果修改的不满意,那就把
新存的文件删除,还保留原来的文件就是了。
如何录音+音频后期处理经验
『配音公社』[技巧交流]如何录音+音频后期处理经验(转载) 访问数:2148 回复数:23 楼主作者:Tassels发表日期:2010-3-25 11:14:24 感谢絮絮的共享。 ------------------------------- 以下内容为转载 ------------------------------- 这是本人多年来对音频后期处理的一些点滴经验,告诉大家同享,不对之处,请提出不同的见解,共同学习了。 AA3.0的前身是AA1.5,是一款功能齐全,占用资源少,界面清新,操作容易,支持机器配置不高的声卡,和SAM8.0录音编辑软件相比,有他的过人之处。那么如何用好这款录音软件呢?听我慢慢地跟你说: 录音前进行必要的设置: 1.是用几十元的家用麦克进行录音,要用反手键点选右下角的喇叭图标----打开音量控制----勾选麦克音量。 2.要是用上万元的调音台进行录音,要用反手键点选右下角的喇叭图标----打开音量控制----勾选线路输入音量。不然,在录音时会把伴奏的声音录进去的。直接录成混音,到时候你哭都没有办法的。 再在属性栏中点播放----要勾选线路音量,这时,伴奏的音乐通过耳机你就可以听到音乐了。 3.对机器特别低的电脑,为了让他更好地服务,点菜单中的编辑----录音音频设置----不勾选独占模式。(如果你有两块声卡,并且又没有屏闭的话。如果你已经屏闭了版载声卡,这项就不设置了。) 如何获取纯伴奏音乐: 一是在网上下载。一是在VCD,DVD的音视频光盘上截取,伴奏音乐多得不得了。最好是用纯音乐,省时省力。如果没有怎么办呢?就用AA3.0做噻,也就是人们说的消音,方法如下: 1.拿到原曲,听一遍。不是所有的曲子都适合消音的。可以先分辨下,那
Audition对音频的降噪处理(修改)
Audition对音频的降噪处理 第四军医大学教育技术中心夏仁康 【摘要】由于各种原因,录制的音频(无论语音还是歌唱)出现一定响度的噪声是经常发生的。当噪声太明显时就会影响听觉效果,降噪处理就是消除这种噪声的基本方法。文章阐述采用Audition 软件处理常见音频噪声的方法,简单实用,以飨读者。 【关键词】Audition;音频降噪; Audio Noise Reduction Process in Audition Abstract: Various reasons may cause noise during recorded audio files. The audio-visual effect is greatly affected if the noise dominates. Noise reduction is a process to eliminate the noise. This paper introduces a simple approach to reduce noise using software Audition. key words: Audition; Audio Noise Reduction 0.引言 电视节目除了画面就是音频,无论是电视剧、专题片、音乐节目还是用于教学的电视教材、多媒体教材,在制作时都涉及录制音频的问题,也不可避免地存在一定响度的噪声。如果这种噪声影响到主要声音的效果,就需要对其进行技术处理。大部分音频软件都可以处理噪声,这里笔者介绍通过Audition处理噪声的方法,操作方便,简单实用。 1.录音中噪声 从音响技术的角度上讲,凡属于传声器拾取来的或是信号传输过程中设备带来的对节目信号起干扰作用的(非节目中应有的)声音,都可以看成噪声[1]。可见,噪声的类型以及产生的原因非常多,从不同的角度和领域理解有不同的解释和不同的意义。这里涉及的“噪声”仅局限于语音录制过程中产生的噪声。噪声一般分为环境噪声和本底噪声。环境噪声主要指录音中自然环境产生的噪声。如室外的汽车、人声,室内墙壁的反射、机器设备发出的噪声等等;本底噪声是指除环境以外的噪声,一般指电声系统中除有用信号以外的总噪声,主要由录音过程中各种设备产生的规则或不规则的噪声,我们称之为本底噪声或背景噪声。分析起来,本底噪声一般包括低频和高频两种:(1)由于音频电缆屏蔽不良、设备接地不实等原因产生的“嗡嗡”交流声(50Hz~100Hz)称之为低频噪声;(2)由于放大器、调频广播和录音磁带产生的“咝咝”声(8kHz以上)称之为高频噪声或白噪声[2]。过强的本底噪声,不仅会使人烦躁,还淹没声音中较弱的细节部分,使声音的信噪比和动态范围减小,再现声音质量受到破坏[3]。 如何克服这些噪音是一个复杂而细致的过程,如环境的选择、布置,隔音的处理,话筒的选择,录音设备的选择、安装、调试、接地等等,在这里不作详细探讨,仅对已经录制好的、包含一定噪声的音频进行处理。 2.Audition软件特点 用于音频编辑的软件很多,而且一般的音频编辑和处理软件都可以对噪声进行处理。如德国著名的Steinberg公司出品的软件Cubase、Nuendo;德国MAGIX公司的Samplitude;美国Emagic公司的Logic Audio;美国Sonic Foundry公司的Vegas Audio、Sound Forge等等。Audition是美国Adobe向Syntrillium收购的Cool Edit Pro软件的核心技术,并将其改名为Adobe Audition,版本从1.0到目前的3.0,弥补了Adobe在音频编辑软件的空白。该版本界面友好,下载、安装、汉化方便简单,强大的功能不仅可以适合一般非专业人士使用,同样可以满足专业人士的需要。
