Mysql Proxy 实现mysql读写分离
Mysql Proxy实现读写分离
Mysql Proxy介绍
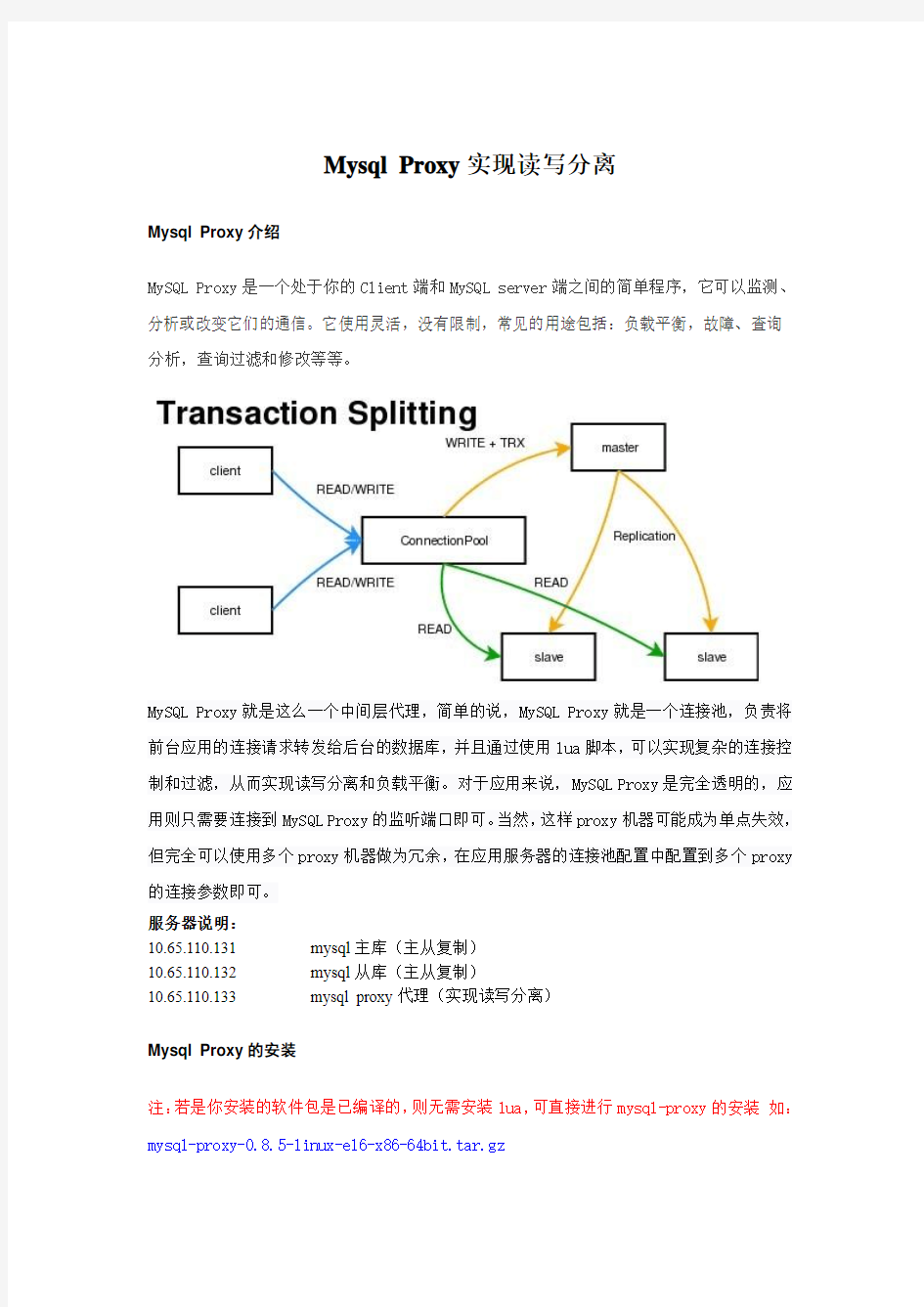
MySQL Proxy是一个处于你的Client端和MySQL server端之间的简单程序,它可以监测、分析或改变它们的通信。它使用灵活,没有限制,常见的用途包括:负载平衡,故障、查询分析,查询过滤和修改等等。
MySQL Proxy就是这么一个中间层代理,简单的说,MySQL Proxy就是一个连接池,负责将前台应用的连接请求转发给后台的数据库,并且通过使用lua脚本,可以实现复杂的连接控制和过滤,从而实现读写分离和负载平衡。对于应用来说,MySQL Proxy是完全透明的,应用则只需要连接到MySQL Proxy的监听端口即可。当然,这样proxy机器可能成为单点失效,但完全可以使用多个proxy机器做为冗余,在应用服务器的连接池配置中配置到多个proxy 的连接参数即可。
服务器说明:
10.65.110.131 mysql主库(主从复制)
10.65.110.132 mysql从库(主从复制)
10.65.110.133 mysql proxy代理(实现读写分离)
Mysql Proxy的安装
注:若是你安装的软件包是已编译的,则无需安装lua,可直接进行mysql-proxy的安装如:mysql-proxy-0.8.5-linux-el6-x86-64bit.tar.gz
安装lua(确定是否需要安装)
安装需要的基础组件,基本系统都可以满足lua的组件版本要求
yum -y install gcc* gcc-c++* autoconf* automake* zlib* libxml* ncurses-devel* libmc rypt* libtool* flex* pkgconfig*
对于本文安装的是预编译包,还需要编译包的支持。
Yum install libjpeg
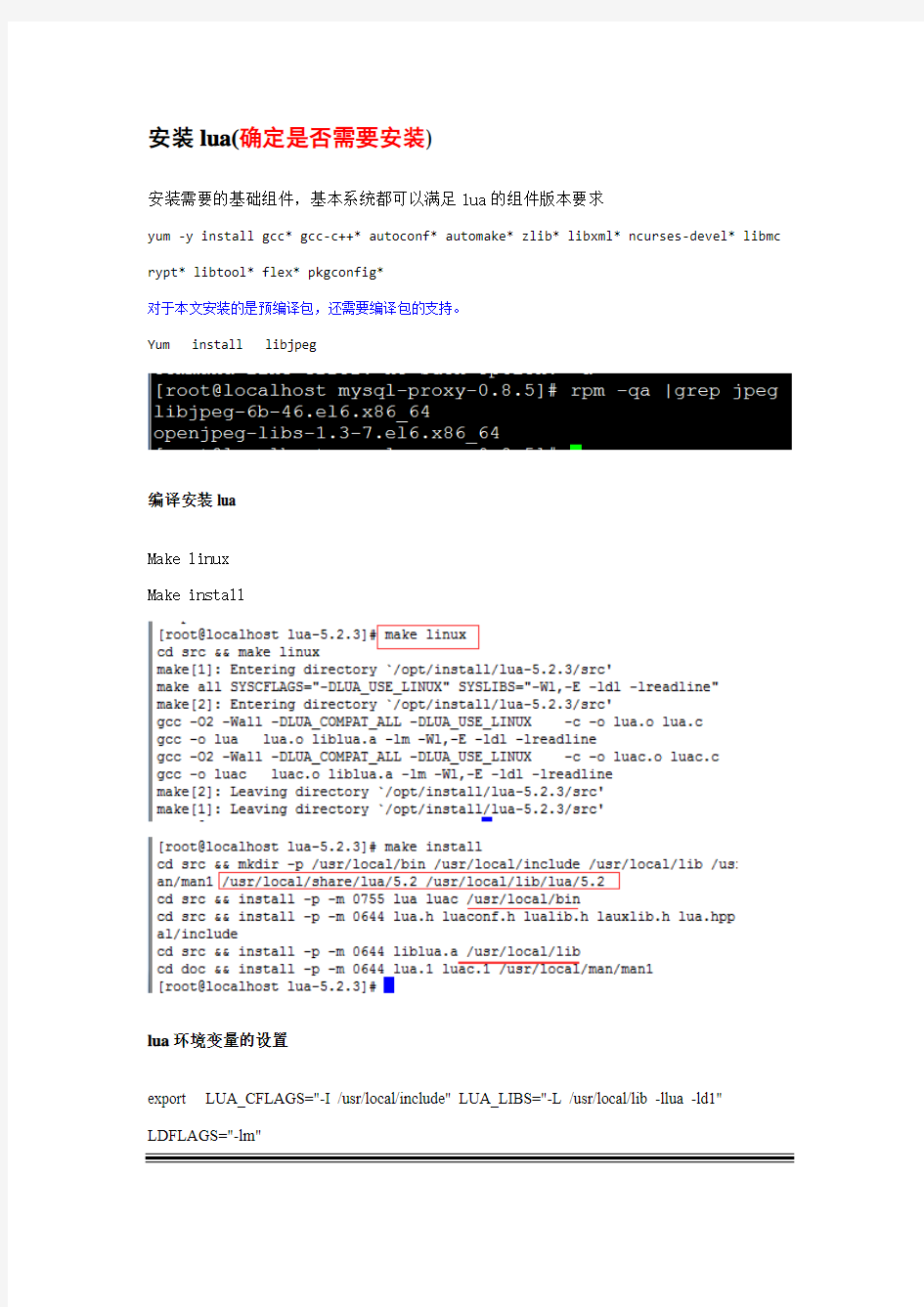
编译安装lua
Make linux
Make install
lua环境变量的设置
export LUA_CFLAGS="-I /usr/local/include" LUA_LIBS="-L /usr/local/lib -llua -ld1" LDFLAGS="-lm"
安装mysql proxy
系统内核版本:CentOS Linux release 6.0 x86_64
资源下载地址:
https://www.sodocs.net/doc/4f6088952.html,/downloads/mysql-proxy/mysql-proxy-0.8.5-linux-el6-x86-64bit.tar.gz
参考文档:https://www.sodocs.net/doc/4f6088952.html,/kcw/blog/317334
https://www.sodocs.net/doc/4f6088952.html,/e421083458/article/details/19697701
https://www.sodocs.net/doc/4f6088952.html,/thread-8775-1-1.html
注:因为下载的是已编译版本的软件包,所以,无需额外安装lua脚本软件。若安装的是预编译版本,则需要安装lua脚本软件,步骤如上。
解压安装
cd /opt/mysql-proxy
tar zxvf ~/Downloads/mysql-proxy-0.8.5-linux-el6-x86-64bit.tar.gz
mv mysql-proxy-0.8.5-linux-el6-x86-64bit/ mysql-proxy-0.8.5
设置mysql-proxy环境变量
export PATH=$PATH:/opt/mysql-proxy/mysql-proxy-0.8.5/bin
source /etc/profile 使变量立即生效
修改mysql proxy的读写分离脚本的配置
cd /opt/mysql-proxy/mysql-proxy-0.8.5/share/doc/mysql-proxy/
vim rw-splitting.lua
默认最小4个(最大8个)以上的客户端连接才会实现读写分离, 现改为最小2个最大5个,便于读写分离的测试
注:在读写分离测试时,需要开启多个窗口连接mysql-proxy
这是因为mysql-proxy会检测客户端连接, 当连接没有超过min_idle_connections预设值时, 不会进行读写分离, 即查询操作会发生到Master上.
开启防火墙端口设置
Iptables -I INPUT -p tcp --dport 4040 -j ACCEPT
注:mysql-proxy的服务端口默认为4040,可以在启动时,使用选项修改服务端口。
设置LUA_PATH变量
注:对于此变量也可不设置。可在mysql-proxy启动脚本中配置。
在/etc/profile中添加如下内容:
LUA_PATH="/opt/mysql-proxy/mysql-proxy-0.8.5/lib/mysql-proxy/lua/?.lua"
export LUA_PATH
Mysql-proxy -V 显示如下结果,显示mysql proxy的lua脚本路径
将admin.lua脚本与rw-splitting.ua脚本放在同一目录夹
注:rw-splitting.lua是mysql-proxy实现读写分离的脚本
复制lua管理脚本(admin.lua)到读写分离脚本(rw-splitting.lua)所在目录
先查找,再移动
find /opt/mysql-proxy/mysql-proxy-0.8.5 -name admin.lua
fd /opt/……/admin.lua
