openfalcon+grafana安装配置手册及注意事项

Open-falcon安装配置手册
1.open-falcon介绍
监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供翔实的数据用于追查定位问题。监控系统作为一个成熟的运维产品,业界有很多开源的实现可供选择。当公司刚刚起步,业务规模较小,运维团队也刚刚建立的初期,选择一款开源的监控系统,是一个省时省力,效率最高的方案。之后,随着业务规模的持续快速增长,监控的对象也越来越多,越来越复杂,监控系统的使用对象也从最初少数的几个SRE,扩大为更多的DEVS,SRE。这时候,监控系统的容量和用户的“使用效率”成了最为突出的问题。
监控系统业界有很多杰出的开源监控系统。我们在早期,一直在用zabbix,不过随着业务的快速发展,以及互联网公司特有的一些需求,现有的开源的监控系统在性能、扩展性、和用户的使用效率方面,已经无法支撑了。因此,我们在过去的一年里,从互联网公司的一些需求出发,从各位SRE、SA、DEVS的使用经验和反馈出发,结合业界的一些大的互联网公司做监控,用监控的一些思考出发,设计开发了小米的监控系统:open-falcon。
open-falcon的目标是做最开放、最好用的互联网企业级监控产品。
产品特点:
强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟)
高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
dashboard:多维度的数据展示,用户自定义Screen
高可用:整个系统无核心单点,易运维,易部署,可水平扩展
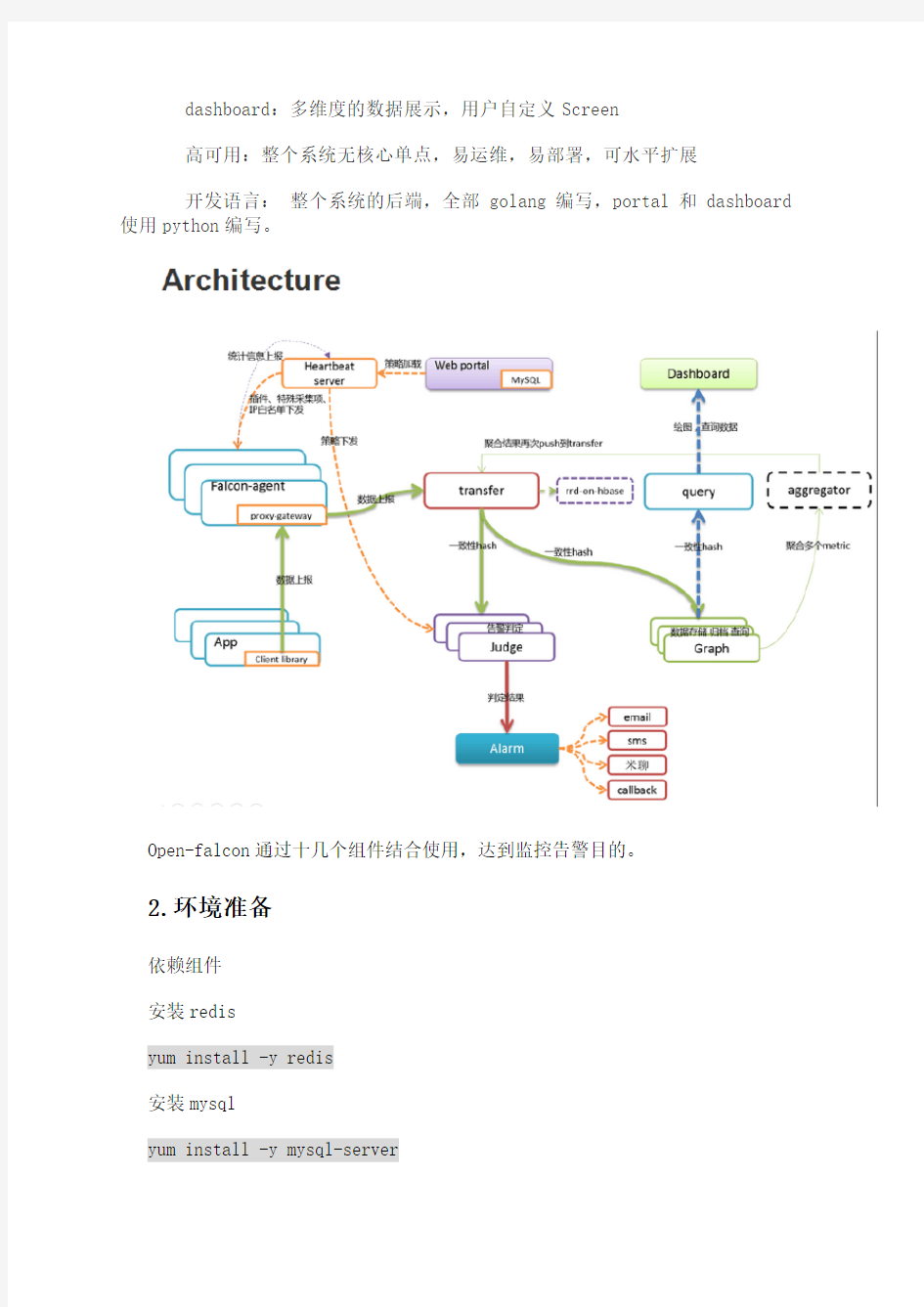
开发语言:整个系统的后端,全部golang编写,portal和dashboard 使用python编写。
Open-falcon通过十几个组件结合使用,达到监控告警目的。
2.环境准备
依赖组件
安装redis
yum install -y redis
安装mysql
yum install -y mysql-server
初始化mysql表结构
# open-falcon所有组件都无需root账号启动,推荐使用普通账号安装,提升安全性。此处我们使用普通账号:work来安装部署所有组件# 当然了,使用yum 安装依赖的一些lib库的时候还是要有root权限的。
export HOME=/home/workexport WORKSPACE=$HOME/open-falcon
mkdir -p $WORKSPACEcd $WORKSPACE
git clone https://https://www.sodocs.net/doc/1618004671.html,/open-falcon/scripts.git
cd ./scripts/
如果我们预备监控windows主机,可先将mysql数据库字符集修改为utf-8,这是由于监控windows主机时,windows主机的网卡信息很可能有中文。
show variables like "%char%";
SET XXXXXX='utf8'
mysql -h localhost -u root -p < db_schema/graph-db-schema.sql
mysql -h localhost -u root -p < db_schema/dashboard-db-schema.sql
mysql -h localhost -u root -p < db_schema/portal-db-schema.sql
mysql -h localhost -u root -p < db_schema/links-db-schema.sql
mysql -h localhost -u root -p < db_schema/uic-db-schema.sql
安装环境
open-falcon的后端组件都是使用Go语言编写的,本节我们搭建Go语言开发环境,clone代码
我们使用64位Linux作为开发环境,与线上环境保持一致。如果你所用的环境不同,请自行解决不同平台的命令差异
首先安装Go语言开发环境(ansible golang环境部署):
cd ~
wget https://www.sodocs.net/doc/1618004671.html,/go1.4.1.linux-amd64.tar.gz
tar zxf go1.4.1.linux-amd64.tar.gz
mkdir -p workspace/srcecho "">> .bashrcecho 'export GOROOT=$HOME/go' >> .bashrcecho 'export GOPATH=$HOME/workspace' >> .bashrcecho 'export PATH=$GOROOT/bin:$GOPATH/bin:$PATH' >> .bashrcecho "">> .bashrcsource .bashrc