录音人声处理步骤
录音人声处理步骤和方法 2009-05-05 22:31:28| 分类:音乐技术交流阅读1132 评论1 字号:大中小订阅 录音人声处理步骤和方法 母带处理软件IZotope.Ozone3臭氧教程 母带处理软件IZotope.Ozone3臭氧教程 软音源地址:https://www.sodocs.net/doc/513698532.html,本工作室开设:古典吉他考级和电吉他班编曲作曲电脑音乐制作班乐理辅导班等等 希望广大乐迷积极参与哦!{注:深圳吉他} 各位录音兄弟们好。现在是凌晨三点半。我从睡梦中醒来,给大家写这个教程。由于时间仓促,所以行文快速,有错漏的请各位高手们一一指出了。 后期处理即是母带处理。也就是录音混缩最后一个阶段的制作处理,做混音最后一步的调整和处理。母带处理不是件小事,绝对不能忽视,它甚至关系到整个作品给人的听觉上的感受。后期处理广义上指的是整个作品经过伴奏的录制、人声录制,人声效果混音、合成混缩后的再进行的环节。这是我对后期处理的理解,不知各位觉得是否贴切。许多兄弟位后期处理用恐龙(T-RACKS),哪个更好用,是仁者见仁、智者见智的,不过我还是对臭氧情有独钟。 Ozone3,江湖人称臭氧3。是一款运行在DX平台上的综合式音频效果插件,主要用于后期的母带处理。也就是最好用的后期处理软件。该插件界面超酷、功能强大、操作复杂、品质一流,目前最新版本为3.0.111版,由izotope公司开发。 OZONE3是个组合式的插件。包含有10段均衡器、混响器、电平标准化、高质量的采样精度转换、多段激励器、多段动态处理、多段立体声扩展、总输入/输出电平调节。比OZONE2多了好多新功能和算法。软件预置的方案比以往版本更丰富,有很大的实用和参考价值,并且还可以到https://www.sodocs.net/doc/513698532.html,下载许多新的预置参数。 我用臭氧的时间不长,不过细细研究了一番。发现它并没有像许多人说的那么难。对OZONE的六个效果器基分别解释: 1)均衡器 是个典型的参量式EQ,可任意定制频段数量、范围和频点。这是我用过的音质最好最精细的EQ。EQ也并没有有些人说得那么神话。如果只是做流行音乐的话,你只需要记得这些人声的频段就行了。 100hz 以下(必切,喷麦声,低频噪音频段) 200-500hz 人声低音(决定响度、力度、震撼度;鼻音重则衰减) 500-900hz 人声中音、乐音、泛音(决定温暖度、音色;音色坚硬则衰减) 900-2Khz 人声齿音、人声高频(决定穿透力,音色太刺则衰减) 4-10Khz 选择切除 臭氧3 EQ的使用快捷键: ←→左移/右移频段节点(每按一次) ↑↓增益/衰减0.1db(每按一次) Ctrl + ← 增加Q值(值越大,带宽越小) Ctrl + → 减少Q值(值越小,带宽越大) 我一般只用它来修补和突出某频段的人声,这是我的常用设置: 1.5K 提升 5.3db 增加明亮感 29hz 衰减-2.3db 减少轰隆声 69hz 衰减-0.9db 减少轰隆声 600){return this.width=600;}"> 2)混响器 母带加的混响不同于混缩时的混响。最重要的是不能破坏作品的清晰度、原有声相,并要合理地设置声场。要与混音时的混响相互配合。这是我混音的设置: 600){return this.width=600;}"> 与之相对应的后期混响,要适度了(也就是说要两次混响,混音时一次,后期时一次,所以混音时的混响要适度)。不要加了效果像唱K房的感觉,这是最失败的混响。做音乐不像唱K,可以猛加混响掩盖声线的缺陷。混响太多,会令人感到不亲切,不真实,不自然地。 600){return this.width=600;}"> 后期处理加的混响主要用来冲淡伴奏轨和人声轨的混响达到统一,令人声与伴奏融合得更和谐。所以添加一定要适度。界点为50hz和7khz,以保证混响不至于浑浊。 3)音量最大化 左边部分是最大化音量(电平标准化),这个很好理解,也可以说这部分是个母带处理的整体限制器。相信用过WAVES L2的朋友很容易上手的。比L2多了几个选项。要慢慢理解。
录制人声的一点窍门(一)
录制人声的一点窍门(一) 首先,我们要弄清楚一个问题,你做的是音乐还是歌?我的意思并不是说歌就不是音乐,我的意思是你要把歌和纯音乐分开,在歌里,人声是绝对的主导。所以,正确的处理歌里的人声在整个歌里占有了非常重要的地位。 现在,我们从准备工作入手,首先你得有一个像样一点的话筒,千万别相信别人说的一两百元的话筒就能录出专业的人声。那些卡拉ok话筒尤为明显,由于过分地夸大中频段、而且往往为了不出杂音把高频削掉了,这样的话筒当然录不出清晰的人声,好多朋友在单独用卡拉ok话筒录音的时候觉得人声还可以,但是做完整个音乐混缩的时候才发现人声含混不清,不管怎么弄都不好听,就是这个原因。同样的道理,有些人刚开始用akg这样的话筒的时候觉得很不习惯,认为噪音奇大,声音发尖,其实对于人声来讲,我认为清晰亮丽的高音频段非常重要,比如有一些流行歌曲本身混响较大,混缩时就非得再把高频提升一点,要不然混响不够,要不然含混不清,这就待后面再讲了。我的建议是录音时用耳机听回送,基本上听不到环境噪音和电流声就可以了,当然专业一点的话筒阻抗比较大,没有话放听起来可能吃力一点,所以最好弄个话放或者弄个大功率耳机。 好了,提归正转。现在开始录音! 现在做第一步工作,降噪。 有人说了,降噪我会啊,选取一段噪音波形为样本,然后再整体降噪呗,慢着,这个地方就容易出问题,首先你要听一下噪音属于哪一类?