/opt/mysql-proxy/mysql-proxy-0.8.5/share/doc/mysql-proxy/
登录主库10.65.110.131,给主机10.65.110.133创建登录用户并赋权
grant all on *.* to 'mysql-proxy'@'10.65.110.133' identified by 'MYSQL-PROXY';
在test数据库下创建1_tb表用于读写分离测试
登录从库10.65.110.132,关闭从复制
Mysql-Proxy 命令简介
--help-all ————用于获取全部帮助信息
--proxy-address=host:port ————代理服务监听的地址和端口(缺省是4040)
--admin-address=host:port ————指定管理主机地址和端口(缺省是4041)
--proxy-backend-addresses=host:port ——后端mysql服务器的地址和端口(主服务器)
简写:-b
--proxy-read-only-backend-addresses=host:port ————后端只读mysql服务器的地址和端口(从服务器)简写:-r
--proxy-lua-script=file ————指定mysql代理功能的Lua脚本文件
--daemon ————以守护进程模式启动mysql-proxy
--defaults-file=/path/to/conf_file_name ————默认使用的配置文件路径
--log-file=/path/to/log_file_name ————日志文件名称
--log-level=level ————日志级别
--log-use-syslog ————基于syslog记录日志
--user=user_name ————运行mysql-proxy进程的用户
--admin-username=user ————指定登录到mysql-proxy管理界面的用户名
--admin-password=pass ————指定登录到mysql-proxy管理界面的用户密码
--admin-lua-script=script-file ————管理模块的lua脚本文件路径(创建管理接口)--defaults-file ————指定参数文件的路径
--plugins=admin ————加载管理插件
开关选项启动mysql-proxy
mysql-proxy --daemon --log-level=debug --log-file=/var/log/mysql-proxy.log --plugins=proxy -b 10.65.110.131:3306 -r 10.65.110.132:3306
--proxy-lua-script="/opt/mysql-proxy/mysql-proxy-0.8.5/share/doc/mysql-proxy/rw -splitting.lua" --plugins=admin --admin-username="admin"
--admin-password="admin"
--admin-lua-script="/opt/mysql-proxy/mysql-proxy-0.8.5/share/doc/mysql-proxy/ad min.lua"
监控启动日志
tail -f /var/log/mysql-proxy.log
测试mysql proxy读写分离
开启多个132远程窗口,连接mysql-proxy,向test数据库的1_tb表中插入数据
mysql -u mysql-proxy -h 10.65.110.133 -P 4040 -p
在只有一个客户端连接mysql-proxy时,操作是在Master上的。如下,在插入数据后查询数据是存在的。而当再次开启两个客户端连接后查询数据,新插入的数据未显示,因为是在slave上操作的。
开启新的连接,查看数据
登录slave库,查看test.1_tb表数据
登录Master库,查看test.1_tb表数据
以上可以发现数据显示结果不一样,说明mysql proxy的搭建完成。登录mysql-proxy后台管理
mysql -u admin -p admin -P 4041 -h 10.65.110.133
在无客户端连接mysql proxy时,后台服务器状态如下:
开启单连接mysql proxy ,服务器状态如下:
在开启多并发连接mysql proxy之后,查看后台服务器状态:
在开启多并发连接mysql-proxy时,查看端口有多条显示。
Mysql-proxy的启动方式
以配置文件的形式启动
编辑开关配置文件
vim https://www.sodocs.net/doc/4f6088952.html,f
指定配置开关文件启动mysql-proxy
改配置文件的权限为660
chmod 660 https://www.sodocs.net/doc/4f6088952.html,f
mysql-proxy --plugins=admin --plugins=proxy (加载插
件)--defaults-file=/opt/mysql-proxy/mysql-proxy-0.8.5/https://www.sodocs.net/doc/4f6088952.html,f
mysql-proxy --help-all 可以查看帮助选项。
将mysql-proxy加入系统启动项
添加mysql-proxy运行用户
groupadd mysql-proxy
useradd -g mysql-proxy mysql-proxy
chown mysql-proxy:mysql-proxy /opt/mysql-proxy/mysql-proxy-0.8.5 -R 注:注意配置文件和启动脚本的权限和所属问题,chown ……