接下来clone代码,以备后用
cd $GOPATH/src
mkdir https://www.sodocs.net/doc/1618004671.html,cd https://www.sodocs.net/doc/1618004671.html,
git clone --recursive https://https://www.sodocs.net/doc/1618004671.html,/open-falcon/of-release.git 3.open-falcon安装
解压of-release-v0.1.0.tar.gz获得以下16个压缩包
每个压缩包对应一个组件,创建独立组件目录,将压缩包解压到相应目录即可。
4.组件配置使用
3.1 agent
agent用于采集机器负载监控指标,比如cpu.idle、load.1min、disk.io.util等等,每隔60秒push给Transfer。agent与Transfer建立了长连接,数据发送速度比较快,agent提供了一个http接口/v1/push用于接收用户手工push的一些数据,然后通过长连接迅速转发给Transfer。因此需要被监控的所有主机都需要使用该组件。
配置文件必须叫cfg.json,可以基于cfg.example.json修改
{
"debug": true, # 控制一些debug信息的输出,生产环境通常设置为false
"hostname": "", # agent采集了数据发给transfer,endpoint就设置为了hostname,默认通过`hostname`获取,如果配置中配置了hostname,就用配置中的
"ip": "", # agent与hbs心跳的时候会把自己的ip地址发给hbs,agent会自动探测本机ip,如果不想让agent自动探测,可以手工修改该配置
"plugin": {
"enabled": false, # 默认不开启插件机制
"dir": "./plugin", # 把放置插件脚本的git repo clone到这个目录
"git": "https://https://www.sodocs.net/doc/1618004671.html,/open-falcon/plugin.git", # 放置插件脚本的git repo地址
"logs": "./logs" # 插件执行的log,如果插件执行有问题,可以去这个目录看log
},
"heartbeat": {
"enabled": true, # 此处enabled要设置为true
"addr": "127.0.0.1:6030", # hbs的地址,端口是hbs的rpc端口
"interval": 60, # 心跳周期,单位是秒
"timeout": 1000 # 连接hbs的超时时间,单位是毫秒
},
"transfer": {
"enabled": true, # 此处enabled要设置为true
"addrs": [
"127.0.0.1:8433",
"127.0.0.1:8433"
], # transfer的地址,端口是transfer的rpc端口, 可以支持写多个transfer的地址,agent会保证HA
"interval": 60, # 采集周期,单位是秒,即agent一分钟采集一次数据发给transfer
"timeout": 1000 # 连接transfer的超时时间,单位是毫秒
},
"http": {
"enabled": true, # 是否要监听http端口
"listen": ":1988" # 如果监听的话,监听的地址
},
"collector": {
"ifacePrefix": ["eth", "em"] # 默认配置只会采集网卡名称前缀是eth、em 的网卡流量,配置为空就会采集所有的,lo的也会采集。可以从/proc/net/dev 看到各个网卡的流量信息
},
"ignore": { # 默认采集了200多个metric,可以通过ignore设置为不采集
"cpu.busy": true,
"mem.swapfree": true
}
}
进程管理
./control start 启动进程
./control stop 停止进程
./control restart 重启进程
./control status 查看进程状态
./control tail 用tail -f的方式查看var/app.log
验证
看var目录下的log是否正常,或者浏览器访问其1988端口。另外agent提供了一个--check参数,可以检查agent是否可以正常跑在当前机器上
./falcon-agent --check