在人声里占到多大的比重。看这个噪音采样(图一),这是一段人声静音时的环境噪音在COOLEDIT里的噪音采样。(有关具体步骤请参阅胡戈和张俊在 https://www.sodocs.net/doc/513698532.html,上的有关文章,在此不详述)这段频谱的噪音量实际上已经非常小,而且主要是非常高频的电流声,这样的噪音是可以通过上述方法解决的,但是如果噪音的量比较大,而且参杂了许多中高频的环境噪音的话,我建议你不要用这个方法,因为这样会吃掉你的声音,还会让人声产生吭吭巴巴的现象。所以我建议这个方法要慎用,而且采样的时候尽量采最小最平直的一部分噪音。如果降噪完毕在人声中间还有噪音啊、喘气声啊,我建议你直接把那一部分静音,这样尽管人声里还有一点噪音,但是被人声掩盖,人声间歇时又是静音,整个人声就会听起来比较干净。说一千道一万最
声音处理软件 GoldWave-声音降噪处理
开奇学堂免费教程声音处理软件GoldWave-声音降噪处理 我们录制的声音有噪声吗,应该是肯定有的,去掉声音中的噪声是一件很困难的事,因为各种各样的波形混合在一起,要把某些波形去掉是不可能的,而这个GoldWave软件却能将噪声大大减少。 要知道怎么降低噪声,我们先看噪声是怎么产生的。 噪声的来源一般有环境设备噪声和电气噪声。环境噪声一般指在录音时外界环境中的声音,设备噪声指麦克风、声卡等硬件产生的噪声,电气噪声有直流电中包含的交流声,三极管和集成电路中的无规则电子运动产生的噪声,滤波不良产生的噪声等。这些噪声虽然音量不大(因为在设备设计中已经尽可能减少噪声),但参杂在我们的语音中却感到很不悦耳,尤其中在我们语音的间断时间中,噪声更为明显。看下图中,我用紫色框套住部分就是语音的间隔时间,从波形看出该时间内没有语音,但却有很多不规则的小幅度波形存在。 下面我们试试GoldWave的降噪功能吧。选择菜单命令“效果—→滤波器—→降噪”,弹
开奇学堂免费教程 出降噪面板如下图: 呵,里面还那么多选项啊,我们先不管他,保持面板的默认值吧,只管点击下面的“确定”按钮,等它处理完成后,看看,无声音处的波形幅度是不是明显减小了! 从上面图中我们看到,无声处已经接近为一条直线,再播放一下试听,噪声已经几乎没
开奇学堂免费教程 有了,我们的语音好像没什么改变。 很神奇吧,这是软件编辑者分析了很多噪声的频谱设计顾取样标准,以后对照这些标准,从你的声音文件中把这类噪声消除。但毕竟产生的噪声千差万别,每个人的当前环境、使用设备、工件软件等都不相同,再高明的软件编辑者也不可能都掌握,于是,软件中还设计了另一种降噪算法,就是从你的环境中取出噪声样本,然后根据样本消噪。下面我们再试一下这种功能。 首先我们选取没有语音只有噪声的一段波形,如下图: 选取后点击播放试听一下,确认该段内没有语音内容,然后选择菜单命令“编辑—→复制”,这次复制可不是要粘贴到什么什么地方,只是用作“取样”的。 复制以后,还要全部选中整个文件的波形,然后选择菜单命令“效果—→滤波器—→降噪”打开降噪面板,如下图:
如何提升人声处理技巧
如何提升人声处理技巧 1. 用一轨人声做Double(叠合) 你想要叠合人声部分,于是就在多条轨道上重复录制了人声,想要从里面选出较好的部分来建立两条人声。不幸的是,某一乐句只有一次录音是出色的——另一个可能有瑕疵,或歌手在录音时爆音了。这时候不要着急:把出色的部分拷贝到另一轨上,对音调进行微调,然后设置20到25ms的延迟就可以了。 2. 细调混响的扩散(Diffusion) 好的人声当然需要好的混响,那么试试低扩散(“密度”)的参数。这样做的原因是:扩散控制着回声的“厚度”。高扩散把回声放置得很近,而低扩散把它们摆得很远。对于节奏性的声音,低扩散会制造很多密集空间的声音,像石头撞在钢铁上一样。但是对于人声,低扩散能给你足够的混响效果,但不会引起太多反射。 3. 细调混响衰减时间 很多混响都提供了频率的交叉点,高频和低频各自带有单独的衰减时间。为了防止与中频乐器过多的竞争,可以在低频的地方使用低的衰
减时间,在高频的地方使用高的衰减时间,这样可以给人声增加“空气感”,同时也能加强唇齿音,让人声更加生动。最后调整交叉点的位置,让人声达到较好的效果。 4. 声像自动化(Automation) 对于Double的人声,你可以把两者都放在中间,或者一个靠左,一个靠右,然后添加不同的效果。比如,在声场里有背景人声,我通常会把它放在中间。如果不想人声比乐器突出,我会把两个轨道放得开一点,不使之成为焦点。简单来说:用自动化来控制声像,对于不同的部分使用不同的声像。 5. 令人竖起汗毛的人声 记得Pink Floyd曾经用的那种轻声的,令人竖起汗毛的人声吗?试着让人声尽量多一些语气,像说话,而不是唱歌,然后插入一个声码器(软件或硬件),以人声作为调制器,粉噪作为载体。你可能不需要太多粉噪的高频。把它和人声混合在一起——就足够增加一些轻声的,令人竖起汗毛的元素了。同样,试着加入一些节奏性的延迟,把音量调到合适的位置。 6. 选择性地使用回声
音频降噪Matlab仿真
数字信号处理大作业
班级:1401012_ 姓名:齐翔奡_ 学号:14010120082
输入信号的时域波形及其功率谱密度: 叠加噪声后的音频信号的时域图形及功率谱密度:
经过带通滤波器的音频信号的时域和功率谱密度:
程序解读: clc; clear all; close all; [wav,fs]=audioread('GDGvoice8000.wav'); t_end=1/fs *length(wav); % 计算声音的时间长度 Fs=50000; % 仿真系统采样率 t=1/Fs:1/Fs:t_end; % 仿真系统采样时间点 % 利用插值函数将音频信号的采样率提升为Fs=50KHz
wav=interp1([1/fs:1/fs:t_end],wav,t,'spline'); % 设计300Hz~3400Hz的带通预滤波器H(z) [fenzi,fenmu]=butter(6,[300 3400]/(Fs/2)); nt = wgn(1,length(t),0.1); % 噪声 nt=nt/(max(abs(nt))); %归一化噪声 wav_noise = wav + nt; % 对音频信号进行滤波 wav_after = filter(fenzi,fenmu,wav_noise); figure(1); subplot(2,1,1); plot(wav(53550:53750)); title('语音信号时域波形'); axis([0 200 -0.3 0.3]); subplot(2,1,2); psd(wav, 10000, Fs); title('语音信号功率谱密度'); axis([0 25000 -20 10]); figure(2); subplot(2,1,1); plot(wav_noise(53550:53750)); title('加噪声后的语音信号时域波形'); axis([0 200 -0.3 0.3]);
录音去杂音技巧分享(降噪)文档
录音去杂音技巧分享(降噪) 配音系统开测啦!各位未来的声优SAMA在录音的同时是不是也有噪音带来的困扰呢?什么?你有录音棚?你有防爆音罩?你个土豪!去去去~ 我买不起那么专业的东西啦……就算买得起没有地方放啦!那么……咳!言归正传,我给大家推荐一点平民化的去噪音录音放法。 推荐使用软件 AA(Adobe Audition)录制然后上传音频,直接在网页上录制的声音是无法去除噪音的(除非有专业的环境与设备做到零噪音),而且录制效果相比软件也明显不同(具体表现为网页录音音量偏大,杂音与爆音多)。 如图为我使用的版本(很久没更新过,不过功能还是算齐全的),
在正确插入耳机与话筒后打开软件,点击菜单中的编辑→音频硬件设置进入设置界面,将编辑查看与多轨查看中的默认输入与默认输出调节正确(根据声卡的不同设置也不同,我的耳机自带声卡设置,所以显示USB,一般未接通额外音频设备的电脑会显示声卡设置即立体声混音,或者Realtek High Definition Audio,如果你装了realtek的驱动就会显示这个),一般情况下(单声卡无外接设备),AA会自动识别输入输出端口,耳机话筒插上就可以直接录音了,所以设置这一步多数人可以跳过。
你可以选择在单轨(编辑模式)或多轨模式下配音,单轨模式直接点击下方录音按钮即可开始,多轨录音需要点下录音音轨上的R键并保存会话(AA的工程文件)才可以开始录音。 下面进入正题,降噪。 背景噪音是录音很常见的问题,尤其在夏天,蝉噪、车鸣、风扇、空调,以及声卡自带的电音都是噪音的来源,我们要做的就是在录音的时候留出空白区供给AA软件做背景噪音采样。
一般人声处理的顺序及相关插件
在这里我按照使用次序来介绍一下一个我平常用的效果器 一般人声处理的次序: [降噪] → [激励] →均衡→[去齿音] →压限→混响里的代表视情况添加 1.降噪 对于降噪我的看法是可以不降则不降 因为多少会对音质有损失 但如果噪音很严重就没办法了 推荐使用Audition自带的采样降噪器 首先你得录制一段空白的声音文件,也就是你不发声,单单录制你的环境噪音 然后点Effects - Noise Reduction - Noise Reduction FFT SIZE 可设为8192 SNAPSHOTS IN PROFILE 越大越好我以前一般设成 32000 然后点Capture Profile Noise Reduction Level 根据你自己的需求改越高噪音消得越多
音质损失越大 2. 激励 一般动圈话筒比较需要激励 电容话筒的话一般不需要除非你需要声音带有强烈金属色彩推荐使用的效果器: BBE效果器{臭氧里的也OK} 使用时请适量添加 3. 均衡 如果不是清唱的话均衡是相当重要的 推荐荐效果器: Ultrafunk Fx Equalizer 或者 Wave Q10 怎样均衡每人的习惯都不同 我的做法是把100HZ以下的人声切掉以免和伴奏的鼓声撞到有必要的话可以将高频稍作提升原则是可以的不动的就尽量不动 100--250Hz:增加正面感 250--800Hz:浑浊不清的区域 1--6kHz:增加临场感 6--8kHz:增加丝丝声和透明度 8--12kHz:增加亮度
4.消齿音(嘶声削除) 如果话筒灵敏度高频响范围大 而且你非常喜欢对高频做提升那消齿音是很必要的 否则你所发出的 Z C S 会很伤风景 推荐效果器: DeEsser 如果是用Nuendo/ Cubase的话 自带效果里的 Dynamics就有一般情况只要选择male/female 即可 如果是Audition需要另外装插件 Wave 3.0以上版本就有DeEsser效果器 5. 压限 压限之所以要放在均衡后面是为了防止过载 推荐效果器: Wave C4 或者 Ultrafunk Fx / Wave Compresser 用WAVE的话选择预置的pop vocal / vocal即可 用Compresser的话可选择预置的Vocal/ Vocal Soft 6. 混响 推荐效果器:TC Native Reverb 或者 Ultrafunk Fx Reverb 参数设置好后我觉得效果上没多大差别