参考文档:https://www.sodocs.net/doc/4f6088952.html,/thread-8775-1-1.html
编辑mysql-proxy配置文件
vim /etc/sysconfig/mysql-proxy
编辑mysql-proxy启动脚本
vim /etc/init.d/mysql-proxy
#!/bin/bash
#
# mysql-proxy This script starts and stops the mysql-proxy daemon
#
# chkconfig: - 78 30
# processname: mysql-proxy
# description: mysql-proxy is a proxy daemon for mysql
# Source function library.
. /etc/rc.d/init.d/functions
prog="/opt/mysql-proxy/mysql-proxy-0.8.5/bin/mysql-proxy"
# Source networking configuration.
if [ -f /etc/sysconfig/network ]; then
. /etc/sysconfig/network
fi
# Check that networking is up.
[ ${NETWORKING} = "no" ] && exit 0
# Set default mysql-proxy configuration.
ADMIN_USER="admin"
ADMIN_PASSWD="admin"
ADMIN_LUA_SCRIPT="/opt/mysql-proxy/mysql-proxy-0.8.5/share/doc/mysql-proxy/admi n.lua"
PROXY_OPTIONS="--daemon"
PROXY_PID=/var/run/mysql-proxy.pid (目录存放mysql-proxy对应实例运行的PID)PROXY_USER="mysql-proxy"
# Source mysql-proxy configuration.
if [ -f /etc/sysconfig/mysql-proxy ]; then
. /etc/sysconfig/mysql-proxy
fi
RETVAL=0
start() {
echo -n $"Starting $prog: "
daemon $prog $PROXY_OPTIONS --pid-file=$PROXY_PID
--proxy-address="$PROXY_ADDRESS" --user=$PROXY_USER
--admin-username="$ADMIN_USER" --admin-lua-script="$ADMIN_LUA_SCRIPT"
--admin-password="$ADMIN_PASSWORD"
RETVAL=$?
echo
if [ $RETVAL -eq 0 ]; then
touch /var/lock/subsys/mysql-proxy (判断是否有mysql-proxy实例运行的目录,mysql-proxy运行用户需要有这个目录夹创建文件的权限)
fi
}
stop() {
echo -n $"Stopping $prog: "
killproc -p $PROXY_PID -d 3 $prog
RETVAL=$?
echo
if [ $RETVAL -eq 0 ]; then
rm -f /var/lock/subsys/mysql-proxy
rm -f $PROXY_PID
fi
}
# See how we were called.
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
condrestart|try-restart)
if status -p $PROXY_PIDFILE $prog >&/dev/null; then stop
start
fi
;;
status)
status -p $PROXY_PID $prog
;;
*)
echo "Usage: $0
{start|stop|restart|reload|status|condrestart|try-restart}" RETVAL=1
;;
esac
exit $RETVAL
加入开机启动项
Chkconfig --add mysql-proxy
启动mysql-proxy
Service start mysql-proxy || /etc/init.d/mysql-proxy start
测试读写分离
后台服务器状态
132主机端登录mysql-proxy代理端插入数据
登录mysql-proxy代理端查询test数据库表1_tb
mysql -u mysql-proxy -p -h 10.65.110.133 -P 4040
查询131主库下test数据库1_tb表
mysql -u root -p
显示131和132主机上的连接
Proxy状态转移图
绿色线条是mysql proto的报文,蓝色的为proxy状态转移方向
参考文档:https://www.sodocs.net/doc/4f6088952.html,/wudongxu/article/details/7237831
配置amoeba实现读写分离
配置amoeba实现读写分离 配置环境: Mater :192.168.1.229 server1 读 Slave :192.168.1.181 server2 写 网站主机: 192.168.1.120 测试读写 一,配置mysql主从复制:请见另外一个文档。 二,配置jdk环境变量。 Amoeba框架是基于Java SE1.5开发的,建议使用Java SE 1.5版本。目前Amoeba 经验证在JavaTM SE 1.5和Java SE 1.6能正常运行,(可能包括其他未经验证的版本)。 变量设置(在master主机上配置),此处可以设置全局环境变量设置,也可使用root 用户变量设置,同样,如果是别的用户安装的amoeba软件,则使用相应的账号来设置jdk环境变量。 全局设置如下:加入下信息: vi /etc/profile JAVA_HOME=/usr/local/jdk1.6.0_25 PATH=$JAVA_HOME/bin:$PATH PATH=$PATH:$HOME/bin:/usr/local/amoeba/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME export PATH export CLASSPATH 解释如下:第一行指定了jdk的安装目录。 第二行指定了其家目录的路径。 第三行指定了amoeba的安装目录。 第四行指定了java相应的工具盒功能。 同样,如果是root用户的环境变量,则使用下面的位置的变量。 vi ~/.bash_profile 加入如上得到内容即可。 完成之后,执行命令 source ~/.bash_profile 或者source /etc/profile 使用如下的命令查看java手否被成功安装: [root@localhost ~]# java -version java version "1.6.0_25" Java(TM) SE Runtime Environment (build 1.6.0_25-b06) Java HotSpot(TM) Client VM (build 20.0-b11, mixed mode, sharing) 上述显示已经成功安装1.6版本。 附注jdk的下载地址: https://www.sodocs.net/doc/4f6088952.html,/technetwork/java/javase/downloads/jdk-6u32-downlo ads-1594644.html 三,Amoeba的安装(amoeba只需安装到一台主机上即可,默认情况下,是安装到主(master)服务器上,如果有第三台服务器,也可以将其安装到第三台服务器上。这样,减少了
数据架构规划
数据架构规划 一.当前架构 结合研发二部数据量最大的校讯通产品来描述,其他的产品在性能上出现瓶颈,可以向校讯通靠拢。 数据库整体架构:目前校讯通产品根据用户量的多少以及数据库服务资源的繁忙程度,横向采用了历史库+当前库的分库架构或者单一的当前库架构,其中历史库只作为web平台读数据库,纵向结合了applications的 memcache+Sybase ASE12.5传统永久磁盘化数据库架构。 数据模型架构:原则上采用了一事一地的数据模型(3NF范式),为了性能考虑,一些大数据量表适当的引用了数据冗余,根据业务再结合采用了当前表+历史表的数据模型。 以下就用图表来进行当前数据架构的说明: 横向分库数据库架构图:
纵向app layer+memcache layler+disk db layer图:
其中web层指的是客户端浏览器层,逻辑上:app层指的是应用服务层,mc 层指的是memcache的客户端层,ms层指的是memcache的服务层,db层指的是目前永久磁盘化的数据库层,当然在物理机器上可能app层跟mc层,ms层是重叠的部署在相同服务器上。 数据模型架构图:
其中以上数据模型中除了少数几张表外其他的都有历史表存在,当然有很多表是没在这个模型图中的,这部分是核心数据模型。这部分模型对象中也包括了一些冗余性的设计,比如用户中有真实姓名,特别是不在这个模型内,由模型核心表产生的一些统计报表,为了查询的性能冗余了合理一些学校名称,地区名称等方面的设计。 二.劣势现象 1.流水表性能瓶颈
当前架构的性能瓶颈集中在流水表的访问上,最大流水表的记录量达到了超5亿级别,这是由于目前外网在用的sybase数据库系统版本,没有采取很好的关于分区的技术。曾经有过把流水表进行物理水平分割,把不同月份的数据分割放在不同的物理表上的模型改造设想,碍于产生的应用程序修改工作量大,老旧数据迁移的麻烦,再加上进行了从单库架构改造到分库架构后,数据库性能瓶颈就不是特别突出。所以模型改造这部分工作没展开。 无论是单库或是分库的模式,出现平台访问数据库的性能瓶颈依然集中在大流水表上,在访问高峰高并发量情况下,短信的流水表进程堵塞,数据库服务 I/O ,CPU的资源耗费达到顶点,在服务器硬件环境不是特别理想情况下,出现了一定概率造成用户访问缓慢甚至觉得页面无法响应现象,造成了用户体念不良影响。 2. 运营维护难点 1)历史数据清理运维工作 为了存储充分利用,为了性能的提升,需要定期进行不再使用的历史数据清理, 由于清理的数据量庞大,传统的数据清理方法根本不可能保证一个晚上有效清理完毕,确保平台第二天正常的运行。虽然目前已经实行了比较高效且可行的数据清理方法,但是每次实行都需要晚上到通宵进行处理,使得数据清理的运维
数据库读写分离
随着一个网站的业务不断扩展,数据不断增加,数据库的压力也会越来越大,对数据库或者SQL的基本优化可能达不到最终的效果,我们可以采用读写分离的策略来改变现状。读写分离现在被大量应用于很多大型网站,这个技术也不足为奇了。ebay就做得非常好。ebay用的是oracle,听说是用Quest Share Plex 来实现主从复制数据。 读写分离简单的说是把对数据库读和写的操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力。主数据库提供写操作,从数据库提供读操作,其实在很多系统中,主要是读的操作。当主数据库进行写操作时,数据要同步到从的数据库,这样才能有效保证数据库完整性。Quest SharePlex就是比较牛的同步数据工具,听说比oracle本身的流复制还好,mysql也有自己的同步数据技术。mysql只要是通过二进制日志来复制数据。通过日志在从数据库重复主数据库的操作达到复制数据目的。这个复制比较好的就是通过异步方法,把数据同步到从数据库。 主数据库同步到从数据库后,从数据库一般由多台数据库组成这样才能达到减轻压力的目的。读的操作怎么样分配到从数据库上?应该根据服务器的压力把读的操作分配到服务器,而不是简单的随机分配。mysql提供了MySQL-Proxy实现读写分离操作。不过MySQL-Proxy 好像很久不更新了。oracle可以通过F5有效分配读从数据库的压力。
ebay的读写分离(网上找到就拿来用了) mysql的读写分离上面说的数据库同步复制,都是在从同一种数据库中,如果我要把oracle的数据同步到mysql中,其实要实现这种方案的理由很简单,mysql免费,oracle太贵。好像Quest SharePlex也实现不了改功能吧。好像现在市面还没有这个工具吧。那样应该怎么实现数据同步?其实我们可以考虑自己开发一套同步数据组件,通过消息,实现异步复制数据。其实这个实现起来要考虑很多
MYSQL开发规范
MySQL DB规范
目录 简介 (3) 目的 (3) 适用范围 (3) 数据库设计 (3) 引擎及版本选择 (3) 基础规范 (3) 命名规范 (5) 库表设计规范 (5) 字段设计 (6) 常用数据类型: (6) 数据类型使用建议: (6) 索引规范 (8) 索引准则 (8) 索引禁忌 (8) 不使用外键 (9) SQL设计 (10)
简介 介绍在使用mysql中各种注意事项和优化细节 目的 供开发人员参考,合理利用MySQL特性,开发出更高效的代码减少后端数据库压力,让整个系统高效稳定运行适用范围 业务数据库使用的是MySQL的数据库。 数据库设计 实现目标:业务功能实现、数据的扩展性、普遍性适用性 业务中80%+的性能优化是来自架构设计的优化 引擎及版本选择 根据业务特性选择合适的存储引擎,默认选择InnoDB存储引擎,原因如下(MyISAM与InnoDB比较): 基础规范 所有库表默认使用INNODB存储引擎,MyISAM适用场景非常少
●库表字符集使用UTF8,原因如下: 使用utf8字符集,如果是汉字,占3个字节,但ASCII码字符还是1个字节;统一不会有转换产生乱码风险;其他地区的用户(美国、印度、台湾)无需安装简体中文支持,就能正常看您的文字,并且不会出现乱码。 UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。 UTF-8的编码规则很简单,只有二条: 1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。 2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。 ●所有表和字段都需要添加注释,以方便其它开发及dba了解 ●单表数据量纯int型建议控制在1000w以内,含char型的建议500w以内,行平均长度控制在16KB以内, 单表20GB以内 ●不在数据库中存储图片、文件等大数据.原因如下: 1、对数据库的读写速度永远赶不上文件系统的处理速度 2、数据库备份会变的很臃肿,备份很耗时间 3、对文件的访问需要通过你的应用和数据库 ●临时短命数据尽量不要存到数据库中,建议存放于前端的memcache、redis等nosql中,减少后端数据库压 力 ●禁止在线上做压力测试 ●禁止从测试、开发环境直接连接线上数据库 ●用数据库来持久化存储以及保证事务一致性,不是运算器,在应用层实现计算 ●读写分离,主库只写和少量实时读取请求,使用从库来查询。 ●采用队列方式合并多次写请求,持续写入避免瞬间压力 ●超长text/blob进行垂直拆分,并先行压缩 ●冷热数据进行水平拆分(如6个月前后数据),LRU原则 ●快速更新频繁和大数据表禁止直接运行count(*)统计 ●压力分散,在线表和归档表(日志表)分开存储;不重要的非实时查询日志不要存数据库,以文件方式 在应用端统计分析。 ●禁止明文存储机密数据,需至少两次加密(部分数据可逆运算)
数据库读写分离解决方案--DG实施方案
数据库读写分离解决方案 ----oracle 11G ADG实施方案
1.项目背景介绍 1.1目的 通过DG实现主库与备库同步,主库作为业务应用库,备库作为查询库,应用根据不同需求配置对应数据库; 1.2测试环境 在2台RedHat5.4上使用ORACLE 的DataGuard组件实现容灾。设备配置(VMWare虚拟机环境)清单如下:
2.Oracle DataGuard 介绍 备用数据库(standby database)是ORACLE 推出的一种高可用性(HIGH AVAILABLE)数据库方案,在主节点与备用节点间通过日志同步来保证数据的同步,备用节点作为主节点的备份,可以实现快速切换与灾难性恢复。 ●STANDBY DATABASE的类型: 有两种类型的STANDBY:物理STANDBY和逻辑STANDBY 两种类型的工作原理可通过如下图来说明: physical standby提供与主数据库完全一样的拷贝(块到块),数据库SCHEMA,包括索引都是一样的。它是可以直接应用REDO实现同步的。 l ogical standby则不是这样,在logical standby中,逻辑信息是相同的,但物理组织和数据结构可以不同,它和主库保持同步的方法是将接收的REDO转换成SQL语句,然后在STANDBY上执行SQL语句。逻辑STANDBY除灾难恢复外还有其它用途,比如用于用户进行查询和报表,但其数据库用户相关对象均需要有主键。 ?本次实施将选择物理STANDBY(physical standby)方式