/v1/push接口
我们设计初衷是不希望用户直接连到Transfer发送数据,而是通过agent的/v1/push接口转发,接口使用范例:
ts=`date +%s`; curl -X POST -d "[{\"metric\": \"metric.demo\", \"endpoint\": \"qd-open-falcon-judge01.hd\", \"timestamp\":
$ts,\"step\": 60,\"value\": 9,\"counterType\": \"GAUGE\",\"tags\": \"project=falcon,module=judge\"}]" http://127.0.0.1:1988/v1/push
3.2 transfer
transfer是数据转发服务。它接收agent上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别push给graph&judge等组件。
# 校验服务,这里假定服务开启了6060的http监听端口。检验结果为ok表明服务正常启动。
curl -s "127.0.0.1:6060/health"
服务启动后,可以通过日志查看服务的运行状态,日志文件地址为./var/app.log。可以通过调试脚本./test/debug查看服务器的内部状态数据,如运行bash ./test/debug 可以得到服务器内部状态的统计信息。Configuration
debug: true/false, 如果为true,日志中会打印debug信息
http
- enable: true/false, 表示是否开启该http端口,该端口为控制端口,主要用来对transfer发送控制命令、统计命令、debug命令等
- listen: 表示监听的http端口
rpc
- enable: true/false, 表示是否开启该jsonrpc数据接收端口, Agent发送数据使用的就是该端口
- listen: 表示监听的http端口
socket #即将被废弃,请避免使用
- enable: true/false, 表示是否开启该telnet方式的数据接收端口,这是为了方便用户一行行的发送数据给transfer
- listen: 表示监听的http端口
judge
- enable: true/false, 表示是否开启向judge发送数据
- batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值
- connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
- callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
- pingMethod: 后端提供的ping接口,用来探测连接是否可用,必须保持默认
- maxConns: 连接池相关配置,最大连接数,建议保持默认
- maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
- replicas: 这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可
- cluster: key-value形式的字典,表示后端的judge列表,其中key代表后端judge名字,value代表的是具体的ip:port
graph
- enable: true/false, 表示是否开启向graph发送数据
- batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值
- connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
- callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
- pingMethod: 后端提供的ping接口,用来探测连接是否可用,必须保持默认
- maxConns: 连接池相关配置,最大连接数,建议保持默认
- maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
- replicas: 这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可
- cluster: key-value形式的字典,表示后端的graph列表,其中key代表后端graph名字,value代表的是具体的ip:port(多个地址用逗号隔开, transfer会将同一份数据发送至各个地址,利用这个特性可以实现数据的多重备份)
tsdb
- enabled: true/false, 表示是否开启向open tsdb发送数据