matlab音频降噪课程设计报告.doc
燕山大学 医学软件课程设计说明书 题目:基于MATLAB巴特沃斯滤波器的音频去噪的GUI设计 学院(系):电气工程学院 年级专业: 13级生物医学工程 2 班 学号: 130103040041 学生姓名:魏鑫 指导教师:许全盛
目录 一、设计目的意义 (1) 1.1绪论 (1) 1.2设计目的 (1) 1.3意义 (1) 二、设计内容 (2) 2.1 设计原理 (2) 2.2 设计内容 (2) 三、设计过程及结果分析 (3) 3.1 设计步骤 (3) 3.2 MATLAB程序及结果 (3) 3.3 结果分析 (8) 四、总结 (9) 五、参考文献 (10)
一、设计目的意义 1.1 绪论 语音是语言的声学表现,是人类交流信息最自然、最有效、最方便的手段。随着社会文化的进步和科学技术的发展,人类开始进入了信息化时代,用现代手段研究语音处理技术,使人们能更加有效地产生、传输、存储、和获取语音信息,这对于促进社会的发展具有十分重要的意义,因此,语音信号处理正越来越受到人们的关注和广泛的研究。 1.2 设计目的 (1)掌握数字信号处理的基本概念,基本理论和基本方法。 (2)熟悉离散信号和系统的时域特性。 (3)掌握序列快速傅里叶变换方法。 (4)学会MATLAB的使用,掌握MATLAB的程序设计方法。 (5)掌握利用MATLAB对语音信号进行频谱分析。 (6)掌握滤波器的网络结构。 (7)掌握MATLAB设计IIR、FIR数字滤波器的方法和对信号进行滤波的方法。 1.3 意义 语音信号处理是一门比较实用的电子工程的专业课程,语音是人类获取信息的重要来源和利用信息的重要手段。通过语言相互传递信息是人类最重要的基本功能之一。语言是人类特有的功能,它是创造和记载几千年人类文明史的根本手段,没有语言就没有今天的人类文明。语音是语言的声学表现,是相互传递信息的最重要的手段,是人类最重要、最有效、最常用和最方便的交换信息的形式。 语音信号处理是研究用数字信号处理技术对语音信号进行处理的一门学科,它是一门新兴的学科,同时又是综合性的多学科领域和涉及面很广的交叉学科。
基于matlab谱减法音频降噪处理
题目基于matlab谱减法音频降噪处理 班级 学号 姓名 指导 时间 景德镇陶瓷学院
数字信号处理课程设计任务书
目录 1、设计要求. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1 2、设计原理. . . . . . . ……………………………………………….. . . . . . . . . . . .2 3、源程序清单. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7 4、设计结果和仿真波形. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11 5、参考文献. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15. 6、设计心得体会. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1、设计要求 语言是人类最重要、直接、有效和便捷的交换信息的方式。随着近些年科学技术的飞速发展,人们也不满足于和计算机的信息交换方式,希望能够甩掉键盘和鼠标而实现用语言来对计算机进行控制。因此,语音信号处理技术便应运而生。语音信号处理是一门新兴的学科,同时也是综合多种学科和涉及面非常广泛的交叉学科。现在在一些职能系统中嵌入有语音处理系统,但它们只能在安静的环境中才能使用。然而,在语音信息的采集过程中难免会有各种噪声的干扰。噪声不仅降低了语音的可懂度和语音质量,还严重的影响语音处理的准确性,甚至使系统不能正常工作。本文将就对语音增强技术的原理和方法进行讨论,重点介绍语音增强的一种方法——谱减法及其改进算法。该方法能够有效消除平稳的加性噪声,其改进算法能够有效消除普通方法产生的“音乐噪声”,在很大程度上提高语音信号的信噪比。 目前,语言识别技术已经取得了重大进展,并开始进入实用阶段。但语音识别系统必须在相对比较安静的环境下运行,然而,在语言信息的采集中难免会有各种噪声的干扰,在较强的噪声背景下,语音识别系统的准确性会受到较大影响,甚至没法正常工作。所以在语音识别系统对语音信息处理前,应该对语音信息进行预处理,即背景噪声消除。语音背景噪声消除技术的出现使得语音识别技术更加稳定和精确,也使得语音信息的可懂度大大提高,使人们能够从较复杂的语音信息中提取到更多的有用信息。
音频处理的一些技巧