●对主库的保护模式可以有以下三种模式: –Maximum protection (最高保护) –Maximum availability (最高可用性) –Maximum performance (最高性能) ?基于项目应用的特征及需求,本项目比较适合采用Maximum availability (最 高可用性)模式实施。
网站MySQL数据库优化方案-主从架构及读写分离
网站MySQL数据库优化方案 网络运维信息管理中心 (2020年8月)
数据库为网站提供数据的结构化存储,是网站系统的重要组成部分,但随着业务逻辑的复杂度的增加,数据库需要不断的优化,单一的数据库已无法满足现在要求。 1.1优化目标 针对网站的MySQL数据库部署架构进行优化,其优化的目的是为了防止数据库出现单点故障问题,提高数据库的处理能力,提高数据库的可靠性,为保证网站业务正常办理。 1.2优化工作思路 1、对现有数据库现状分析包括现有数据库配置合理性分析、现有数据库部署情况两部分工作内容; 2、梳理现有网站的功能模块,目的是通过梳理网站的各功能模块对数据读取时效性,分析其是否可以实现读写; 3、以数据库主从架构及数据库读写分离方式,对网站的MySQL 数据库提出数据库部署架构优化的方案,数据库主从架构的多数据库模式,解决数据库单点存在的问题,当主数据库出现宕机时,可以将从数据库代替主数据库恢复业务系统正常运行,而且避免数据的丢失,提高数据库高可靠性和高可用性;通过部分查询统计功能,实现数据库读写分离,以便对数据库负载进行分流,缓解主数据库的读取压力。
2.1当前数据库部署架构图 当前网站的数据库采用单台MySQL数据库提供数据库服务,当前部署架构图如下: 2.2现有数据库主要配置梳理
2.3数据库部署情况梳理 2.3.1数据库安装部署情况梳理 2.3.2现有应用连接数据库情况梳理 连接数据库的应用系统有会员管理、权限管理、订单模块、商品管理、促销管理、广告管理、报表统计、文章管理、评论管理、系统设置、数据库管理、短信管理、推荐管理、邮件群发管理等。2.3.3数据库服务启动、停止方式梳理 1、启动命令 (1)普通启动:/data/soa/mysql/bin/mysqld (2)centos6以前版本:service start mysqld (3)centos7+:systemctl mysqld start
Mycat MySQLGalera读写分离验证安装手册
Mycat+MySQL Galera读写分离验证作者菜菜-李梦嘉56335443 部署MySQL Galera 安装环境 安装前准备 安装gcc、gcc-c++ # yum install gcc gcc-c++ 安装boost-devel # yum install boost-devel 安装scons check-devel openssl-devel # yum install scons check-devel openssl-devel 安装libaio # yum install libaio 安装perl、perl-devel # yum install perl perl-devel 安装rsync、lsof # yum install rsync lsof MySQL Galera安装 安装含wsrep Patch的MySQL # tar zxvf mysql-wsrep-5.6.27-25.12-linux-x86_64.tar.gz # mv mysql-wsrep-5.6.27-25.12-linux-x86_64 /usr/local/mysql
# groupadd mysql # useradd -r -g mysql mysql # chown -R mysql:mysql . # ./scripts/mysql_install_db --no-defaults --datadir=/usr/local/mysql/data --user=mysql # chown -R root . # chown -R mysql data # ln -s /usr/local/mysql/bin/* /usr/sbin 安装Galera复制插件 # tar zxvf galera-3-25.3.13.tar.gz # cd galera-3-25.3.13 # scons # cp garb/garbd /usr/local/mysql/bin/ # cp libgalera_smm.so /usr/local/mysql/lib/plugin/ 配置MySQL Galera # cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld # mkdir -p /var/lib/mysql # chown mysql:mysql /var/lib/mysql # vi /etc/https://www.sodocs.net/doc/4f6088952.html,f [client] port = 3306 socket = /var/lib/mysql/mysql.sock [mysqld_safe] log-error = /var/lib/mysql/mysql.log pid-file = /var/lib/mysql/mysql.pid [mysqld] wsrep_node_name = node1 wsrep_provider = /usr/local/mysql/lib/plugin/libgalera_smm.so #wsrep_provider_options ='gcache.size=1G;socket.ssl_key=my_key;socket.ssl_cert=my_cert' #wsrep_slave_threads=16 wsrep_sst_method = rsync
数据库使用情况分析
数据库使用情况分析 一、警报日志: 1)计算一个月插入数据 目前操作为15S会执行一次数据库操作;假设有2000台;那么;一个月的数据为: 单枪柜: 4*60*24*30=240 0000 如果为2000台: 240*2000=40000W 这是极限值; 2)计算数据库插入频率 按时间权限处理算下数据库插入操作频率: 15S/2000 =7ms执行一次插入操作 3)数据查询 数据库的数据要与其他的表用ID做关联,那么这个操作会更糟糕;因为警报日志表中在7ms就会执行一个插入动作,所以关联的查询如果在7ms中检索不出来,检索的数据就会有脏数据;(检索和插入动作产生冲突,数据库在处理检索和插入的同时还会处理他们的冲突事情) 由上可以看出数据库的性能要远远高于7ms才可以 以上为单张表警报日志处理极限值分析; 以上解决方法: 1)插入执行时间加长到1个小时,相当于执行极限频率提高到7ms*60*4=5s 2)分库,把此单张表移到一个单独数据库中; 3)换中型数据库MSSQL 或大型数据库ORACLE; 二、取枪还枪日志极限值分析 1)枪弹柜取枪与还枪动插入操作 枪弹柜取枪与还枪动作限定每天执行一支枪一个动作;每个枪弹柜只有十支枪,子弹不用取还计算; 一个枪弹柜一天执行的动作数: 1*10=10次;
按2000枪弹柜计算: 一个月执行的次数为: 10*2000*30=30 0000数据; 取还枪表一个月的数据要有30W数据存在;一年大约为400W数据分为两张表,单张表一年数据也近200W; 2)取还枪执行频率 最坏计算: 所有取枪人员在上班同一时间(一小时)取枪计算执行频率为 1*60*60/20000=0.06S 按上述频率计算,数据库的性能至少是执行每个动作不超过0.06s 就不会产生冲突;(数据不会丢或不会出错),但一般数据库中表关联查询(多表查询)都差不止要这个时间;所以产生冲突的可能必会很大;数据库一定要可以处理这种冲突; 三、整个数据库计算 如果计算最坏情况下数据库的使用频率 应该是: 一个60ms执行一次一个7ms执行一次;最坏计算是420ms产生一次冲突(取还枪与警报日志);也就是一秒内会有至少产生两次冲突的可能; 而单独警报日志自身不同动作(插入、删除)是0.007S产生一次冲突,数据库会可能会产生一次冲突; 四、解决方案 1)优化数据库和程序代码; 缺点:对程序员和数据库优化人员的技术要求高; 优点:数据库可以继续使用目前数据库 2)数据分库、数据库读写分离; 缺点:程序需要修改 优点:动作很容易实现 3)换大型数据库(MSSQL 或ORACLE); 缺点:可能需要收费(如果我们项目可以使用破解版本,就可以不用担心), 优点:直接把结构COPY即可;对程序员和数据库优化人员要求低; 4)如果换库建议使用破解版本ORACLE或MSSQL;