- batch: 数据转发的批量大小,可以加快发送速度
- connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认
- callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认
- maxConns: 连接池相关配置,最大连接数,建议保持默认
- maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认
- retry: 连接后端的重试次数和发送数据的重试次数
- address: tsdb地址或者tsdb集群vip地址, 通过tcp连接tsdb.
3.3 Graph
graph是存储绘图数据的组件。graph组件接收transfer组件推送上来的监控数据,同时处理query组件的查询请求、返回绘图数据。
# 校验服务,这里假定服务开启了6071的http监听端口。检验结果为ok表明服务正常启动。
curl -s "127.0.0.1:6071/health"
启动服务后,可以通过日志查看服务的运行状态,日志文件地址为./var/app.log;如果需要详细的日志,可以将配置项debug设置为true。可以通过调试脚本./test/debug查看服务器的内部状态数据,如运行bash ./test/debug 可以得到服务器内部状态的统计信息。
配置说明
{
"debug": false, //true or false, 是否开启debug日志
"http": {
"enabled": true, //true or false, 表示是否开启该http端口,该端口为控制端口,主要用来对graph发送控制命令、统计命令、debug命令
"listen": "0.0.0.0:6071" //表示监听的http端口
},
"rpc": {
"enabled": true, //true or false, 表示是否开启该rpc端口,该端口为数据接收端口
"listen": "0.0.0.0:6070" //表示监听的rpc端口
},
"rrd": {
"storage": "/home/work/data/6070" //绝对路径,历史数据的文件存储路径(如有必要,请修改为合适的路)
},
"db": {
"dsn": "root:@tcp(127.0.0.1:3306)/graph?loc=Local&parseTime=true", //MySQL的连接信息,默认用户名是root,密码为空,host为127.0.0.1,
database为graph(如有必要,请修改),如果需要密码,在root:后跟密码
"maxIdle": 4 //MySQL连接池配置,连接池允许的最大连接数,保持默认即可
},
"callTimeout": 5000, //RPC调用超时时间,单位ms
"migrate": { //扩容graph时历史数据自动迁移
"enabled": false, //true or false, 表示graph是否处于数据迁移状态"concurrency": 2, //数据迁移时的并发连接数,建议保持默认
"replicas": 500, //这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可(必须和transfer的配置中保持一致)
"cluster": { //未扩容前老的graph实例列表
"graph-00" : "127.0.0.1:6070"
}
}
}
3.4 query
query组件,提供统一的绘图数据查询入口。query组件接收查询请求,根据一致性哈希算法去相应的graph实例查询不同metric的数据,然后汇总拿到的数据,最后统一返回给用户。
# 校验服务,这里假定服务开启了9966的http监听端口。检验结果为ok表明服务正常启动。
curl -s "127.0.0.1:9966/health"
服务启动后,可以通过日志查看服务的运行状态,日志文件地址为./var/app.log。可以通过查询脚本./scripts/query读取绘图数据,如运行bash ./scripts/query "ur.endpoint""ur.counter"可以查询Endpoint="ur.endpoint"& Counter="ur.counter"对应的绘图数据。
配置说明
注意: 请确保graph.replicas和graph.cluster的内容与transfer的配置完全一致
{
"debug": "false", // 是否开启debug日志
"http": {
"enabled": true, // 是否开启http.server
"listen": "0.0.0.0:9966" // http.server监听地址&端口
},