一、正常对话两个人的音量大小在-15到-6之间会很河蟹 二、场景切换时间长度不要少于3秒,不然会感觉很赶。 三、淡入淡出时间长度不要少于2秒,不然会完全没感觉。 四、声音层次的分布:人声> 音效> BGM > 环境音效。 五、人物脚步声除非特定,不要多于4秒,不然会很拖节奏。 首先说一下:波形振幅处理 1、波形振幅—动态处理: 这个是一个用来做音量的动态处理的一般来说很少用到。。因为它用起来不如C4那么直观。 2、波形振幅--渐变: 渐变里面有很多的预制项,大多数时候我们只需要用到正常的预制就好了 前面6个10 3 6DB CUT或则是BOOST就是音量波形减小或则增大。 CENTE WAVE 就是调整直流偏移。。就是调波形中线的东西 FADE IN和FADE OUT就是淡入淡出,这个记得你要先选一段,不然直接处理就变全干音淡入或则淡出了。也可以通过调整那个-240的数值做出声音慢慢接近或则慢慢走远的效果。 然后是4个PAN开头的,意思是第一个,左边没声音,第二个,声音从左到右,第三个,声音从右到左,第四个,右边没声音。。这四个带耳机做一次就会听的很明显。 接下来4个和上面四个差不多,第一个是右声道淡入,第二个是右边衰减3,第三个是左声道淡入,第四个是左边衰减3。我们可用2 和4做出声音偏左或偏右的感觉!调整那个-3DB 数值可以让感觉更偏或更中间。 3、波形振幅--空间回旋: 就是立体声回旋啦,自己试听下就明白了 4、波形振幅--强硬限制: 这是一个限幅器,就是用来限制增幅强度的。类似音量标准化,不过不同的地方在于这个是增加是加法。而音量标准化是乘法即按比例放大。 5、波形振幅—声道重混缩: 这个就是混缩左右波形的让它重新生成的一个东西,比如说有一些干音左边大右边小,我们就声道重混缩一下,它就一样了。这个还有一个用处就是做伴奏带,消人声里面的VOCAL CUT 就是了。 6、波形振幅—声相/声场: 就是声音位置处理和加强立体声感觉的一个东西,试着做1、2下就明白了,大多数时候用不到。 7、波形振幅—音量包络:
人声录音及处理
人声录音及处理 1、对男歌手的音色频率调节男声基音频率在64-523Hz左右,泛音可扩展到7-9kHz。要求男歌手的声音要坚实,音色要有力度,但又不至于造成模糊不清。 1、对男歌手的音色频率调节 男声基音频率在64-523Hz左右,泛音可扩展到7-9kHz。 要求男歌手的声音要坚实,音色要有力度,但又不至于造成模糊不清。因此,对男歌手音色频率调节要求在4个频率段进行处理,根据男声的泛音结构,依频谱曲线为据,对男歌手在4个频率段进行加工处理的手法是: (1)对64-100Hz做小的提升,其目的是为了增加一些浑厚感,也是男低音的音域; (2)在250-330Hz做大的提升,因为男声基音的主要频率在这个区域,提升此频段可增加基音的力度; (3)对1kHz左右频段做小的提升,这样可保证泛音的频率表现,增加音色的明亮度,这个频段可延续至3-8KHz;
(4)10kHz以上频段可做平直处理。 2、对女歌手的音色频率调节 女声基音频率在160Hz-1.2kHz左右,泛音可扩展到9-10kHz。因此,要使女声得到较佳音色表现,应在4个频率上进行处理,女声音色表现为圆润、清晰、明亮。 女声歌手的4个频率加工处理的手法是: (1)160Hz以上,频率低于女声音域,做不提升处理; (2)250-523Hz音区是女声主要音域,做提升处理,以增加基音的力度和丰满度,是女声的低中音区; (3)对1-3kHz频段进行提升,其目的是为了使音色结构的泛音表现出良好的频率导通特性,使音色更加出色,同时可增加音色的明亮度; (4)10kHz以上频率给予小的提升,目的是为了使音色的色彩有足够的表现力,可对音色微小,细腻的部分加以表现。 3、对鼻音严重的音色处理 鼻音产生的原因有2个:一是生理上的原因,生理机体有缺陷;二是发声方法或者训练方法不正确,而造成鼻间共鸣过强。 改善鼻音严重和方法应在四频段均衡器上进行频率处理, (1)对64-100Hz频段进行大的衰减,以消除鼻音严重频带;
人声均衡调节的技巧
从严格的定义上讲,人声部分是一首“声乐歌曲”的焦点。不过,要想将人声缩混得十分出色,使它的音色富有穿透力可不是件容易的事尤其是当使用大量的电子音乐作背景的时候。 所以,这里给大家列举一些有关均衡器的提示和技巧,以便大家提高人声的缩混质量。首先,一定要记住这个“进来什么样”/“出去什么样”的定律:这是得到满意的人声和满意的录音的前提条件。我这里不是想教育你的歌手,也不想唠唠叨叨地希望他或她把烟和酒还有其它什么不良习惯都统统戒掉,也不想讨论话筒和话筒前级功放的选购常识,或者是压缩、混响或延迟效果器的使用技巧。我要谈的,就是均衡器。 超越性能极限 如果你不是刻意追求一种极端少见的人声效果,类似完全压扁的人声、极度尖锐/低音技术的声音,或着是那种长途电话里的声音的话,那么恰如其分地使用均衡器能够极大地增强你音乐的表现力。我的偏好是基本上关掉125到240Hz附近的推子,将2.5到3.5kHz的推子拉下少许以衰减部分dB,这样就可以除去那些十分尖锐的频率,而10到15或16kHz的频段范围则要提升,以便强烈地突出旋律。 所有那些常见的、不定因素(歌手、麦克风等等)将最终决定你应该使用什么样的均衡器,不过作为开始,这是应该掌握的基本原理。目前的趋势是那种清脆的主音音色,高音清澈透明,低音也很好但不冒尖。主唱与乐队的混音应当保持恰当的比例, 一开始,我使用高通滤波器将部分低音关掉。有些话筒和大多数的调音台都内置这种滤波器。常用的这些频段范围根据硬件的设计或生产厂家的不同,衰减的频段范围也有所不同(例如:每八度关掉6dB,100周波以下),一般都是从60Hz到200Hz左右。 运用这样的滤波方式可以使贝司的低音部分从声乐轨分离出来,使它适应它的自己恰当的频响范围,这样也不会和其它伴奏乐器发生频段上的冲突。它还有助于弱化一些破裂音(爆响的扑声以及其它一些辅音),使其不是那么明显。一个好的滤波器应当会将它们全部过滤掉。当然,大多数的人声通常都不会在160左右周波以下有什么作为,所以,将这一部分切掉并不会造成太大的损失。 其次,在大约125到240Hz的频段范围衰减4到6个dB,是为了使人声从底鼓/贝司/大桶鼓的音响区域中脱离出来。要知道,一下切掉得太多的话可能会导致人声特别地单薄,所以应该循序渐进,每次一点一点地剪切。此外,即便是在同一首歌曲当中,剪切的频段范围和剪切的多少还应依据歌手的不同而因地制宜。在有些缩混中,主音轨就是一种完全平直的人声,或者只是在录入时加了少量的均衡。不过有时候,一首曲子本身可能会出现很大的变化,歌手可能会在几个小节之内突然降低或提升一个八度的音高,这就要求增加均衡器来与乐曲其它声部相匹配。 根据所使用的设备,有许多办法可以可以实时进行均衡器调节。如果用的是模拟调音台,通常的办法是将人声轨分叉到两个调音台的通道上,每个的均衡器设置不同(经常音量推子也有所不同)。然后,你只要根据需要将一个音轨静音,同时开启另一个音轨,或将它们交叉渐变即可完成。 如果调音台的通道不够用了,也可以使用外接的均衡器来进行交替设置,同样也能起到同样