mysql读写分离
Linux下Mysql源码安装笔记 安装步骤: 1.解压mysql-5.1.55.tar.gz 命令: tar -zxvf mysql-5.1.55.tar.gz 2.配置Mysql 命令:./configure --prefix=/usr/local/mysql 说明:安装到/usr/local/mysql下,当然用别的也行,还有其它参数可以查看相关文档. 3.编译,安装 命令: make make install 这两个命令发的时间较长. 4.创建用户和组. groupadd mysql useradd -g mysql mysql 5.进入mysql目录.创建var目录.并把./share/Mysql/https://www.sodocs.net/doc/4f6088952.html,f 拷到Mysql目录下并改名为https://www.sodocs.net/doc/4f6088952.html,f. >mkdir var >mv share/mysql/https://www.sodocs.net/doc/4f6088952.html,f https://www.sodocs.net/doc/4f6088952.html,f 6.配置https://www.sodocs.net/doc/4f6088952.html,f 配置主要把安装的目录的那几项打开就行. 7.安装数据库 命令:./bin/Mysql_install_db 说明:必须用参数--defaults-file指定https://www.sodocs.net/doc/4f6088952.html,f,否则系统用默认的/etc/https://www.sodocs.net/doc/4f6088952.html,f.
8.安装完后,可以看到mysql/var目录下有数据文件,然后用下面命令设置权限: shell> chown -R root . shell> chown -R mysql var shell> chgrp -R mysql . 9.启动数据库. ./bin/Mysqld_safe 10.进入数据库. ./bin/mysql -u root – 默认时没有密码,当然如果你删除/etc/https://www.sodocs.net/doc/4f6088952.html,f,可以不要后面的--defaults-file=/test/Mysql/https://www.sodocs.net/doc/4f6088952.html,f ./bin/Mysql -u root --socket=/tmp/Mysql3306 也就行了,原因大家应该知道吧!^_^! 11.设为服务并自启动. 对于设置为服务只要把mysql/share/mysql/mysql.server放到/etc/init.d/下改名为mysql 命令: mv share/mysql/mysql.server /etc/init.d/mysql chmod 775 /etc/init.d/mysql chkconfig --add mysql 总结,这只是安装了一个3306端口的mysql,如果要在装一个msyql,步骤一样,只要改动https://www.sodocs.net/doc/4f6088952.html,f文件的内容. 设置用户权限: grant all privileges on *.* to 'root'@'%' identified by 'ZJLT&https://www.sodocs.net/doc/4f6088952.html,' with grant opt ion; 备: server-id = 2 master-host=192.168.1.14 replicate-do-db=appmarket master-user=root master-password=ZJLT&https://www.sodocs.net/doc/4f6088952.html,
上海Linux运维工程师-面习题-练习-个人总结)
这下面的是一个企业发的面试题 1你常上的相关技术站有哪些? 2简述你所理解运维工程师的主要职责? 3你管理过的服务器数量级? 1台 2台 2-5台 5-10台 10台以上 4描述一次你印象深刻的服务器运维经历。 5有一台服务器出现安全问题,你会采取什么样的方法处理?说出你的诊断处理思路。 6有多台服务器需部署相同应用文件,文件会持续更新,你用什么方式实现不同服务器间的文件同步。 7某一台服务器部署多个Web站点,其中有一个w3wp的CPU占用达到100%,如何找出有问题的Web站点? 8你眼中的沪江是怎样的?谈谈你对沪江的理解。 9是否有以下相关经验?如有请简要说明掌握情况。 a、Squid相关经验 b、Nginx、Lighttpd等 c、Memcached d、负载均衡 e、分布式文件处理 f、Email Server 上午-10点雷傲普文化传播有限公司 1.DNS使用的端口号和协议,简单描述一下DNS正向解析和反向解析的工作原理和作用还 有应用场景? 2.编写IPTABLES使用内网某台机器的80端口可以在公网访问,假设公网IP为10.10.1.1 ,实现192.168.1.0/32段的NAT. 3.举出三个以上的主流WEB服务器,并简述他们的特性和优缺点不限操作系统? Apache 源代码开放可以欲行在unix,windowns,linux平台上,可移植性,而且模块很是丰富缺点:性能,速度上不及其他轻量级的web服务器,但是也是重量级产品,所消耗的内存,cpu也比其他的要高 Nginx 源代码开放发高性能的http和反向代理服务器,在高并发的情况下,nginx 是apache不错的替代品,他能够支持高达50000个并发连接响应,内存,cpu等系统资源消耗也是很低的。缺点,支持模块比较少吧,相对没有apache稳定,支持动态页面
数据库规范
数据库相关规范 1.使用utf8mb4字符集 2.所有表、字段必须写清中文注释 3.金额字段禁止使用小数存储(单位:分) 4.禁止使用字段属性隐式转换(如:“WHERE ms_no = 1234”ms_no为字符串类型) 5.尽量不使用负向查询(NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等) 6.禁止使用外键,如有完整性约束,需要应用程序控制 7.禁止使用程序配置文件内的账号访问线上数据库 8.禁止非DBA对线上数据库进行写操作 9.开发、测试、线上环境分离 10.所以提交的SQL语句必须经过测试 11.禁止存储大文件或大照片 12.库名、表名、字段名:小写,下划线分割,不超过32个字符,必须见名知意,禁止拼 音英文混用 13.表必须有主键 14.必须把字段定义为NOT NULL并设置默认值 15.必须使用varchar(20)来存储手机号 16.单表索引控制在5个以内,单索引字段数不许超过5个 a)索引的使用。? b)(1) 尽量避免对索引列进行计算。如计算较多,请提请管理员建立函数索引。? c)(2) 尽量注意比较值与索引列数据类型的一致性。? d)(3) 对于复合索引,SQL语句必须使用主索引列? e)(4) 索引中,尽量避免使用NULL。? f)(5) 对于索引的比较,尽量避免使用NOT=(!=)? g)(6) 查询列和排序列与索引列次序保持一致 (7) 禁止在更新频繁、区分度不高(如:性别)的字段上建立索引 (8) 建立组合索引,必须把区分度高的字段放在前面 17.禁止使用SELECT * ,只获取必要的字段 18.禁止使用INSERT INTO t_xxx VALUES(xxx),必须指定插入的列名 19.禁止在WHERE条件的属性上使用函数或表达式 20.禁止%开头的模糊查询 21.禁止使用OR条件 22.应用程序必须捕获SQL异常,并作出相应处理 23.逻辑删除代替物理删除 24.选择最有效的表名、查询条件顺序(从右到左) 25.减少访问数据库的次数 26.SQL中的关键字均使用大写字母,数据表最好起别名 27.查询条件中“>=”代替“>” 28.等号两边使用空格,逗号后使用空格 29.多表操作必须使用别名 30.整条语句必须写明注释,关键逻辑单独书写注释,说明算法、功能 a)注释风格:注释单独成行、放在语句前面。? b)(1) 应对不易理解的分支条件表达式加注释;? c)(2) 对重要的计算应说明其功能;?