"graph": {
"connTimeout": 1000, // 单位是毫秒,与后端graph建立连接的超时时间,可以根据网络质量微调,建议保持默认
"callTimeout": 5000, // 单位是毫秒,从后端graph读取数据的超时时间,可以根据网络质量微调,建议保持默认
"maxConns": 32, // 连接池相关配置,最大连接数,建议保持默认
"maxIdle": 32, // 连接池相关配置,最大空闲连接数,建议保持默认
"replicas": 500, // 这是一致性hash算法需要的节点副本数量,应该与transfer配置保持一致
"cluster": { // 后端的graph列表,应该与transfer配置保持一致;不支持一条记录中配置两个地址
"graph-00": "test.hostname01:6070",
"graph-01": "test.hostname02:6070"
},
"api": { // 适配grafana需要的API配置
"query": "http://127.0.0.1:9966", // query的http地址
"dashboard": "http://127.0.0.1:8081", // dashboard的http地址
"max": 500 //API返回结果的最大数量
}
}
}
部署完成query组件后,请修改dashboard组件的配置、使其能够正确寻址到query组件。请确保query组件的graph列表与 transfer的配置一致。
3.5 dashboard
dashboard是面向用户的查询界面。在这里,用户可以看到push到graph 中的所有数据,并查看其趋势图。
Dashboard是个Python的项目。安装&部署Dashboard时,需要安装一些依赖库。依赖库安装,步骤如下,
# 安装virtualenv。需要root权限。
yum install -y python-virtualenv
安装pip1.2.1,否则Python3.1以下版本会出现ssl验证错误。
easy_install pip==1.2.1
# 安装依赖。不需要root权限、使用普通账号执行就可以。需要到dashboard的目录下执行。
****************yum install mysql-devel
cd /path/to/dashboard/
virtualenv ./env
./env/bin/pip install -r pip_requirements.txt
对于ubuntu用户,安装mysql-python时可能会失败。请自行安装依赖libmysqld-dev、libmysqlclient-dev等。
服务启动后,可以通过日志查看服务的运行状态,日志文件地址
为./var/app.log。可以通过http://localhost:8081访问dashboard主页(这里假设 dashboard的http监听端口为8081)。
配置说明
dashboard有两个需要更改的配置文件: ./gunicorn.conf
和 ./rrd/config.py。./gunicorn.conf各字段,含义如下
- workers,dashboard并发进程数
- bind,dashboard的http监听端口
- proc_name,进程名称
- pidfile,pid文件全名称
- limit_request_field_size,TODO
- limit_request_line,TODO
配置文件./rrd/config.py,各字段含义为
# dashboard的数据库配置
DASHBOARD_DB_HOST = "127.0.0.1"
DASHBOARD_DB_PORT = 3306
DASHBOARD_DB_USER = "root"
DASHBOARD_DB_PASSWD = ""
DASHBOARD_DB_NAME = "dashboard"
# graph的数据库配置
GRAPH_DB_HOST = "127.0.0.1"
GRAPH_DB_PORT = 3306
GRAPH_DB_USER = "root"
GRAPH_DB_PASSWD = ""
GRAPH_DB_NAME = "graph"
# dashboard的配置
DEBUG = True
SECRET_KEY = "secret-key"
SESSION_COOKIE_NAME = "open-falcon"
PERMANENT_SESSION_LIFETIME = 3600 * 24 * 30
SITE_COOKIE = "open-falcon-ck"
# query服务的地址
QUERY_ADDR = "http://127.0.0.1:9966"
BASE_DIR = "/home/work/open-falcon/dashboard/"