话筒的选择和人声的处理技巧
话筒的选择和人声的处理技巧 歌曲的演唱有不同的风格,不同的要求,也有不同的演唱技巧,所以也就要求音响效果把不同风格的各种类型的演唱都完美地表现出来。美声歌曲是体现音色优美;民族歌曲是体现民族风味和地方色彩;通俗歌曲是体现深沉的情感;而摇滚歌曲则是体现强劲的激情。由于歌曲的风格有所不同,其音响处理的要求也就不同。 话筒的选择 1 、美声歌曲演唱话筒的选择 演唱美声歌曲时应该选用频率响应范围很宽的电容式话筒,安装在高话架上,进行远距离的拾音。在艺术舞台上演唱,话筒与口型的距离一般在20 -60cm 之间。在大奖赛演唱中,话筒与口型的距离一般为60 -80cm . 其高度在人脸与口型以上,这样可以将脸露出画面。这种远距离拾音有一定的混响反射声进入话筒,使音色变得混厚、自然、有弹性和空间感。之所以选用电容式话筒拾音,是因为电容式话筒的频率响应范围宽,神经质高频上限可达18-20kHz 。因为美声发声方法音色优美,它的泛音数量多,高频泛音频率很高,高音乐音的高频泛音可达10-20kHz 。所以,需要用电容式话筒进行拾音。因为这种话筒可以将歌声中所有的高频泛音的成分全部拾入话筒,并转换成音频信号。由于电容式话筒的灵敏度比较高,所以不可以用手持方式使用话筒。如果话筒离口型太近,会造成话筒过荷失真现象。有些音响素质不高或缺乏音响知识的歌手常常不理解这个道理,一味追求口型离话筒过近,因而造成响度虽然很大,但失真度也变大,使凌晨色变得很差。 2 、民族歌曲演唱话筒的选择 民族歌曲的范围比较大,有些歌曲近似于美声风格,也有些歌曲近似于通俗歌曲的风格,所以其话筒的选择也各有所不同。在艺术舞台上演了民族歌曲时,也应选用电容式话筒进行拾音。但是,口型与话筒的距离要比美声歌曲演唱近一些,一般为20 -400cm , 且略低于口型位置。在歌舞厅演唱时可使用手持式动圈式话筒进行演唱。 3 、通俗歌曲演唱话筒的选择 演唱通俗歌曲时应选用手持近讲动圈式低灵敏度话筒,因为通俗歌曲是以深沉的情感为主要特点,所以应采用近讲、近距离拾音方式。这样就缩短了歌声音源与听音者的距离。从聆听心理学角度上讲,就会产生一种亲切感。 用话筒与口型很近的拾音方法拾取的是完全的真达声,虽然感情亲近了,但是音色却变得很干涩,这就必须进行混响(REV )或者是回声(EVHO )的加工处理。处理以后才会使音色变得丰满、混厚;否则,音色显得干瘪、单调、乏味。所以,演唱通俗歌曲的人声必须要经过混响或者回效果处理,才会使歌声变得悠扬、深沉、混厚、感人。
基于matlab谱减法音频降噪处理
题目基于matlab谱减法音频降噪处理班级 学号 指导 时间 瓷学院
数字信号处理课程设计任务书
目录 1、设计要求. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1 2、设计原 理. . . . . . . ……………………………………………….. . . . . . . . . . . .2 3、源程序清 单. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7 4、设计结果和仿真波 形 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11 5、参考文献. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15. 6、设计心得体 会. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 6
1、设计要求 语言是人类最重要、直接、有效和便捷的交换信息的方式。随着近些年科学技术的飞速发展,人们也不满足于和计算机的信息交换方式,希望能够甩掉键盘和鼠标而实现用语言来对计算机进行控制。因此,语音信号处理技术便应运而生。语音信号处理是一门新兴的学科,同时也是综合多种学科和涉及面非常广泛的交叉学科。现在在一些职能系统中嵌入有语音处理系统,但它们只能在安静的环境中才能使用。然而,在语音信息的采集过程中难免会有各种噪声的干扰。噪声不仅降低了语音的可懂度和语音质量,还严重的影响语音处理的准确性,甚至使系统不能正常工作。本文将就对语音增强技术的原理和方法进行讨论,重点介绍语音增强的一种方法——谱减法及其改进算法。该方法能够有效消除平稳的加性噪声,其改进算法能够有效消除普通方法产生的“音乐噪声”,在很大程度上提高语音信号的信噪比。 目前,语言识别技术已经取得了重大进展,并开始进入实用阶段。但语音识别系统必须在相对比较安静的环境下运行,然而,在语言信息的采集中难免会有各种噪声的干扰,在较强的噪声背景下,语音识别系统的准确性会受到较大影响,甚至没常工作。所以在语音识别系统对语音信息处理前,应该对语音信息进行预处理,即背景噪声消除。语音背景噪声消除技术的出现使得语音识别技术更加稳定和精确,也使得语音信息的可懂度大大提高,使人们能够从较复杂的语音信息中提取到更多的有用信息。