数据库读写分离方案及对比
数据库读写分离方案及对比版本日期修改历史作者
目录 1概述 (3) 2背景 (3) 3数据库读写分离方案 (3) 3.1Oracle数据库几种常用的复制技术及特点 (3) 3.2异构数据库(Oracle+Mysql)+ GoldenGate (3) 3.2.1方案描述 (3) 3.2.2实现原理 (4) 3.3异构数据库(Oracle+Mysql)+ 其他复制技术 (6) 3.4同构数据库(Oracle)+ GoldenGate (6) 3.4.1方案描述 (6) 3.4.2实现原理 (7) 3.5同构数据库(Oracle)+ DataGuard (7) 3.6同构数据库(SqlServer2008 企业版) (7) 3.6.1实现原理 (8) 3.7同构数据库(Mysql5社区版) (8) 4方案对比 (9)
1概述 本文主要是描述SVC(统一客户视图)项目的数据库读写分离的几种解决方案及优缺点对比。2背景 为了能进一步提升SVC业务系统的服务质量水平、运行效率、系统健壮性稳定性及运行安全,信息中心提出了对SVC的架构进行调整升级,以满足目前及未来的建设需求。 为了缓解大并发的情况下对数据库造成的压力,方案中引入了缓存及数据库的读写分离的技术解决问题。这里针对数据库的读写分离方案有几种实现方式,这里主要是描述这几种方案,以及这几种方案的对比,最后根据具体的情况选择最适合的方案。 由于是比较重要的业务系统,数据量及访问量都比较大,数据的存储主要考虑Oracle、DB2、SQLServer等知名商业数据库厂商。考虑到实现的技术复杂度及运维难度这里主要推荐Oracle作为存储数据库。 3数据库读写分离方案 这里初步提议的数据库有两种,Oracle 11g与Mysql 5。 3.1O racle数据库几种常用的复制技术及特点 3.2异构数据库(Oracle+Mysql)+ GoldenGate 3.2.1方案描述 该方案使用的是异构数据库,其中主数据为Oracle双机热备,从数据库使用的是多台Mysql。主数据库可进行读写操作,主要是进行写操作,从数据库只能读操作。下面是该方案的逻辑架构图:
数据共享集群和读写分离集群的服务名配置
数据共享集群和读写分离集群的服务名配置 DMDSC Dameng Data Shared Clusters,达梦数据共享集群。 DMRWC Dameng Read/Write Clusters,达梦读写分离集群。 1. DMDSC在生产环境中用的越来越多,就有应用配置连接字符串的问题,首先需配置dm_svc.conf(类似于Oracle的tnsnames.ora),如下: time_zone=(480) language=(en) dmrac=(192.168.0.1:5236,192.168.0.2:5236) switch_time=(10000) switch_interval=(1000) loadBalance=(true) loadBalanceFreq=(10000) loadBalancePercent=(10) dmrac: 服务名,配置DSC节点的IP和端口。 loadBalance : 是否负载均衡 loadBalanceFreq: 负载均衡的频率 然后需要配置的URL字符串: url="jdbc:dm://dmrac:5236?comOra=true&loadBalance=true&loadBalanceF req=10000" comOra: 是否兼容ORACLE模式 & :转义字符,转义为& 2. 读写分离集群(DMRWC)服务名配置: TIME_ZONE=(480) LANGUAGE=(en) DM_RWW=(192.168.0.151:5236,192.168.0.152:5236,192.168.0.153:5236) RW_SEPARATE=(1) RW_PERCENT=(30) LOGIN_PRIMARY=(1) SWITCH_TIME=6000
读写分离----构建报表和查询系统
数据库读写分离 随着一个网站的业务不断扩展,数据不断增加,数据库的压力也会越来越大,对数据库或者SQL的基本优化可能达不到最终的效果,我们可以采用读写分离的策略来改变现状。读写分离现在被大量应用于很多大型网站,这个技术也不足为奇了。ebay就做得非常好。ebay用的是oracle,听说是用Quest Share Plex 来实现主从复制数据。 读写分离简单的说是把对数据库读和写的操作分开对应不同的数据库 服务器,这样能有效地减轻数据库压力,也能减轻io压力。主数据库提供写操作,从数据库提供读操作,其实在很多系统中,主要是读的操作。当主数据库进行写操作时,数据要同步到从的数据库,这样才能有效保证数据库完整性。Quest SharePlex就是比较牛的同步数据工具,听说比oracle本身的流复制还好,mysql也有自己的同步数据技术。mysql只要是通过二进制日志来复制数据。通过日志在从数据库重复主数据库的操作达到复制数据目的。这个复制比较好的就是通过异步方法,把数据同步到从数据库。 主数据库同步到从数据库后,从数据库一般由多台数据库组成这样才能达到减轻压力的目的。读的操作怎么样分配到从数据库上?应该根据服务器的压力把读的操作分配到服务器,而不是简单的随机分配。mysql 提供了MySQL-Proxy实现读写分离操作。不过MySQL-Proxy好像很久不更新了。oracle可以通过F5有效分配读从数据库的压力。
ebay的读写分离(网上找到就拿来用了) mysql的读写分离 上面说的数据库同步复制,都是在从同一种数据库中,如果我要把oracle的数据同步到mysql中,其实要实现这种方案的理由很简单,mysql免费,oracle太贵。好像Quest SharePlex也实现不了改功能吧。好像现在市面还没有这个工具吧。那样应该怎么实现数据同步?