LOG_PATH = os.path.join(BASE_DIR,"log/")
try:
from rrd.local_config import *except:
pass
3.6 短信发送接口(接口定义,无需安装)
这个组件没有代码,需要各个公司自行提供。
监控系统产生报警事件之后需要发送报警邮件或者报警短信,各个公司可能有自己的邮件服务器,有自己的邮件发送方法;有自己的短信通道,有自己的短信发送方法。falcon为了适配各个公司,在接入方案上做了一个规范,需要各公司提供http的短信和邮件发送接口
短信发送http接口:
method: post
params:
- content: 短信内容
- tos: 使用逗号分隔的多个手机号
邮件发送http接口:
method: post
params:
- content: 邮件内容
- subject: 邮件标题
- tos: 使用逗号分隔的多个邮件地址
3.7 sender
上节我们利用http接口规范屏蔽了邮件、短信发送的问题。Sender这个模块专门用于调用各公司提供的邮件、短信发送接口。
sender这个模块和redis队列部署在一台机器上即可。公司即使有几十万台机器,一个sender也足够了。
配置说明
{
"debug": true,
"http": {
"enabled": true,
"listen": "0.0.0.0:6066"
},
"redis": {
"addr": "127.0.0.1:6379", # 此处配置的redis地址要和后面的judge、alarm配置成相同的
"maxIdle": 5
},
"queue": {
"sms": "/sms", # 短信队列名称,维持默认即可,alarm中也会有一个相同的配置
"mail": "/mail" # 邮件队列名称,维持默认即可,alarm中也会有一个相同的配置
},
"worker": {
"sms": 10, # 调用短信接口的最大并发量
"mail": 50 # 调用邮件接口的最大并发量
},
"api": {
"sms": "http://11.11.11.11:8000/sms", # 各公司自行提供的短信发送接口,11.11.11.11这个ip只是个例子喽,如果未提供相应接口可删除该项
"mail": "http://11.11.11.11:9000/mail" # 各公司自行提供的邮件发送接口
}
}
如果没有邮件发送接口,可以使用 Open-Falcon mail-provider。
sender的配置文件中配置了监听的http端口,我们可以访问一下/health
接口看是否返回ok,我们所有的Go后端模块都提供了/health接口,上面的
配置的话就是这样验证:
curl 127.0.0.1:6066/health
另外就是查看sender的log,log在var目录下
3.7.1 mail-provider
{
"debug": true,
"http": {
"listen": "0.0.0.0:4000",
"token": ""
},
"smtp": {
"addr": "https://www.sodocs.net/doc/1618004671.html,:25",#发件服务器地址
"username": "113169666@https://www.sodocs.net/doc/1618004671.html,",#发件箱用户
"password": "XXXX",#发件用户密码
"from": "113169666@https://www.sodocs.net/doc/1618004671.html,"#此处表面邮件来源,来件地址必须与发件服务器地址一致,如此处都为@163
}
}
配置启动mail-provider后,可使用如下命令测试是否能正常发送
curl http://127.0.0.1:4000/sender/mail -d
"tos=XXX@https://www.sodocs.net/doc/1618004671.html,&subject=thisismytestmail&content=helloWo rld"
该命令向qq邮箱发送了一个测试邮件,成功后邮箱中会收到该邮件:
注:不同的邮箱由于对邮件设置的安全过滤情况不同,可能导致测试邮件有收取不到的情况,如使用搜狐邮箱测试时,提示success,但是仍然收不到邮件。163做接收邮箱时,会报错,提示该邮件为垃圾邮件之类的(隔天还邮件提醒安全隐患。。。)
注意:测试成功后需要修改sender的邮件发送接口,接口地址改为:
"mail": "http://127.0.0.1:4000/sender/mail"
3.8 web前端(Fe)
这是Go版本的UIC,也是一个统一的web入口,因为监控组件众多,记忆
ip、port去访问还是比较麻烦。fe像是一个监控的hao123.