cool edit 录音后人声处理效果器使用(绝对完美)
一.Delay延迟效果器。 延迟效果器能够在声音播放间隔一定时间后,再次播放同样的声音,以产生拖延和重复感。 它一般有以下几个参数: 1.干声输出(dry out): 是指原来的声音输出的音量大小。 2.延迟输出(delay out): 是指声音再次回放时的音量大小。 3.延迟时间(delay time): 是指原来的声音和回放时的声音之间的时间间隔。 4.衰减时间(decay time): 是指声音从原始声音后的第一次回声开始,回声的音量依次减弱,直到最后一次回声的完全消失所用的时间。时间越长重复回声的次数就越多,反之,越少。 二.Chorus合唱效果器。 合唱效果器是指在原来的声音基础上叠加一些由计算机产生的类似的声音样本,并和原乐器叠加,使单个乐器听起来象多个乐器一样,更有层次感。 合唱效果器一般有以下几个参数: 1.Input gain(输入增益): 用来控制输入音量的大小。输入增益越大,合唱的效果越明显;输入增益越小,合唱的效果越不明显。 2.Dry out (干声输出):
用来调节原来的声音输出的音量大小。最大调节可以保持原来声音的面貌。 3.Chorus out(合唱输出): 用来调节产生的合唱效果的音量大小。也就是调节在原来声音基础上产生的新的声音样本的音量大小。 4.Chorus size(合唱空间): 用来控制合唱空间的大小。空间越大,共鸣越强,合唱效果就越明显。 5.Feedback(声音反馈): 是用来调节产生声音的反馈长短。如果加大这个值,可以明显地听出原有干声基础上的合唱声音变长了。如果再加大这个值,就能听到明显的金属共鸣声。 6.Chorus out delay(合唱延迟时间): 是指基础声音播放后,再次播放产生的新声音所间隔的时间。通常在 0.1~100ms之间,超过50ms后,延迟听起来就非常明显了。 切记,不可把这个延迟时间做为延迟效果器使用,应严格控制。 7.Modulation rate(调制率)是指能够产生颤音效果的频率范围。 Modulation depth(调制深度)是指颤音的颤抖浓度,调制率和调制深度应同时应用,以达到更好的效果。 如果你想用一个人搞一个小合唱的话,或用一种乐器搞一个小合奏的话,不妨用用这个效果器。三.Distortion失真效果器。 失真效果器是指声音过载后,破坏了原来固有的属性,使声音形成一种嘶叫的、嘈杂的声效的效果器。有人问,它有什么作用呢?它的作用主要是用于电吉他的失真音色,热爱重金属的朋友千万不要错过。至于其他乐器,我们还是极力避免声音的失真的。
声音后期的入门教程(一)——降噪和切音部分(Adobe Audition)
声音后期的入门教程(一)——降噪和切音部分(Adobe Audition) By w4tcy(NPC) 在声音录制结束后我们是不能直接拿来用的。为什么呢?因为在录音的过程中我们肯定会在背景音中录进一些背景噪音,或者CV的一些NG片断(这是萌点啊!),并且有的时候CV 录制的每句话的时间间隔与COS剧、广播剧、BGM、中配是不一样的。如果是给翻唱做后期的话很有可能还会遇到调整音调、混响甚至是电音化这样的工作,而这些都需要后期去解决,这也是后期存在的意义。 首先介绍一下我们使用的软件Adobe Audition,现在我记得一般都是使用的AA3.0,在这里我还是使用老版的1.5,虽然可能在按键的构局上有一些变化,但是功能和使用方法还是一样的,功能也是一样的强大。 如上图就是AA1.5的界面,AA在各处均有下载,详情请咨询https://www.sodocs.net/doc/513698532.html, 总的来说后期一般是降噪——切音,如果有要求的话应该还有对时间轴、混响等工作,在这第一个教程中我先介绍降噪和切音这一部分。 总的来说,这个软件的使用方法还是很简单的,需要的就是熟练度……如果你们以后有幸面对几G的音源,你们会发现熟能生巧真的是一句震古铄今的名言。 一、降噪部分 闲话少叙 首先我们要导入音源
双击这个部分就会弹出导入的窗口 选择你想要修正的音源,打开就好了
然后还在左侧双击那个名字这个时候就可以对音源进行修音了 很抱歉……现在我电脑中只有一个我以前修过的音源…… 让我们通过滚轮将声音的前部分放大 这时候我们会看到在录制声音之前会有一段空白,而这个也是我们要求所有CV做到的,在录制声音之前空出一段空白来使背景噪音得到充分的录制,这样也会为后期提供方便,正常来说前面这一部分应该是和后面的一样有波形的……但是可惜这是我处理过的……所以木有了……OTL 但是在去噪之前我们还需要做一件事,就是标准化
相关文档
- 声音的降噪处理
- 基于matlab谱减法音频降噪处理
- 声音处理软件GoldWave
- 音频降噪Matlab仿真
- 基于matlab谱减法音频降噪处理..
- 音频降噪Matlab仿真
- 声音的降噪处理
- 音频降噪Matlab仿真
- 基于某matlab谱减法音频降噪处理
- 声音处理软件 GoldWave-声音降噪处理
- CoolEdit录音后期制作(一)降噪处理
- 音频处理细则
- Audition对音频的降噪处理(修改)
- matlab音频降噪课程设计报告.doc
- 基于matlab谱减法音频降噪处理
- 音频的采集与处理..
- 录音文件降噪方法
- 吸声降噪处理PPT讲稿
- Audition对音频的降噪处理
- 录音去杂音技巧分享(降噪)文档