Spring2连接多数据库,实现读写分离
Spring2连接多数据库,实现读写分离 Spring2.0.1以后的版本已经支持配置多数据源,并且可以在运行的时候动态加载不同的数据源。通过继承AbstractRoutingDataSource就可以实现多数据源的动态转换。目前做的项目就是需要访问2个数据源,每个数据源的表结构都是相同的,所以要求数据源的变动对于编码人员来说是透明,也就是说同样SQL语句在不同的环境下操作的数据库是不一样的。具体的流程如下: 一、建立一个获得和设置上下文的类 package com.lvye.base.dao.impl.jdbc; /**连接哪个数据源的环境变量 * @author wenc */ public class JdbcContextHolder { private static final ThreadLocal 数据库大型应用解决方 案 随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的互联网应用,每天百万级甚至上亿的PV无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。 [@more@] 一、负载均衡技术 负载均衡集群是由一组相互独立的计算机系统构成,通过常规网络或专用网络进行连接,由路由器衔接在一起,各节点相互协作、共同负载、均衡压力,对客户端来说,整个群集可以视为一台具有超高性能的独立服务器。 1、实现原理 实现数据库的负载均衡技术,首先要有一个可以控制连接数据库的控制端。在这里,它截断了数据库和程序的直接连接,由所有的程序来访问这个中间层,然后再由中间层来访问数据库。这样,我们就可以具体控制访问某个数据库了,然后还可以根据数据库的当前负载采取有效的均衡策略,来调整每次连接到哪个数据库。 2、实现多据库数据同步 对于负载均衡,最重要的就是所有服务器的数据都是实时同步的。这是一个集群所必需的,因为,如果数不据实时、不同步,那么用户从一台服务器读出的数据,就有别于从另一台服务器读出的数据,这是不能允许的。所以必须实现数据库的数据同步。这样,在查询的时候就可以有多个资源,实现均衡。比较常用的方法是 Moebius for SQL Server集群,Moebius for SQL Server集群采用将核心程序驻留在每个机器的数据库中的办法,这个核心程序称为Moebius for SQL Server 中间件,主要作用是监测数据库内数据的变化并将变化的数据同步到其他数据库中。数据同步完成后客户端才会得到响应,同步过程是并发完成的,所以同步到多个数据库和同步到一个数据库的时间基本相等;另外同步的过程是在事务的环境下完成的,保证了多份数据在任何时刻数据的一致性。正因为Moebius 中间件宿主在数据库中的创新,让中间件不但能知道数据的变化,而且知道引起数据变化的SQL语句,根据SQL语句的类型智能的采取不同的数据同步的策略以保证数据同步成本的最小化。 答案见参考下列黄色标记 一、下面所有题目中包括单选或多选 1.若MySQL Server运行在Linux系统上,那访问MySQL服务器的客 户端程序也必须运行在Linux系统吗? A.是 B. 否 2.MySQL与其他关系型数据库(SQL Server/Oracle)架构上最大的区别 是? A.连接层 B. SQL层 C.存储引擎层 3.MySQL使用磁盘空间来存储下面哪些信息? A.server和client程序、其他lib库文件 B.日志文件和状态文件 C.数据库 D.表格式(.frm)文件、数据文件、索引文件 E.当内部临时表超过控制设置时,由内存表形式转化为磁盘形式存储 F.上面所有 4.下面哪四种是mysql客户端程序的功能? A.创建、删除数据库 B.创建、删除、修改表和索引 C.使用shutdown命令关闭服务器 D.创建、管理用户 E.显示replication状态信息 F.使用start backup命令来进行数据库二进制备份 5.在MySQL内部有4种常见日志,哪种日志是不能直接cat或more 文本查阅日志内容? A.错误日志(error-log) B.二进制日志(bin-log) C.查询日志(query-log) D.慢查询日志(slow-log) 6.下面哪三种方式可以查看Country表的存储引擎? A.SHOW CREATE TABLE Country; B.SHOW ENGINE Country STATUS;; C.SHOW TABLE STATUS LIKE ‘Country’; D.SELECT ENGINE FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME=’Country’; E.SELECT ENGINE FROM INFORMATION_SCHEMA.ENGINES WHERE TABLE_NAME =’County’; 7.在高并发、事务等场景下,MySQL5.6数据库默认使用哪种存储引 XXXXXXXXXXXX平台数据库升级方案 XXXXXXXXXXXXXXX有限公司 日28月11年2016. 修订记录版说作批批准日 2011对升级方案进行编V1.0XXXX 1 目录 1. 概述 (4) 1.1. 背景 (4) 1.2. 目标与目的 (4) 1.3. 可行性分析 (4) 1.4. 参考依据 (5) 2. 数据库高并发方案 (5) 2.1. 数据库均衡负载(RAC) (5) 2.2. 数据库主从部署 (8) 2.3. 数据库垂直分割 (9) 2.4. 数据库水平分割 (10) 3. 二代办公平台数据库优化设计 ........................... 11 3.1. 数据库集群 (11) 3.2. 重点业务表分区 (11) 3.3. 任务表历史数据分割 (12) 3.4. 数据库表结构优化 (12) 3.5. 数据访问优化 (12) 4. 实施方案 (13) 5. 工作量及预算评估 (14) 5.1. 工作量及预算评估 (14) 5.2. 其他费用 (15) 1.概述 1.1.背景 随着XXXXXX平台及其他子系统业务量增多,且用户已面向各地州市,用户数量增大,现有的二代办公平台及其他子系统在单一环境下的架构体系和数据库架构体系也无法高效的满足这样的场景。 当前XXXXXX平台及其子系统通过搭建多台WEB服务器和双机热备份的方式进行部署运行。虽已提高了整体效率,但对于部分的业务处理还是未解决。部分业务量并发处理多,业务关联多等因素,导致对数据库并发处理的业务量大,读写量大等也无法用双机热备份进行解决。 因此,在此背景下提高数据库访问效率,增大访问吞吐量等将成为二代办公平台及其子系统运行顺畅的关键因素。 1.2.目标与目的 目标:依托现有系统服务和设备环境,建立可扩容、高并发、高吞吐量的数据库架构体系。 目的:为缓解当前XXXXXX平台机器及其他子系统对数据库访问过大,造成的访问效率低下的问题,提升数据库访问效率和并发效率。对部分业务繁杂的表和访问进行优化设计,缓解因此造成的使用效率低下问题。 1.3.可行性分析 数据库性能分析:根据当前的数据库性能分析,当前硬件设备的提高也无法满足数据库性能的提升,因此应考虑数据库访问控制和数据访问方面进行优化。现有的数据库虽也实现双机热备份,但访问的效率未较大改善,因此应考虑各健全的数据库高并发访问方案。 数据库优化分析:当前的数据库采用的ORACLE数据库,同时,现有的均衡负载、读写分离、数据分割技术较为成熟,在对系统进行适当调整和优化的情况下,能保证系统的正常运行。. 参考依据1.4. 核心技术详解》《Oracle RAC数据库高并发方案2. (RAC) 2.1.数据库均衡负载Oracle,“实时应用集群”是,RAC全称real application clusters,译为数据库支持Oracle新版数据库中采用的一项新技术,是高可用数据库大型应用解决方案
MySQL练习题及答案
数据库高并发升级方案1讲解
相关文档
- 大数据库读写分离方案设计及对比
- 数据库读写分离解决方案--DG实施方案
- 数据库读写分离解决方案--DG实施方案
- Linux使用Mycat进行数据库的读写分离实例讲解
- ThinkPHP实现读写分离
- 数据库读写分离解决方案--DG实施方案
- 数据库读写分离解决方案--DG实施方案
- 使用Active Data Guard实现Oracle读写分离
- DB2数据库读写分离技术在银行核心系统中的应用
- 数据库读写分离
- Spring2连接多数据库,实现读写分离
- 数据库运维流程(工作流标准)20150721
- 数据库双重负载均衡读写分离及双活集群
- mysql读写分离
- 数据库高并发升级方案1讲解
- Mysql主从复制与读写分离(已成功)
- 分布式数据库拆分表常用的方法
- 配置amoeba实现读写分离
- 读写分离----构建报表和查询系统
- SqlServer实现主从复制读写分离操作说明