与UIC区别
Fe模块除了提供了一个简单的导航之外,最大的不同是密码存放方式发生了变化,所以Java版UIC用户如果要迁移过来,需要修改Fe模块配置的salt,配置为空字符串,就可以和原来Java版本的UIC共用同一个数据库了,不过配置成空字符串不够安全,建议salt配置一个随机字符串,然后通过Fe注册一个新用户,把数据库中所有用户的密码都重置为这个新用户的密码,发个通知,让各个注册用户重新自己登录修改密码。
Fe作为一个前端模块,无状态,可以水平扩展,至少部署两台机器以保证可用性。前面做一个负载均衡设备,nginx或者lvs都可以。最后为其申请一个域名,搞定!
配置介绍
{
"log": "debug",
"company": "MI", # 填写自己公司的名称,用于生成联系人二维码
"http": {
"enabled": true,
"listen": "0.0.0.0:1234" # 自己随便搞个端口,别跟现有的重复了,可以使用8080,与老版本保持一致
},
"cache": {
"enabled": true,
"redis": "127.0.0.1:6379", # 这个redis跟judge、alarm用的redis不同,这个只是作为缓存来用
"idle": 10,
"max": 1000,
"timeout": {
"conn": 10000,
"read": 5000,
"write": 5000
}
},
"salt": "0i923fejfd3", # 搞一个随机字符串
"canRegister": true,
"ldap": {
"enabled": false,
"addr": "https://www.sodocs.net/doc/1618004671.html,:389",
"baseDN": "dc=example,dc=com",
"bindDN": "cn=mananger,dc=example,dc=com",
"bindPasswd": "12345678",
"userField": "uid",
"attributes": ["sn","mail","telephoneNumber"]
},
"uic": {
"addr":
"root:password@tcp(127.0.0.1:3306)/uic?charset=utf8&loc=Asia%2FChon gqing", # 数据库schema在scripts目录下
"idle": 10,
"max": 100
},
"shortcut": {
"falconPortal": "http://11.11.11.11:5050/", # 浏览器可访问的portal 地址
"falconDashboard": "http://11.11.11.11:7070/", # 浏览器可访问的dashboard地址
"falconAlarm": "http://11.11.11.11:9912/" # 浏览器可访问的alarm的http地址
}
}
注意:shortcut中设置的地址,按实际配置成内/外网访问地址。内网ip:port 或者外网ip:port
设置root账户密码
该项目中的注册用户是有不同角色的,目前分三种角色:普通用户、管理
员、root账号。系统启动之后第一件事情应该是设置root的密码,浏览器访
问:https://www.sodocs.net/doc/1618004671.html,/root?password=abc (此处假设你的项目访问
地址是https://www.sodocs.net/doc/1618004671.html,,也可以使用ip),这样就设置了root账号的密码为abc。普通用户可以支持注册。
然后通过访问fe即可使用root登录(也可注册新用户),
ldap 认证
Fe 现在支持通过 ldap 来进行用户认证。不需要提前在 Fe 内开设账号。Fe 会自动将 ldap 认证过来的新用户插入到 Fe 的数据库内。
配置说明
"addr": "https://www.sodocs.net/doc/1618004671.html,:389",
# ldap 的地址和端口
"baseDN": "dc=example,dc=com",
# ldap 的 baseDN,ldap 认证的时候将从这个路径开始查询用户
"bindDN": "cn=mananger,dc=example,dc=com",
# 你用来连接 ldap 的账户,至少要有只读的查询权限。
# 注意这里应该是账户的完整 dn 值。对于 AD 的话,则可以直接填账户的 userPrincipalName (xxx@https://www.sodocs.net/doc/1618004671.html,)。
# 如果你的 ldap 允许匿名查询的话,填""值即可
"bindPasswd": "12345678",
# 如果你的 ldap 允许匿名查询的话,填""值即可
"userField": "uid",
# 用于认证的属性(即你输入的用户名),通常为 uid 或sAMAccountName(AD)。